利用编程语言的内存模型
By Kragen Javier Sideation.last更新了2016年。内存大约有六个主要概念化,我称之为“Memory Models”²,DominateToday的编程。其中三个来自20世纪50年代 - COBOL,LISP和FORTRAN的三个MostPistorical的编程语言 - 另外三个来自三个重要的数据存储系统:磁带,UNIX-Settere文件系统和关系数据库。
这些型号塑造了我们的编程语言可以或不能做的ata更深入的层,而不是mere语法甚至型系统。无论如何都可以看到它们的一个很好的解释 - 你几乎只会通过渗透而不是让他们解释它们而不是让他们解释为你 - 我现在要尝试一下。然后我将向主流选择解释一些可能性,为什么他们可能是有趣的。
每一个现代编程环境都在某种程度上处理所有六个这些记忆映射,这是我们系统是SoCPLICATION和难以理解的一个原因。
在这里,我分析了这些内存模型中的每一个代表实体的属性,②与DataSerialization的交互,③执行,④支持通过将其访问到程序的一小部分(制造“本地”或“私人”的一小部分来解耦您的一方面“)。
让我们从一个简单的编程语言开始,没有能力的Tostructure数据,因为它没有封闭,没有数据类型,其他有限精度数字和布尔值。这是BNF定义,应该或多或少地满足,或多或少地具有常见的方法,以及通常的优先级,而不是由TheGramMar暗示:
程序:: = def * def :: =" def"姓名"(" args")" Blockargs :: ="" |名称"," argsblock :: =" {"声明*"}"声明:: ="返回" exp&#34 ;;" |名称":=" exp&#34 ;;" | exp&#34 ;;" | Nestnest :: ="如果" exp block | "如果" Exp Block" else"块| "" exp blockexp :: = name | num | Exp Op Exp | Exp"(" Exps")" | "(" exp")" | Unop Expexps :: ="" | Exp"," Expsunop :: ="!" | " - " | "〜" op :: =逻辑|比较| " +" | " *" | " - " | " /" | "%"逻辑:: =" ||" | "&" | "&" | " |" | " ^" | "< 34; | ">>"比较:: =" ==" | "< 34; | ">" | "<" | "> =" | "!="
def f2c(f){返回(f - 32)* 5/9; } def main(){say(f2c(-40));说(F2C(32));说(F2C(98.6));说(F2C(212)); }
让我们声明递归非法,使语言eAlsCall-utale,如大多数编程语言,并使调用子例程时,使所有variables隐含地only-初始化零初始化,因此没有子程序可以有任何sideeffect.in此表单,此表单,此表单语言只足以推翻有限状态机。您可以将其编译到电路中。(不是理论上计算机 - 科学电路,它只是一个booleanexpression dag;一个实际的物理电路,它可以合并到registers。)在程序的文本中发生的每个变量都可以被列入单个寄存器,每个子程序可以为其返回地址分配ISGister,并且您需要一个寄存器的程序计数器。如果您在此LibualOn中运行具有千兆字节的机器的程序,您将不好;它将能够使用更多的变量而不是它开始的变量。
这不会使语言无用;有很多有用的卡扣可以在有限空间中完成。但即使对于这些计算,它也真的限制了抽象力量。
您可以使用PEEK()和POKE()函数与您访问该内存的语言 - 读取和编写单个字节ATA给定数值地址。你确实可以这样使用记忆:
def strcpy(d,s,n){虽然n> 0 {Poke(D + N,Peek(S + N)); n:= n - 1; }}
而且更多或多或少的设施机器代码及索地。然而,大多数编程语言都不会停止在那里,并且infact其中许多人甚至不提供peek()和poke()。相反,它们在禁止的奥斯特雷统称的字节上提供某种结构。
例如,即使在仅限编程的限制范围内,嵌套记录,阵列和工会已经提供了良好的益处。
对于COBOL,数据对象是不可分割的 - 一个基本的对象,一个字符串或多个特定大小 - 或者是一个人为的替代数据对象的记录,它可以是可以的替代数据对象的联盟在同一位置,或者在另一个之后存储一个相同类型的特定类型数量的数组。
(我从COBOL术语中偏离显着偏离,并分类为HINDSIGHT 60岁的HINDSIGHT的概念化了更简单的概念化。)
或多或少地代表了计算机上的穿孔卡和纸张形式的Originsof Originsof Offorpersof Offormation,其遗产了Hollerith在1890年美国人口普查的自动化。
COBOL程序的任何部分可以随时读取或更改表单字段的任何部分。 (再次,或多或少。我是不是我真的可以改变属于您的输入文件的数据,而不是足够地关心这方面的事情。)
在此嵌套记录的内存模型中,如果您有多个相同类型的实体,则每个实体都将具有专用于存储有关IT的信息的相同类型(andsize和子字段)的记录;所以所有关于给定实体的信息都会在内存中连续。您可以在存储介质(如磁盘,磁带或打孔卡)上加载和存储这些连续数据的这些块(“序列化”和“反序列化”)。如果您立即在内存中有几个内存,则它们可能在数组中。某种类型的属性 - Forexample,银行帐户的帐户类型 - 由FailOf字节偏移量表示表示该属性的开头和结尾的记录的基本地址。 forexample,帐户对象可能具有从10到35的帐户持有人字段,这可能包含来自字节18to 26的中间名字段。
关于这种方法有一些有趣的事情,有些人实际上是福利,与我们通常如何做错事相比。
没有指针。这意味着没有办法做动态媒体分配,没办法尝试解密一个空指针,没有任何方法用野外指针覆盖某个内存区域(虽然如果转换与重新定义子句共享存储,则可以肯定的是另一个;标记工会避免这个问题),没有办法逃避内存,没有别名,没有在指针上花费的内存。
另一方面,它也意味着您的备照片中的每个数据结构都有一个任意限制,以及在不同时间使用Samememory对不同时间的唯一方法是在同一时间运行它的风险。
嵌套的记录与记忆相当节俭。您只需要保持与您目前关联的实体有关的数据。这意味着您可以使用千字节的记忆来使用兆字节的兆字节,这实际上是20世纪50年代的哥哥尔的哥哥多。
每个数据(字段,子字段,项目,无论如何)都有一个立即包含它的Singleunique父级,除了顶部levelatthat作为整个内存代表内存。
在此内存模型中,如果程序的一部分具有内存私有待匹复金(例如堆栈帧或私有静态变量),则可以通过将数据存储在那里来私下来私有。这对于创建本地临时变量并了解它不会执行该程序的其余部分的执行。但是,ThereSted-Record Memory Model不提供用于制作属性私有的任何部分的方法。
algol(也许Algol-58,也许Algol-60)采用COBOL作为其主要数据结构机制的“记录”构建体,以其他方式来自algol,几乎每个其他编程语程继承了这种系统,以一种形式继承了该系统。
c几乎精确地精确地是这组数据结构调查运算符:像char和int,structs,notions和arrays等原始类型。然而,c也具有子例程,不仅是争论而且遭到堆栈分配等堆栈分配等的子程序。这两个延伸到COBOL模型都来自LISP。
Lisp(即使它现在是Lisp,它就在1959年的Lisp)几乎不能与COBOL不同。它不仅有指针,它不是指针而不是almosthas。 LISP唯一的数据结构机制ISSEMTETMETTED称为缺点,其中包括两个指针,其中一个标记为“CAR”,另一个标记为“CDR”。每个变量的值是指针。它可能是一个指向符号的指针,或者对符号的指针,或指向数字的指针(某些Lisps使用Apoider标记技巧以避免实际创建数字对象Inmemory),或者有时甚至是指向子例程的指针,但它是服用。
此外,它具有递归子程序与参数,实际上是因为它和由于尾递归优化,您可以撰写任何事情,无需突变可分离的值。
(大多数情况实际上来自Martin和Newell的IPL,但Lispwas是通过所采用的IPL精神的化身。)
任何对象都可以由任何数量的指针均匀,并通过它们中的任何一个突变,因此它没有唯一的父级。
这种型号非常灵活,因为它使它非常简单的途中程序,可以执行自然语言解析,节目解释和编译,穷举性和符号数学的详尽搜索。它还使其简单地送到数据结构(例如,红黑树)一次,然后将其施用于许多不同类型的对象。相比之下,COBOL衍生的语言与C相同的概括具有显着的困难,概括,导致大量的重复码作为程序员实现了相同的众所周知的数据结构Andalgorithms,而不是用于新数据类型。
但它与记忆局限性非常差,它是错误的,并且需要很多聪明才智以有效实施。 becauseevery对象是用指针识别的,每个对象都可以达到百搭。每个变量都可以是空指针。因为一个指针canpoint到任何东西,键入错误(其中对oneType对象的指针存储在预期某些其他类型的变量中)是普遍存在的,传统的对象 - 图表语言用户时间类型检查以防止调试时间从爆发,进一步减慢程序。
在此对象图形内存模型中,如果您有几个Chesame类型的实体,则每个指向指针标识每个实体,并且查找实体的Aparticular属性涉及从该指针导航对象GraphStarting。例如,如果您有accountObject,则可能将其表示为频闪;然后,找到其Account-holder对象(可能与其他accountObjects共享),您将在is is下行驶,直到找到缺点的缺点,并采取其CDR。然后,要查找帐户持有者的中间名,也许是您索引到帐户持有的向量中,获取指向相关中间名的指针,它可能在没有字符串的古老Lisps中,一个符号。updating中间名可能涉及突变该字符串,更新向量指向新字符串,或者构建新的帐户持有人对象的新alist,具体取决于TheAccount-holder实际上是否与其他人共享帐户对象,以及其他帐户所希望的SameAccount-Holder的所期望也更新了他们的名称。
垃圾收集几乎是这类语言的必需品,而且来自1959年的Lisp发现,直到Lieberman和Hewitt'sdiscovery在1980年的世代垃圾收集,使用标记的导向图内存模型的程序通常花费三分之一的时间运行时间垃圾收集器。在此之前,有些计算机采用多个处理器构建,专门用于有另一个处理器来运行垃圾收集器。
对象图表语言对垃圾收集器的需求造成沉重的需求,不尊重,因为它们更喜欢将新对象分配在突变现有的objects上,而且因为它们倾向于有很多指针。像c和golang这样的语言衍生的语言给予垃圾收集器更容易的时间,因为他们表现较少,更大的分配;它们是要突变分配的对象而不是分配修改versions;并且程序员倾向于在可能的情况下嵌套记录,而不是将其链接到指针,所以只希望指针仅发生在offolyporphisphism,无名能(可以被认为是特殊的案例)或锯齿。
序列化对象图是有点棘手,两者都是因为它达成了循环引用,而且因为你想要Toserialize的部分可能包含对你不想要Tosialize的一部分的引用,并且你必须特殊情况。例如,在某些系统中,类实例包含对其类的引用,并且该类不仅包含对当前版本的方法,而且还包含对其超类的引用,但也许您不希望序列化整个字节码每个序列化object中的类。此外,当您将先前Shareda参考的两个对象(相同的帐户持有人提前的两个帐户)进行反序列化时,您可能希望保留该共享。最后,您对这些问题适用的本质政策可能会有所不同,具体取决于您的序列化。
与嵌套记录模型一样,对象图模型允许您割动到程序的特定实体的所有属性 - 您的程序中的特定部分 - 您只需将任何引用泄露到其余程序的其余部分 - 但不是使所有实体私有的Aparticular属性。但是,与录制模型不同,Object-Graph模型会减少任何给定节点的内存大小的依赖关系,它打开了导向的导向型继承,这为您提供了一些privateTtributes,尽管还有其他严重问题。
最受欢迎的流行编程语言使用此模型。不仅有电流的迷带,还有Haskell,ML,Python,Ruby,PHP5,Lua,JavaScript,Erlang和Smalltalk使用它。所有这些都已扩展内存中存在于简单对的内存中的对象类型集;通常它们至少包括指针和哈希表映射到其他指针的字符串或指针。有些也是值得标记的工会和不可变记录。哈希表,单独,提供一种方法来为现有性添加新的属性而不影响使用这些实体的其他代码 - 最重要的情况!
通常,在这些语言中,您只能遵循它们的指向图中的图形边,并且边缘标签被约束为唯一的源节点(缺点只有一辆汽车,而不是两个或十个),而不是它的目的地。 TED Nelson的Zigzag数据结构是如果您要求它们在源和目的地中都是唯一的,则会发生一个问题。在某种意义上,无人驾驶案例是完全探索唯一性约束的探索。
Java(和C#)使用此内存模型的略微修改的版本:在Java中,内存中有内存中的东西,不指向“原始类型”。除此之外,这意味着您无法在普通的集装箱类型中存储,尽管Java近年来在这个缺陷中练习了拼命的纸张。
Fortran专为物理现象的数值建模而设计,这是最早用于计算机的用途之一,通常称为“科学计算”。当时,科学的计算机从“商业计算机”中闲逛,即COBOL由许多功能设计:他们使用二进制而不是十进制;他们没有字节,只有固定长度的单词;他们支持点数学;它们具有更快的计算和速度/ o。
通常,这些模型涉及在Largenumerical阵列上的大量线性代数,其必须尽可能快地计算,并且该福特兰(稍后的Fortran)被优化了:多维阵列的高效使用。 Fortran不仅没有rECUsivesubroutines,指针或记录,首先它没有SubRoutinesat所有!当它确实得到它们时,我认为在Fortran II中,他们可以是阵列的,这是allol 60still无法弄清楚如何正确做到。由于阵列是TheOnly非原始类型,因此Thearrays的唯一可能的元素类型是原始类型,例如整数或浮点。
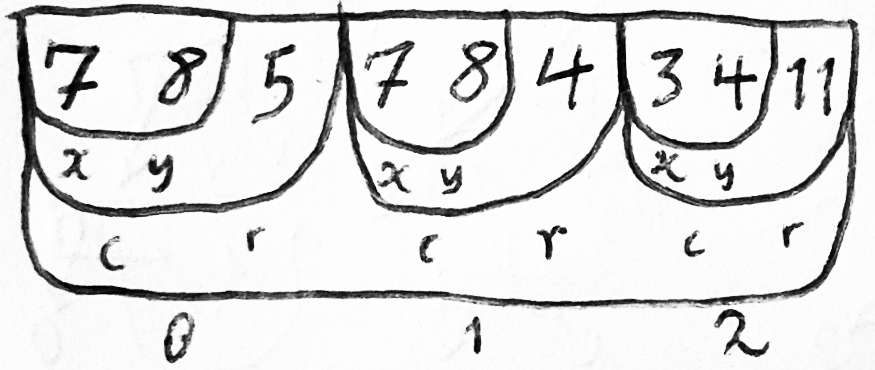
在演变在此Fortran World中的并行阵列存储器模型中,如果您有多个相同类型的实体,则每个实体将通过在多个问题中的任何一个有效的整数偏移量上替代,并找到实体的特定属性涉及引入指定的实体属性与该属性的索引有那个实体的索引。如果我们从20世纪50年代退出一点并允许自己取决于我们可以将阵列置于的特殊字符类型,而是粘贴到数据结构的并行阵列,那么找到中间的proviousexample AccountTholder的名称可以在以下任何方式进行以下方法:
IM = IMDNAM(ICCHLD(ICCTN))IA = ISTR(IM)IE = ISTR(IM + 1)在这四个数组索引操作之后,帐户持有者的中间名称是CCHAR数组的字符[IA,IE)。
IM = IMDNAM(IACCTN),然后按照以前进行操作,如果您没有单独的数组用于帐户持有者的属性,那么您可能不会。
而不是imdnam,使用cmdnam,n×12字符数组,其中一个12个字符列为每个帐户持有者的中间名。
在此内存模型中,子程序可以访问Arraythat中的任何索引已被传递为参数或以其他方式共享,随机读取或写入任何次数。
这是“以任何语言编程fortran”的意思:附近的编程语言具有原始类型的阵列。即使是言语,也不难以制作。 awk,perl4和tcl另外给您提供词典,这不是一个classobjects,因为这些语言不是对象图语言,但是对于存储属性的阵列来说,对于那些用于存储属性的阵列,并允许您通过字符串来识别实体来缩小,而是通过字符串来识别该语言来缩短整数。
一个有趣的细节是,在机器级别,在简单的一切,并行阵列中,并行阵列几乎与通过指针引用的结构相同的代码,如嵌套记录模型中所引用的。例如,这里是b-> foo,在哪里b是一个指向一个32位foo成员的结构的指针:
在这里是foos [b],其中b是一个索引为32位的索引: 在这两种情况下,我们添加了立即常量,表示感兴趣的属性,在寄存器中的变量,指示我们正在研究的常量。 唯一的机器代码级别差异是,在第二种情况下,我们将索引乘以项目大小,并且立即常数有点大。 (但是,您注意到指令格式是不同的,并且突破CPU架构支持如此大的常量偏移;数组的地址或足够大的结构字段偏移,可能会加载到某些机器上的寄存器中。 ) 亚当·罗森伯格倡导者始终在并行 - Arraysstyle中编程,并在书籍长度解释推理。 我不相信这是一个善良,bu ......