我们如何实现每秒1.4米行的写入速度
今天的旅程' s的questdb在2013年开始使用原始原型,我们' Ve描述了在我们的HN去年发布期间发表的帖子以来发生了什么。在项目的可归阶段,我们通过基于矢量的附录 - 唯一的系统,如KDB +,因为速度的优点和简单的代码路径模型带来了。我们还需要将行时间戳存储在升序中,导致快速时间序列查询,没有昂贵的索引。
我们发现此模型不适合所有数据采集用例,如此无序数据。虽然有几种解决方法,但我们希望Top播放此功能,而不会失去我们花费多年建议的性能。
我们研究了现有的方法,大多数人都以威尔伦&#39的表现成本为止。像我们的整个CodeBase一样,Wepresent今天的解决方案是从头开始构建的。到了9个月来才能到弗劳登德添加了一个进一步的65K行代码。
在这里,我们构建了什么,为什么我们建造它,我们沿途所学到的,以及比较QuestDB到涌入的,点击房和时间纪录。
我们的数据模型具有一个致命的缺陷 - 如果通过时间戳出现订购(O3),则丢弃记录,与现有数据相比。在实际应用中,由于网络抖动,延迟或时钟同步问题,有效载荷数据不会像这样。
我们知道缺乏无序的支持是一些用户的展示者,我们需要坚实的解决方案。有可能的解决方法,例如使用每个数据源的ASINGE表或定期重新排序表,但对于最大的人来说,这不方便和不可持续。
当我们审查了我们的数据模型时,一种可能性是从我们已经拥有的内容使用的东西,例如包括LSM树或B树,通常用于时间序列数据库。添加树将带来能够在不使用替代商店从头开始订购数据的福利。
困扰我们最多的方法是,每个后续读取操作都会面临绩效惩罚与存储在数组中的数据。我们不会通过为有序数据的存储模型和另一个无序数据提供复杂性来引入复杂性。
一个更有前途的选择是将一个分类和合并的阶段引入数据到来。这方面,我们可以保持存储型号不变,同时合并在yly上的数据,有序向量作为输出降落在磁盘上。
前两个步骤是简单且易于实现的,并且唯一的难以变化的数据。只有当暂存区域时才会踢重犯罪。这种设计的奖金是输出是向量,这意味着我们的向量基础读者仍然兼容。
此预先提交的排序和合并为伴随性能惩罚添加了额外的处理阶段来摄取额外的处理阶段。尽管如此,我们决定探索这个人,看看我们可以通过优化重新组织来减少惩罚。
处理散装中的分期区域为我们提供了一个全面分析Thedata的独特机会。这种分析旨在避免在可能的地方完全合并的物理合并,也许逃离快速和简单的麦比静脉数据移动方法。由于基于OuRColumn的存储,这种方法可以是并行化的。我们可以采用SIMD和非时间数据访问,其中ITMAKES有所不同。
我们通过Radix排序的优化版本将时间戳列从暂存区域进行排序,结果索引用于重新清除剩余列的分段区域:
从现有分区数据映射了现在排序的临时区域。从一开始可能并不明显,但我们正在尝试建立所需的类型和下面三组中的每一个的尺寸:
以这种方式合并数据集时,前缀和后缀组可以是持久的数据,无序数据或无。 Merge组是在More ShiT出现的情况下,可以通过持久数据,无序数据,无序和批准数据占用。
当它' s清楚如何在暂存区域中进行组和治疗数据时,Wheckers的池执行所需的操作,调用微小案例和筛选到其他一切的SIMD优化代码。使用前缀,合并,和您uffix拆分,提交的最大兴趣(有多易于嘟嘟C的CPU容量)是partitions_affecty x number_of_columns x 3。
因为我们的目标是最依赖Memcpy,我们基准测试了不可享受的代码:
与__memcpy作为愤怒雾' sasmlib a_memcpy,在一个实例和glibc' s另一个。
GLIBC对我们的用例,AVX512可能会缓慢且不一致。 Wespulate an_memcpy确实更好,因为它使用非时间函数标记。
以上是填充具有相同64位模式的内存缓冲器。如果所有字节相同,它可以归类为Memset。它也可以写入倒退的代码,它在Store_nt Vector方法中使用平台特定于特定于平台的_MM ?? _ Stream_PS(p,?mm),如下所示:
结果非常令人惊讶。非TEMP SIMD指令显示最易于的结果与MEMSET类似的性能。
不幸的是,与其他功能的基准结果较少。 Someperform使用手写的SIMD和一些与GCC' SSE4Generated代码一起快速,即使在AVX512系统上运行也是如此。
手写SIMD指令既耗时和冗长。只有在性能优势扩展代码维护时,我们最终通过SIMD求助了代码库的部分。
虽然能够快速复制数据是一个很好的选择,我们认为在大多数时间序列摄取方案中可以避免重型数据贴图。假设最多的实时超出情况是由送货机制和硬件抖动引起的,我们可以推断时间戳分布将由某些边界局部地定位。
例如,如果任何新的时间戳值都有高概率落入先前接收值的10秒内,则边界为10秒,并且我们称之为该边界滞后。
当TimeStamp值遵循此模式时,推迟提交可以陈得不出常规追加操作。无序系统可以达到各种各样的迟到,但如果传入数据在延迟中迟到,则优先考虑更快的处理。
我们看到时间序列基准套件(TSBS)定期在讨论数据库性能和Decidedwe公司应该提供基准与其他系统的QuestDB的能力。
TSB是生成数据集的Go程序的集合,然后是基准录制和写性能。套件是可扩展的,因此可以在系统中包含不同的使用情况和查询类型。
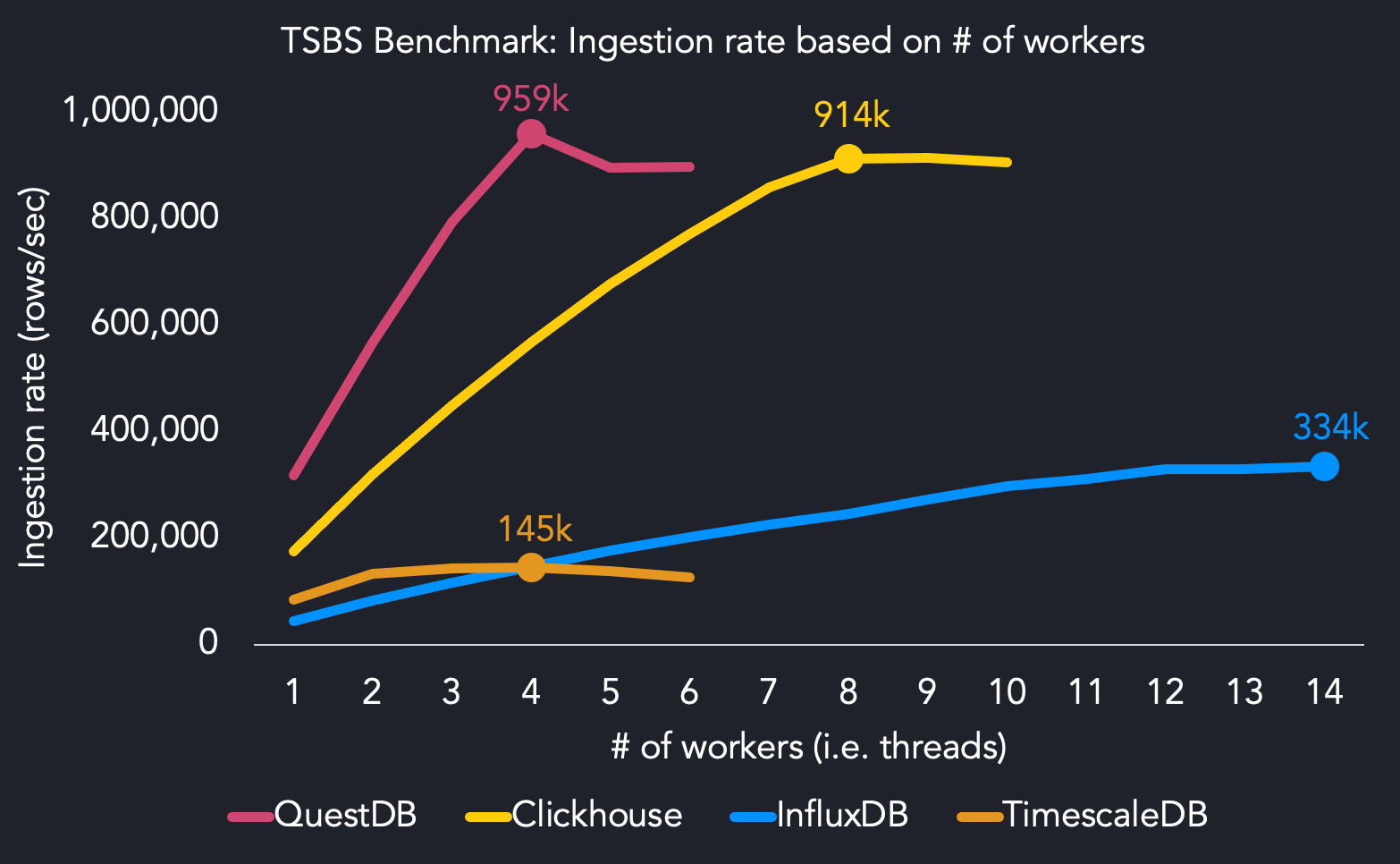
以下是我们的基准测试结果,其中包含ob of of oves ec2 m5.8xlarge实例上的tofourteen工人使用16个核心。
我们使用四个线程达到最大的摄取性能,而其他系统需要更多的CPU资源来达到最大吞吐量。 QuestDB达到了4个线程的959k行/秒。我们发现,涌入量需要14个线程以达到最大摄入率(334k行/秒),而时间尺寸达到145k行/秒4个线程。 Clickhouse击中914k行/秒,其中两个线程asquestdb。
在4个线程上运行时,QuestDB比Clickhouse更快,6.4x更快,6.5倍快,比时间尺寸快。
因为我们的摄入格式(ILP)重复每行标签值,Clickhouse Andtimescaledb在QuestDB的总数据总量中的三分之二左右,因为QuestDB在相同的基准中运行。我们选择坚持ILP,因为它在时间序列中普及,但我们可能会使用更有效的格式来改善未来摄取性能。
最后,超出了4名工人的劣化性能可以通过超出系统的能力增加来解释。我们认为,一个LimitingFactor可能是我们绑定,因为我们在基于FasterAmd的系统上更好地扩展到高达30%。
当我们使用AMD Ryzen5处理器再次运行套件时,我们发现我们可以使用5个线程命中每秒1430万行的最大吞吐量。这与我们在使用中的英特尔Xeon铂金相比我们的参考基准M5。 .8xlarge在AWS上的实例。
我们打开了拉动请求(#157 - QuestDB基准支持)IntimescaledB' S TSBS GitHub存储库,它增加了运行基准制动力QuestDB的能力。与此同时,读者可能会克隆我们的叉形套件,并运行最近的结果,以便自己看到结果。
为了增加无序支持,我们去了一个新的解决方案,它会产生良好的性能,而不是基于B树的良好的方法,如B-Trees orlsm的摄入框架。 我们很高兴共享旅程,以及我们急切地等待社区的反馈。 有关更多详细信息,GitHub版本为6.0版本,此版本中的添加和修复的变更。