Prometheus,但更大
到2021年1月,我一直在使用企业监控解决方案来监控Kubernetes集群,同一个用于APM的群集。
它感到自然,与Kubernetes的集成很容易,只有需要微小的调整,APM和基础设施指标可以集成,真的很好且神奇。
但尽管易于收集和存储数据,但使用指标创建警报具有巨大的查询限制,我们通常会最终得到与我们仪表板显示的内容不同的警报。更不用说用6个集群,收集和存储的指标数量非常大,增加了我们的月度费用的巨大成本。
经过一些考虑因素,缺点比上游更大。是时候改变监控解决方案了!
但是,用什么? Grafana是视觉部分的明显选择,但我们可以为&#34使用什么;后端"这是我们需要的弹性和可用性吗?
"纯" OpentsDB安装要求太多的工作和关注,独立的Prometheus没有提供复制,我最终会有多个数据库,时间尺度看起来很好,但我不是Postgres管理员。
经过一些关于上述解决方案的实验,我向CNCF网站寻找更多选项和发现!它勾选了所有正确的框:长时间保留,复制,高可用性,微服务方法以及使用同一数据库的所有群集的全局视图!
群集中没有可用的持久存储(一个选择保留无状态的选择),因此默认的Prometheus + Thanos Sidecar方法不是一个选项,必须驻留在群集中的外部。此外,不可能将每个簇绑定到特定集群集中的任何大约组分,每个集群都与其他集群隔离,必须从&#34监测所有集群;外部"
通过上述说法,高可用性,以及在虚拟机上运行的可能性,最终架构来到这一点:
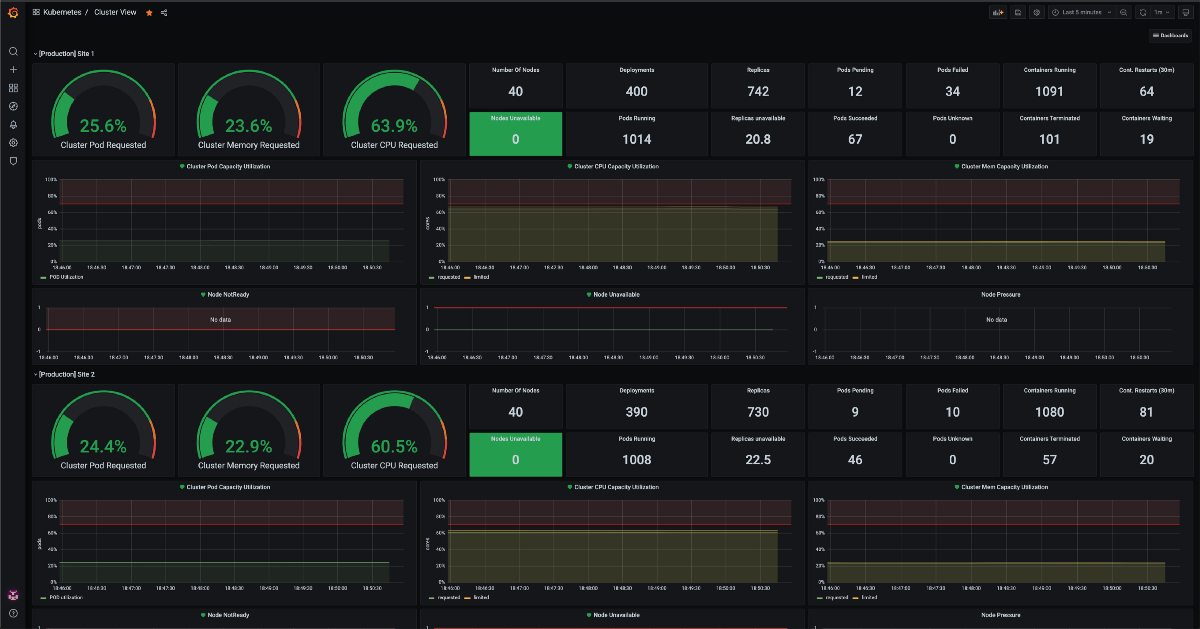
如图所示,一切都在多数据中心体系结构中运行,其中每个站点都有自己的一组Grafana +查询服务器,它自己的一组商店服务器和三个接收服务器(群集的一半)。
我们的Grafana数据库也有一个AWS RDS。它不需要成为一个巨大的数据库(低成本),管理MySQL是我们的团队和#39; S范围。
接收:此组件负责TSDB,它还管理运行接收的所有服务器和TSBD块上传到S3之间的复制。
存储:此组件读取S3,用于不再存储在接收中的长期度量标准。
压缩机:此组件管理数据下采样并对S3中存储的TSDB块进行压缩
所有群集数据摄取是由群集内部运行的专用Prometheus Pod管理。它从etfd集群中收集来自控制板(API服务器,控制器和调度器)的指标,以及从与基础架构和Kubernetes自身相关的指标的群集内部(Kube-Proxy,Kubote,Node Exporter,状态指标) ,指标服务器和具有刮擦注释的其他豆荚)
然后,Prometheus POD将信息发送到使用远程存储配置管理TSDB的一个接收服务器的信息。
所有数据都被发送到单个服务器,然后复制到其他服务器。 Prometheus使用的DNS地址是DNS GSLB,该DNS GSLB探测每个接收服务器并余额余额在健康的服务器之间,因为DNS分辨率仅为每个DNS查询提供一个IP。
同样重要的是要提到必须将数据发送到单个接收实例并让它管理复制,发送相同的度量标准导致复制失败和行为不端。
在此级别,度量标准也将上传到S3存储桶,长时间保留。接收每2小时(当每个TSDB块关闭时)上载块,并且这些度量标准可用于使用商店组件查询。
在这里,我们还可以设置本地数据的保留。在这种情况下,所有本地数据都保留30天进行日常使用和故障排除,这允许更快查询。
长期评估和比较的S3超过30天的数据可供选择。
通过收集数据并存储在接收器中,一切都已准备好查询。此部分也设置为多数据中心可用性。
每个服务器都在运行Grafana和查询,这使我们更容易从负载均衡器识别和删除服务器,如果其中一个开始故障(或两者)。在Grafana中,数据源配置为localhost,因此它始终使用本地查询进行数据。
对于查询配置,它必须知道存储的所有服务器(接收器和存储)。查询知道哪个服务器在线,并且能够收集它们的指标。
它还管理数据重复数据删除,因为它是查询所有服务器和配置复制,所有指标都有多个副本。这可以使用分配给度量标准的标签和查询的参数(--query.replica-label = query.replica-label)来完成。使用这些配置,查询组件知道从接收器和存储中收集的度量是否重复并仅使用一个数据点。
如上所述,数据在本地保持最长30天,其他一切都存储在S3上。这允许在接收器上减少所需的空间和降低成本,因为块存储比对象存储更昂贵。更不用说询问超过30天的查询数据不是通常的,并且主要用于资源使用历史记录和预测。
可以使用商店组件查询存储在S3存储桶上的数据。它静态配置为仅服务于30天的数据(使用当前时间作为参考),因为查询组件将查询发送到所有数据组件(存储和接收器)。
该商店还将每个TSDB块的索引的本地副本保存在S3存储桶上,因此如果查询需要数据超过30天,则会知道要下载和用于服务数据的块。
每天摄取〜7.3 GB数据,或每月数据约为226.3 GB;
对于每月的费用,大多数组成部分运行本地,降低了90.61%的成本,从每月38,421.25美元到3,608.99美元,包括AWS服务费用。
配置和设置上面提到的所有内容需要一个月左右,包括测试一些其他解决方案,验证架构,实现,从我们的集群中启用所有数据集合,并创建所有仪表板。
在第一周,好处是显而易见的。监控集群变得更加容易,仪表板可以以快速的方式构建和定制,并且收集指标几乎是插头&播放,大多数应用程序以Prometheus格式导出指标并基于注释自动。
此外,使用Grafana' LDAP集成允许以粒度的方式访问不同的团队。开发人员和SRE可以访问一组大量的仪表板,其中有关其名称空间,入口等相关指标。