lmgrep:基于卢诺的Grep型实用程序
如果Grep支持像Elasticsearch这样的适当搜索引擎的功能,而无需在搜索之前安装任何服务器或索引文件? LmgRep旨在为您提供。它只是只安装了一个没有任何依赖项的可执行文件,提供命令行界面,即时启动,并在麦斯卡斯,Linux上工作,甚至是Windows。
您是否曾希望获得Grep支持的令牌化,令人遗憾的等,因此您无需一直在写通配符?我还在一个愉快的日子里分享了这个问题,我试图通过将Lucene查询语法作为CLI实用程序揭示瘙痒。 LMGEP是我努力的结果。试一试,让我知道它是怎么回事。
我完全意识到比较Lucene和Grep就像将苹果与橘子的比较一样。但是,我认为与激励它的工具相比,Lmgrep最好,即Grep。
无论如何,Grep做了什么? Grep读取STDIN的一行,检查该行以查看它是否应该转发到STDOUT,并重复直到STDIN耗尽1. LMGREP尝试完全模仿该功能。当然,Grep还有更多选项,但这是工具的本质。
Lucene是一个提供索引和搜索功能的Java库。 Lucene在发展中已经超过了20年的发展,并且是赋予许多搜索应用程序的图书馆。此外,许多开发人员已经熟悉了Lucene查询语法,并且知道如何利用它来解决复杂的信息检索问题。
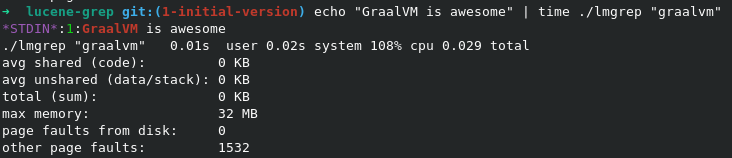
然而,强大的lucene是,它不适合CLI应用。主要问题是JVM的启动时间。要减少启动时间,我将使用Graalvm提供的本机映像工具编译Lmgrep。通过这种方式,启动时间为Linux,MacOS和Windows的0.01s。
lmgrep默认期望两个参数:搜索查询和Glob模式(类似于Regexp),以查找文件以执行Lmgrep On。我假设亲爱的读者通过阅读关于文件名如何与Glob匹配的解释,不希望被折磨,因此我会跳过它。相反,我将专注于解释搜索如何在文件中工作。
Lmgrep从提供的搜索查询创建一个Lucene Monitor(监视器)对象。然后将文本文件拆分为行2.每行文本都传递给监视器以进行搜索。然后,监视器创建内存内存LuceNe索引,其中包含从文本行中创建的单个文档。然后,监视器在良好的OL&#39中运行搜索查询。 Lucene Way 3. Lmgrep采用命中,格式化它们,并将结果发送到STDOUT。这就是LMGREP如何完成全文搜索。
整体搜索方法类似于Elasticsearch中的渗滤器之一。 lmgrep仅限于将存储的搜索查询的数量限制为一个,并将每个文本行视为文档。与过滤器相比的冷却件是Lmgrep提供匹配项的精确偏移,而Elasticsearch在突出显示时不会暴露偏移量。
所描述的程序似乎有点低效。但是,所有行(和文件)的查询解析仅完成一次。此外,由于尤其感谢Lucene的研究人员,搜索本身是有效的,感谢Lucene,并且当尤其是Lucene显示器的PRESECHERS。 Presearcher从搜索查询中提取术语,如果这些术语中的任何一个都不在索引中,则根本不会执行完整查询。当然,许多优化可以是(并且将是)用于Lmgrep,例如批量文件。通常,性能受到Lucene监视器的限制。
文本分析管道怎么样?默认情况下,Lmgrep使用StandardTokenizer授权文本。然后,令牌按以下顺序通过多个令牌过滤器:给出了英国系统的小孩子Filter,AsciifoldingFilter和Snowballfilter。相同的分析管道用于索引和查询。分析管道的所有组件可通过CLI标志配置,请参阅自述文件。但是,令牌过滤器的顺序,截至目前,不可配置。此外,各种滤波器根本不暴露(例如,秒表Filter,或WordDelimiterGraphFilter等)。支持更灵活的分析管道配置遗漏了未来的版本。该工具具有更快的新功能的用户将实现更快;)
几乎每个我工作的NLP项目都有一个名为Dictionary Annotator的组件。此外,绝大多数项目以某种方式使用弹性研究。我越熟悉的是我所拥有的Elasticsearch,我的NLP工作量越多,就会在Elasticsearch内实现它。有一天,我发现了一个名为luwak的工具(一个很酷的名字不是它?)并阅读更多关于它的东西。它有点睁开眼睛:可以使用弹性研究可以实现字典注释器,并且字典条目可以表示为Elasticsearch查询。谢天谢地,Elasticsearch具有隐藏管理临时指标,批处理搜索请求等的所有复杂性的渗滤器。
然后我被给出了一个NLP项目,其中一个要求是使用AWS无法的东西来实现数据分析:Lambda用于文本处理和用于存储的Dynamo DB。当然,其中一个必需的NLP组件是字典注释器。由于Elasticsearch不可用(因为它不是无服务器),我仍然希望继续使用字典条目作为搜索查询,我决定利用Luwak图书馆。来自该项目的经验,比猎犬库出生。 Lmgrep松散地基于比猎犬。
在考虑如何实现LMGREP时,我希望它基于Lucene,因为全文搜索功能。为了提供良好的体验,启动时间必须很小。为了实现它,Lmgrep必须使用Graalvm的本机图像工具编译。我尝试过,但本地图像不支持方法处理Lucene使用。需要更多的黑客攻击。当我发现一个玩具项目时,我很幸运,其中博客搜索在AWS Lambda上由Lucene支持的leune,它由本机映像工具编译。我克隆了repo,mvnw安装,然后将文物包含在依赖关系列表中,并成功地使用本机映像工具编译了lmgrep。
然后最复杂的部分是为不同的操作系统制作可执行的二进制文件。充足的CPU,RAM,VirtualBox与Windows和MacOS虚拟机,我们走了。
我说我有多喜欢试图在Windows上完成的东西吗?一个都没有。如何多个不同(!)命令提示来获取GRAALVM编译可执行文件?现在我知道遭受痛苦并设置GitHub操作管道将要编译二进制文件并将其上传到释放页面。
分析管道不像我想的那样灵活(更新2021-04-24:实施);
为代码搜索量身定制的各种选项(Java示例)为Lmgrep提供Lmgrep的别名;
静态网站搜索,如AWS Lambda,它具有Lmgrep,并在没有提升索引的情况下通过所有文件进行所有文件。
lmgrep抓了我的痒。让它工作很令人兴奋。我希望你也发现它有趣,也许有用。请尝试一下,让我知道如何为您,以及最重要的是有关如何改善Lmgrep的任何反馈欢迎。
没有必要将文本文件拆分为行,它只是mimik如何运行。 ↩︎
当然,描述过于简化,但它足以获得整体想法。 ↩︎