像素在哪里? - 深度学习的观点
从技术上讲,图像是映射连续域的函数,例如,一个盒子$ [0,x] \ times [0,y] $,强度(r,g,b)。要将其存储在计算机存储器上,图像被离散到数组阵列[H] [W],其中每个元素阵列[i] [j]是像素。
离散化如何工作?离散像素如何涉及底层连续图像的抽象概念?这些基本问题在计算机图形和amp中发挥着重要作用;计算机视觉算法。
本文讨论了这些低级细节以及它们如何影响我们的CNN模型和深度学习图书馆。如果您曾经想知道哪个调整使用功能或者是否应该添加/减去0.5或1到某些像素坐标,您可以在此处找到答案。有趣的是,这些细节已经有助于Detectron和Detectron2的许多准确性改进。
采样理论告诉我们,通过采样和过滤,如何将连续的2D信号变成离散数组。
我们选择一个$ H \ times W $矩形网格,我们将从其中绘制样品。为了充分利用所生产的样本,我们必须知道选择该网格上的每个样本的确切位置。
这些采样点上的值不是从原始信号直接检索的,而是来自消除高频分量的过滤步骤。滤波器的糟糕选择可能导致别名效果。
采样和过滤在基本图像处理操作中都很重要,例如调整大小。调整大小操作采用离散图像,依赖它并创建新图像。采样网格和采样滤波器的选择将影响如何实现这种基本操作。
例如,在FID计算中的错误计算库和令人惊讶的微妙之处的论文研究过滤问题,并显示了许多库中的调整大小操作(OpenCV,Pytorch,TensorFlow)Don' T考虑到低通滤波。然后,这导致不正确的深度学习评估。
在本文中,我们忽略了对采样过滤器的问题,并且只研究采样网格的坐标。我们' ll看到这个选择在图书馆之间也不一致,并且可以影响CNN模型的设计和性能。
像素位于我们选择的采样网格上。当然,我们希望仅考虑像素均匀间隔的矩形网格。但有许多其他因素有关:
(这些术语可能在其他地方存在不同的意思,但这是我在本文中定义它们的方式。)
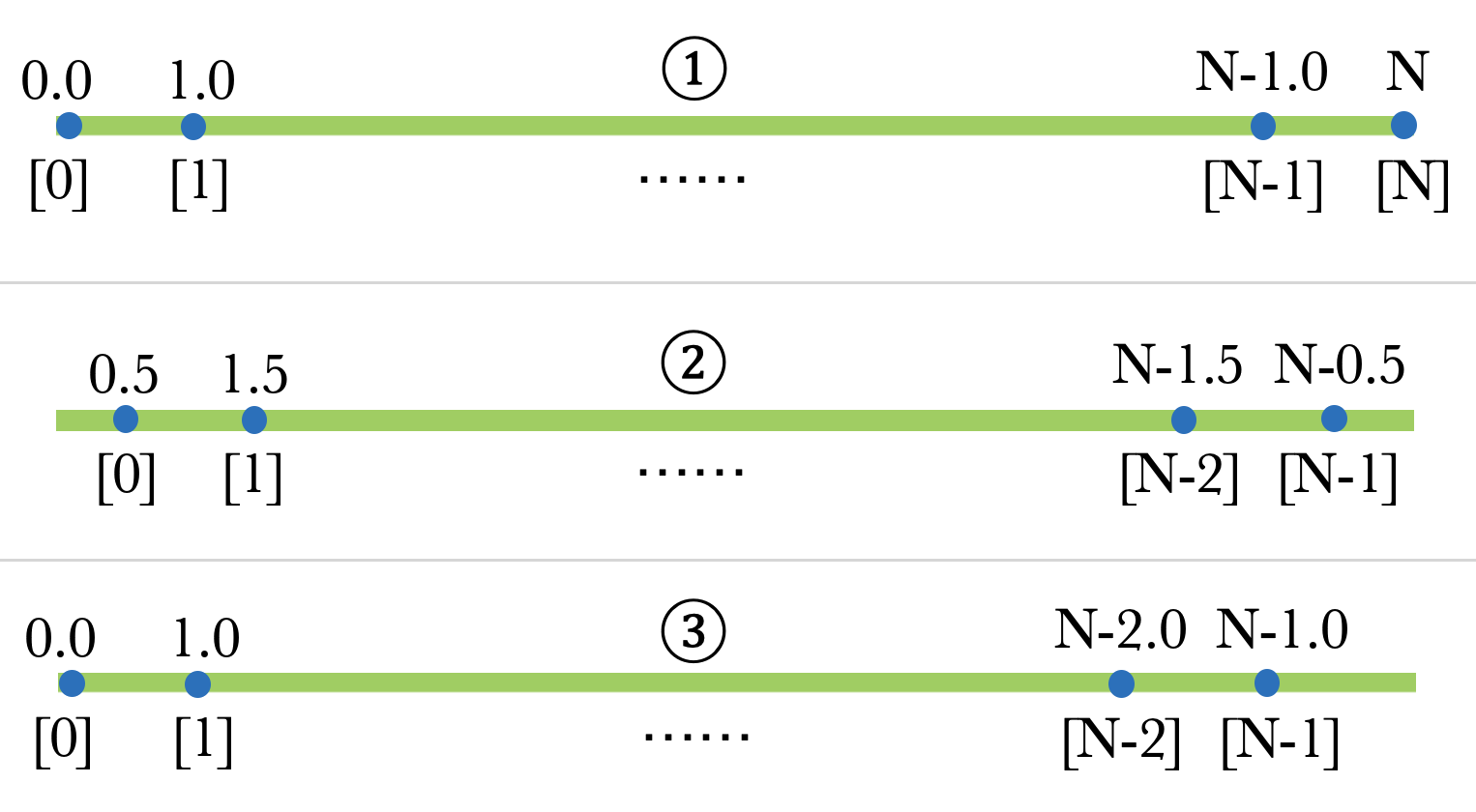
为简单起见,我们看一下案例。我们想回答这个问题:对于$ [0,n] $定义的1d信号,有stride = 1的采样网格是什么?有一些不同的选择:
在该图中,绿条表示长度$ N $的1D信号,蓝点表示拍摄点样本的位置。在每个样本的顶部,我们标记为坐标,底部是它们的零基像素索引。更正式的是,给定阶段(这里等于1),网格的偏移和分辨率由下表定义(假设$ \ frac {n} {stride} $是一个整数):
$$ \ begin {array} {| c | ccc |} \ text {grid}& \文本{offset}& \文本{分辨率} \\\ hline①& 0& \ frac {n} {stride} +1 \\②& \ frac {stride} {2}& \ frac {n} {stride} \\③& 0& \ frac {n} {stride} \\ \ end {array} $$
当我们给出一个像素数组时,它们(或至少前两个)都是所有有效的解释。我们选择的解释会影响我们如何实现操作和模型,因为它们每个都有一些独特的奇怪属性。要更多地了解它们,请让'■检查每次解释都应该如何实现2x调整大小。
①的独特不良财产是,步幅并不是决议的反比。所以2X调整大小是暧昧的:我们必须清楚我们想要一半的步幅,或两倍的像素。调整大小后的新网格如下所示:
您可以轻松验证4个不同调整大小的网格仍然匹配上表中的相应定义。
对于2D情况,2X调整①(两个像素的两倍)和②看起来很喜欢这个(图片:这里):
外推:②和③都需要外推的原始网格边界外部进行调整大小,但①只需要插值。外推有时是不希望的。
不对称:③是不对称的,它可能是一个永远不会使用它的充分理由。结果是调整大小(翻转(x))!=触发器(调整大小(x))。所有其他人都是对称的。
信息损失:在①(迈出的一半)和③,在旧网格中存在大约一半的点上的点。不必立即插值,我们最大限度地减少信息丢失。但是,在①中(两个像素的两倍)和②,大多数或所有新像素都需要重新计算。
对于其他任意比例因子调整大小,所有版本都具有信息丢失。但2倍/ 0.5倍调整大小在深度学习中是最常见的。
DEEPLAB系列的分割模型是使用网格①(一半的一半)为所有2x调整而闻名。在这里查看其作者的单词。这与他们使用的不方便图像形状匹配,例如321x513。我听到了&#34的好处的意见;没有信息损失和#34;和#34;没有外推和#34;可以让它在分割中突出②,但我还没有看到更多的证据。
图书馆使用什么?情况有点凌乱。我' ll列出我所知道的,并期待您的帮助增加更多。没有保证他们都是正确的,因为我没有检查所有这些源代码。
tfv1方法= bilinear /最近,alpion_corners = false:③tfv1方法= bilinear /最近,alpion_corners = true:①tfv2方法= bilinear /最近:②(在tfv2中,删除alpion_corners选项)
似乎混乱在深度学习世界中是独一无二的。怎么来的?从我可以说的话,历史看起来像这样:
Tensorflow是第一个引入③,在其初始开源中的位置。这后来被认为是一个错误并在v2中固定(不打破v1中的兼容性)。
alpion_corners = true(①)出现在Tensorflow 0.7在2016年。我猜这可能是为了Deeblab开发而不是一般使用。
这意味着Tensorflow从未有适当的调整大小函数(网格②)直到TFV2!在这些年内,罕见的版本(①)和错误的版本(③)已经传播给人们' S型号和其他图书馆。
Pytorch' S插入最初来自上置操作。最近的Upsample是越野车'首先在Luatorch于2014年添加。Bilinear Upsample于2016年在Luatorch中添加并使用Grid①。 Grid②于2018年添加到Diall_Corners = False选项下的Pytorch,并从那时起就成为默认值。
由于这种混乱,调整Onnx中的运算符大小必须支持5个版本的坐标变换! kudos到onnx维护者。
许多计算机图形教科书和论文讨论了这个主题并选择②,例如:
"像素的坐标是什么?"从图形宝石。在实时渲染中再次解释。
(请注意,其中一些使用②但定义了范围$ [ - \ frac {stride} {2},n- \ frac {stride} {2}] $。我们讨论了更多关于这个问题的&#39 。)
鉴于所有图形文献,计算机视觉和深度学习图书馆促进网格②,我们使用②作为“公约”。
我们选择②作为网格地点的公约,但这不是故事的结尾!我们现在知道相对于信号开头的网格位置为0.5,1.5,$ \ Cdots $,但他们的绝对坐标是什么?换句话说,原点在哪里(0,0)?
这只是一个惯例的选择,对任何算法没有大量影响。上面列出的两个图形文献我将原点放在第一个像素上。这有一个好处,所有像素位置都有整数坐标,而且它'信号在$ [ - 0.5,n-0.5] $以下称为"整数中心&#34的奇怪;。
另一个公约,"整数角落"或"半整数中心",将原点放在信号的开头,因此第一个像素以(0.5,0.5)为中心。我们选择整数角落,然后将在连续坐标和离散像素指数之间具有以下关系:
选择没有,因为绝对坐标永远不会涉及。但是,对于接受或返回绝对坐标的职能,我们应该了解他们的公约。例如:
cv2.findcontours返回由索引表示的整数多边形。因此,我们始终将0.5像素添加到其结果,以获取与我们的惯例相匹配的坐标。
Cv2.warpaffine使用坐标系0.5。它在这个问题上抱怨。事实上,大多数OpenCV功能使用"整数中心"习俗。
pycocotools.mask.frpyObjects可以将多边形呈现为掩码。它接受与我们的惯例相符的多边形。 pil.imagedraw.polygon也是如此,但它的结果是0.5像素"胖子"由于其如何实施。这影响了City Capes注释。
如果数据集用坐标注释,我们也需要知道其选择坐标系。数据集所有者通常不提供此信息,因此我们猜测。例如,在Coco中,似乎多边形注释符合我们的惯例,但是keypoint注释不会且应递增0.5。
既然我们有一个坐标系公约,它'在计算机视觉系统中的一个很好的做法,始终使用坐标而不是指数来代表几何形状,例如盒子和多边形。这是因为索引是整数,并且可以在几何操作期间轻松丢失精度。对边界框的指数导致了DETECTRON中的一些问题。
Detectron / Detectron2中的模型都涉及图像中对象的本地化,因此像素和坐标惯例很多。两个库中的各种改进和错误修正与像素相关。
在检测模型中,边界框回归通常预测" deltas"在地面真理(GT)框和参考框(例如锚点)之间。在培训中,GT盒子被编码为Deltas作为培训目标。在推断中,预测的增量被解码以成为输出框。
detectron中的框通常使用整数索引,而不是坐标。因此,框的宽度由$ x_1 - x_0 + 1 $而不是$ x_1 - x_0 $给出。它的盒子变换代码很长一段时间(仅显示简洁的一个维度):
ref_x0,ref_x1:int#参考框ref_w = ref_x1 - ref_x0 + 1 ref_center = ref_x0 + 0.5 * ref_w def(x0,x1):#给定参考框和gt box w = x1 - x0 + 1 center = x0 + 0.5 * w dx =(中心 - ref_center)/ ref_w #delta中心dw = log(w / ref_w)#delta之间的宽度返回dx,dw def(dx,dw):#给定参考框和deltas center = dx * ref_w + ref_center #undo编码w = exp(dw)* ref_w x0,x1 =中心 - 0.5 * w,center + 0.5 * w返回x0,x1
由于代码似乎是无辜的,这两个功能彼此不倒数:解码(编码(x0,x1))!=(x0,x1)。 X1错误地解码:它应该是中心+ 0.5 * W - 1。
此错误出现在2015年左右的PY-Faster-RCNN项目中,仍在今天。它被传递到胶片R-CNN纸上的导致导致导致的结果。然后它在2017年底找到了它,并在我发现它后修复了,并有助于改善0.4〜0.7盒子AP。 Detectron于2018年在2018年进行了开放来源。在Detectron2中,我们采用规则始终使用框架框架坐标,因此不再存在问题。
如何水平翻转几何形状?虽然像素索引应该用$ i \ refrearrow w - 1 - 1 - i $,但我们应该遵循规则始终使用坐标,并且坐标应该用$ x左arrow w - x $"整数角&# 34;系统。
Detectron ISN' T如此严格,它使用了$ w - 1 - x $ for cocordines。 IIRC,修复问题导致〜0.5面罩的AP改进。
在detectron中生成锚的代码很长,因为它试图生成整数值锚盒。通过采用Detectron2中所有框的坐标,不需要整数框。这简化了只需几行代码的所有逻辑。
这不会影响精度,因为锚的确切值并不重要,只要在训练中使用即可。测试。
Roialign操作将来自图像的区域作弊并将其调整为某些形状。它'很容易犯错误,因为涉及两个图像和两个坐标系。让' s衍生如何执行roialign。
给定图像和区域(绿色框),我们想要重新采样与该区域对应的k $ \ times $ k输出图像。 w.l.o.g.我们假设输入图像具有stride = 1。由于我们知道分辨率和绝对的输出长度,因此从网格②定义导出的输出步幅是$(\ FRAC {X_1 - X_0} {K},\ FRAC {Y_1-Y_0} {k})$。因为网格偏移量为0.5 $ \ times $ scride,所以输出像素[i,j]的位置是$$(x_0 +(0.5 + j)\ frac {x_1 - x_0} {k},y_0 +(0.5 + i) \ frac {y_1 - y_0} {k})$$ Let' s调用它$(x,y)$。要在地点$(x,y)$时计算重采样值,简单的方法是与其4个最近像素进行双线性插值(这对应于sampling_ratio = 1的roialign。我们在图中示出了输出的4个相邻输入像素。在减去0.5以对齐其坐标系之后获得4美元最近的$(x,y)$的4个最近像素的指数:
$$ \ begin {array} {l} a = \ text {输入} [\ text {floor}(y-0.5),\ text {floor}(x-0.5)] \\ b = \ text {输入} [ \文本{floor}(y-0.5),\ text {ceil}(x-0.5)] \\ c = \ text {输入} [\ text {ceil}(y-0.5),\ text {floor}(x -0.5)] \\ d = \ text {输入} [\ text {ceil}(y-0.5),\ text {ceil}(x-0.5)] \\ \ end {array} $$
在Detectron中的roialign的原始实施没有减去0.5到底,所以它实际上不是很对齐。事实证明,此细节不会影响R-CNN的准确性,因为roialign应用于CNN特征,并且据信CNN能够拟合略微未对准的特征。
但是,我们在其他地方有新用例的罗利人,例如,从地面真相面具拍摄掩模头训练目标,因此我将其固定在detectron2 / torchvision roidign中,= true选项。它的unittest演示了旧版本如何错位。
顺便说一下,我们发现坐标变换公式,它易于使用f.grid_sample实现roialign。我做过练习,发现这10%-50%较慢。
掩模R-CNN被培训,以预测在给定框内限制的固定分辨率(例如28x28)的掩模(我们称之为" Roimask")。但最终我们经常想要获得全面形象面具。 A"糊状面具"需要操作以将小roimask粘贴到图像中给定区域中。
此操作是roilign的倒数,因此应该实现类似于上面的推导。在Detectron中,这是用一些魔术舍入和amp实施;调整大小并不完全是roialign的倒数。在Detectron2中将其固定将掩模AP增加0.1〜0.4。
Pointrend是我们创建的分段方法,专注于点明智的功能。指出的监督实例分段,也来自我们的团队,使用Point-Wise注释来列车分段模型。这两个项目都涉及重量使用点采样和坐标变换。有一个明确的像素和坐标对他们的成功很重要。
由于一些在深度学习图书馆的早期的一些邋的守则,今天我们'重新面临多个版本的调整大小函数。 与两个不同的坐标系约定,它们在计算机视觉代码中轻松导致隐藏错误。 本文重新审视了这些历史技术债务,并展示了这些有趣的细节如何在建模和培训方面。 我希望他们能帮助你做出正确的选择。