使用system.io.pipelines在c#中的性能助推器
由于我们的行业已接受处理包括容器(读为K8S)或无服务器的生产工作负载的新策略或无服务器(作为服务的函数读取),开发人员没有在生产环境中具有无限制的计算资源的奢侈。那些日子已经消失,可以轻松获取具有许多核心和高内存的大型虚拟机,以进行应用程序部署需求。作为.NET开发人员虽然您使用托管代码而且您依赖GC(垃圾收集器)进行作业,但ONU现在正在编写高度性能的代码,该代码可以从Docker容器到IoT设备的任何位置运行。随着C#8和.NET核心的出现,Microsoft .NET团队一直非常认识到内存分配。每个新版本都配有现代API,可以将应用程序的性能提高到与旧版传统API的旧版。在此博客文章中,我将以3种不同的技术展示文件I / O操作,并将对每个技术进行基准。从基准测试结果,System.io.pipelines在执行和内存分配时都会非常明显。
我们将尝试阅读员工数据的大型CSV文件(具有5个字段的10万条记录)。我相信您必须在您的职业生涯中遇到此挑战,在那里您必须解析大型CSV文件。这一挑战在GC上创造了足够的压力。垃圾收集周围的考虑因素时尤为重要。这是因为垃圾收集占用CPU时间,减少了在实际数据处理上花费的时间。不仅如此,而且每次触发垃圾收集时,都会暂停大部分工作,以便可以评估其余的引用。这可以大大影响处理数据所需的时间量。我为这一挑战选择了三种技术。
使用CSVhelper:这是一个流行的库,用于在.NET生态系统中解析CSV文件。
使用IASyncenumerable:从C#8引入此API,其中可以处理数据流(数据块)而不是整个文件。
使用system.io.pipelines:此API已使用.NET Core 2.1附带,并且由Kestrel,用于ASPNet核心的Web服务器内部用于高性能,以处理从套接字收到的每秒的许多请求。它可以作为Nuget包下载.David福勒,他们将这些API归档为其介绍的优秀帖子。
我的github repo上有此帖子的源代码。 Repo还包括具有基准结果的测试。
进入点公共方法是processFileAsync,它创建了Pipereader类的实例,它读取该数据并转换为缓冲区,这是readonlysequence的数据类型< byte> 。然后将该缓冲区数据传递给Parselines方法作为参考,以及Pipereader的位置,其具有0值,因为它处于开始位置。 Parselines方法尝试使用换行符导航新行作为分隔符。此过程继续到达牵引液位器的最终位置。解析完成后,完成牵引位置直到缓冲器的末端,标记为加工(线号35和43)。
实际数据处理在Parstine方法中的静态类LineParser中进行,在省略CSV文件的标题行之后,它尝试通过查找&#34来捕获每个字段数据值;,"位置,然后尝试使用索引偏移和范围模式使用UTF8编码提取字符串值。每个字段一个接一个地处理,并且由FieldCount变量跟踪。
创建员工类型的ArrayPool。 Arraypool< t>是一个高性能的托管阵列。它是一个带有自定义最大长度的线程安全池。
接下来的事情是调用租金方法,该方法要求您指定缓冲区的最小长度。请记住,租金返回可能比您所要求的更大。
一旦使用它,您只需将其返回到同一个池中。返回方法具有过载,允许您清理缓冲区,因此通过租金后续消费者不会看到以前的消费者的内容。默认情况下,内容不变。
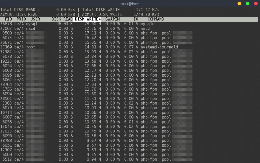
表{边界崩溃:崩溃;显示:块;宽度:100%;溢出:自动; TD,TH {填充:6px 13px;边框:1px solid #ddd;文字对齐:右; } tr {背景 - 颜色:#fff;边界 - 顶部:1px solid #ccc; } TR:nth-child(偶数){背景:#f8f8f8; } BenchmarkDotnet = V0.13.0,OS = MacOS Big Sur 11.4(20F71)[达尔文20.5.0]英特尔酷睿I9-9880H CPU 2.30GHz,1 CPU,16逻辑和8物理核心网= 5.0.203 [主机] :.Net 5.0.6(5.0.621.22011),x64 ryujit defaultjob:.Net 5.0.6(5.0.621.22011),x64 ryujit
由于来自上述Pipelines方法,方法是清晰的赢家,它刚刚拍摄了143.1毫秒来处理数据,只需44 MB的内存分配