衡量隐私 - 如何计算DPIA阈值
公司从人民(他们的用户,员工等)收集数据。其中一些数据可用于追踪(和目标)个人,不可避免地,无论在保护该数据时需要多少护理,都会有事故和违规行为,导致个人信息被损坏,被未经授权销毁或访问(和潜在恶意)缔约方。
这是数据保护法的主要问题(如欧盟或巴西LGPD的GDPR)旨在解决。他们要求公司概述他们为什么收集数据,谁可以访问它,以及如何保护它。他们要求公司澄清向那些要求他们的人提供信息(如果有人要求),并删除此类信息)。对于“高风险”数据处理活动,他们甚至要求公司概述精确概述潜在事件的风险(数据泄漏,纸质档案等),这些事件的后果严重程度(受影响的人以及他们的影响隐私受到损害),并确定他们正在采取适当措施,以减轻这些风险。最后一项要求通常被称为“数据保护影响评估”,DPIA简而言之。
为任何数据处理活动进行DPIA可以是特别令人生畏的任务。这就是为什么法规通常只需要DPIA的“高风险”数据处理活动,但如果公司选择这样,他们也可以进行较低的风险活动以获得进一步的安全性(例如,您可以找到高风险的标准在GDPR中的活动)。然而,这意味着,该公司必须为所有数据处理活动进行“阈值分析”,以确定事实上“高风险”的活动,并且需要具有适当的DPIA。反过来,这种做法通常被称为DPIA阈值分析。
在数据隐私方面计算数据处理活动的风险可能会令人困惑。如果某些特定的数据受到损害,如何计算丢失多少隐私?好吧,事实证明,有很多理论上的工作要回答,这可以用来创造出启发式精确的模型,这不仅仅是有效的,而且甚至可以自动化(大程度)。
如上所述,DPIA阈值分析的目标是找出哪些数据保护活动具有特别高的风险。这种风险可以分为两个主要组成部分:在处理所述个人数据期间出现问题的实际风险以及将会降低数据所涉及的人的潜在伤害,如果出现问题。
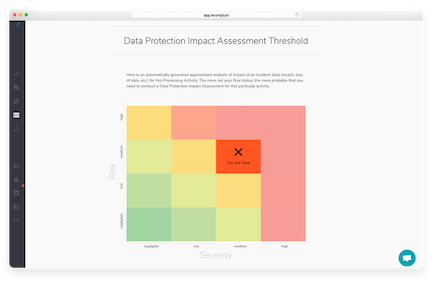
此模型导致如下的图表(这是阈值分析如何在exomply中进行的屏幕截图,其中风险是对事件概率的粗略估计(数据漏洞,被销毁的数据等),并且严重程度是粗糙度估计它是多么糟糕,如果事件发生了。
一些加工活动的整体风险,即事故所造成的预期损害,现在可以估计是上述风险和严重程度的产物:
该估计大致对应于阈值表的颜色编码。表格中的红色越红,加工活动的预期损坏越高,这意味着适当的DPIA评估更可能是必要的。注意,由于实际和法律的原因,这对应的原因并不准确:例如,如果事件的严重程度是高的,那么即使在风险可忽略不计的情况下,您会更好地调查该过程,虽然不是很多如果发生事件,人们可能会受到影响,对那些人来说,反响将严重。
该模型允许我们分解估计潜在隐私损失的问题,以两个更简单的问题:危险的过程有多少钱,即可能有可能在一个过程中,这种事件的损害有多糟糕。虽然每个问题确实具有自己的细微差别和复杂性,但是如果要准确计算相应的因素,但为它们提供粗略的估计是更容易的,这又打开了可以充当自动阈值DPIA分析的门。良好的基线,但在角落案例中需要手动修改。
虽然精确分析了处理数据的事件的概率可能是艰难的(你可以精确地估计被黑客入侵的可能性,或者泄露一些数据库的失语员工,例如?),用于基线阈值分析的目的是粗略估计,实际上并不困难。这里的关键因素是在组织节点(团队,部门,外部供应商等)上发生的事件,该事件参与处理数据,因此可以计算事件的总体概率作为事件发生在每个此类节点的风险的组合。
在每个组织节点发生事件的风险是基于其自身的数据保护实践和措施的不同,但是对于粗糙的基线估计,我们可以采用基于不同类型的组织节点的相同风险因素。例如,我们可以假设平均而言,组织内部部门事件的风险约为2%,事件发生在外部数据处理器的风险约为5%。通过简化,我们可以通过简单地考虑所涉及的内部部门数量和外部供应商的数量来快速获得对处理活动事件的风险的基线估计。通过这种简单级别,我们可以通过查看处理活动的指定数据流动自动填补基线风险评估,这是这种自动评估在Ecomploy.io中的事实上。
请注意,这仅仅是基线估计,通过考虑特定组织节点的更多个性的危险因素,可以进一步提高:例如,可以为在数据保护实践中没有可信的曲目记录的外部供应商假设更高的风险因素。
数据事件的严重程度可以被认为是个人数据涉及受事件影响的数据处理活动的个人隐私的预期损失。
虽然隐私丧失可能是一种摘要,但是一个无法妥善衡量的主观概念,实际上有一个正确开发的数学框架,也为隐私损失提供了精确的数学定义。该框架称为差分隐私,是为数据或至少一些汇总的情况开发的,需要公开发布(例如,统计调查或人口普查数据)。在这个框架中,您可以考虑隐私损失,因为如何使用泄露或发布的数据来确定个人的确定:例如,如果泄露的数据包括邮政编码和年龄,则隐私损失是基于有多少人居住的人邮政编码的年龄是相同的,如果只有一个人在特定的邮政编码中生活,那么随着该数据被公开可用,那个人的隐私完全丧失。您可以在这里或此处了解有关差异隐私的更多信息。
既然我们有一个客观,可衡量的隐私损失定义,我们还可以制定一个启发式,以便在事件发生的情况下获得隐私损失的基线估计。我们可以根据在处理活动中收集和处理的各种类型的个人数据来归因于处理活动中的各种个人数据的灵敏度因子,基于它们的精确识别特定人员,以及合法地认为敏感信息。例如,GPS数据或护照ID具有很高的灵敏度,因为它们可以促进针对个人的针尖指向,并且有关参与工会的犯罪记录或信息的信息具有很高的敏感性,因为它们具有很高的虐待潜力,如果他们与个人有关通过其他泄露的数据(通常是这种情况并称为链接攻击)。
此外,通过使用基于数据处理器与个人的关系的关系,可以通过使用缩放因子进一步上下地构造这种隐私损失近似。例如,患者的数据需要比员工的数据更敏感的处理,这反过来需要比经理数据更多的灵敏度。
利用这种启发式方法允许我们通过考虑处理的数据类型以及数据处理器和正在处理的各个的关系来自动计算基线严重性组。将其与风险的自动基线估计相结合,我们可以(实际上,在explusly,Do)根据每个处理活动记录的其他数据,自动进行DPIA阈值评估。不用说这些估计再次仅仅是通过考虑每个处理活动的细微差别和细节可以改善的基线。
通过这些启发式方法和粗略的估计,我们现在可以大致衡量我们影响客户的隐私,员工,合作伙伴等,而无需大量的工作即可了解我们需要进一步关注哪些流程和哪个没有。这些自动估计,如可能的是粗糙,确实充当了创建大图片的正确基线:他们无缝地概述了数据保护团队需要进一步关注的地方,这使我们能够更快地行动覆盖数据中的空白保护努力和措施,理想情况下导致隐私为企业有效和无痛的方式维护了一个环境。