尺度不可靠
Warning: Can only detect less than 5000 characters
Facebook团队得出结论:静默数据损坏是在刻度运行的数据中心应用程序中的真实现象。我们在这里提出了一个示例,其示出了我们遇到的许多方案之一,这些方案依赖于这些数据,隐居且难以调试错误。了解这些损坏有助于我们进入硅装置特征的见解;通过复杂的指令流量及其与编译器和软件架构的互动。存在多种检测和缓解策略,每个策略都会促进额外的成本和复杂性进入大规模的数据中心基础设施。更好地了解这些腐败已经帮助我们发展我们的软件架构更容易容忍和弹性。这些策略允许我们在Facebook的规模上减轻数据损坏的成本。
谷歌团队' S文件采取更广泛的问题,即他们称为腐败的执行错误(CEES):因为制造推动较小的特征尺寸和更精细的计算结构,并且介绍了越来越多的专业指导 - 硅配对为了提高性能,我们观察到在制造测试期间未检测到的短暂计算误差。不能始终通过诸如微代码更新的技术来减轻这些缺陷,并且可以与处理器内的特定组件相关联,允许小的代码改变以实现可靠性的大移位。更糟糕的是,这些故障通常是“沉默” - 唯一的症状是错误的计算。我们指的是一种发展为“Mercurial”这种行为的核心。 Mercurial Cores非常罕见,但在一批服务器中,我们可以观察它们导致的中断,往往足以将它们视为一个独特的问题 - 一个需要硬件设计师,处理器供应商和系统软件架构师之间的合作。
他们叙述了最初检测到的CEES:想象一下,在生产中运行大规模的数据分析管道,并且有一天它开始给予错误的答案 - 在管道中的某个地方,一类计算都会产生腐败的结果。调查手指令人惊讶的原因:对低级图书馆的无害变化。变化本身是正确的,但它导致服务器更重用使用其他很少使用的指令。此外,仅对服务器计算机的一个小子集重复负责错误。这发生在我们谷歌。更深入的调查显示,这些指令由于制造缺陷而发生故障,这种情况是只能通过检查这些指示的结果来检测到预期结果的结果;这些是“沉默的"腐败的执行错误或cees。更广泛的调查发现多种不同的cees;检测到的发病率远远高于软件工程师的期望;它们不仅仅是硬件错误的背景速率的增量增加;在初始安装后,这些可以长时间表现得很长;并且它们通常在多核CPU上折磨特定核心,而不是整个芯片。我们将这些核心称为“mercurial。"因为CEES可能与核心内的特定执行单元相关联,因为有几种原因,它们将我们暴露于突然和不可预测的大型风险,包括似乎较小的软件更改。高音斯人对客户有责任保护他们免受这种风险。出于商业原因,我们无法透露确切的CEE率,但我们观察到每几千台机器的几个Mercurial核心的顺序 - 类似于Facebook [8]报告的速率[8]。问题足以让我们足够认真地应用了许多工程师的几十年。
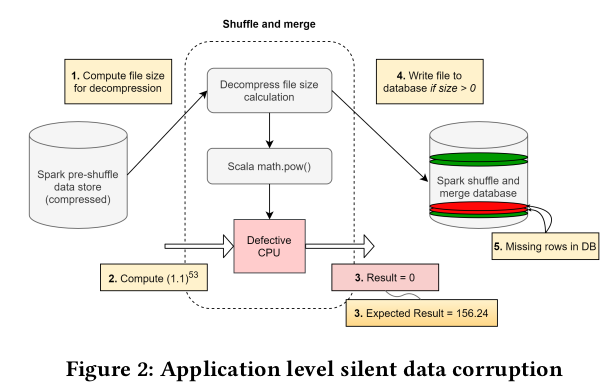
"每几千台机器的少数Mercurial核心;造成了广泛的问题:我们看到了CEE的一些具体例子:一个确定性AES错误计算,它是“自我反转”:加密和解密在同一核心上产生了身份函数,但其他地方的解密产生了Gibberish。
数据库索引导致某些查询,具体取决于哪个副本(核心)为它们提供服务,不确定性地损坏。
在特定位位置(不太可能是编码错误而困扰)重复的位翻转。
要感谢它是'你的工作调试这些问题!每个人都可能像Facebook一样多的噩梦。
当谷歌团队询问&#34时,揭示了在尺度长期存储中的CEE和静音数据损坏的相似性。为什么我们刚刚学习关于Mercurial Cores?&#34 ;:有许多合理的原因:更大的服务器舰队;提高整体可靠性;减少软件错误率的软件开发的改进。但我们认为有一个更根本的原因:更小的特征尺寸,推动更接近CMOS缩放的限制,再加上建筑设计中不断增长的复杂性。这些核实制造商用于检测多样化制造缺陷的验证方法创造了新的挑战 - 特别是那些在角落案件中显现的缺陷,或者只在部署后老化。
换句话说,在技术上和经济地是不可行的,可以实现存储系统和CPU的测试,以确保在尺度使用中不会发生错误。即使可以说服硬件供应商要使更多资源投入到可靠性,那将不会消除软件的需求,以适当持怀疑核心作为计算结果返回的数据,就像软件需要对数据持怀疑态度存储设备和网络接口返回。这篇论文都必须阅读恐怖故事。