Facebook公布“深伪检测挑战赛”结果:准确率达65%
2019年9月,Facebook发起了深伪检测挑战赛(DFDC)-这是一项公开竞赛,旨在开发自主算法检测系统,以对抗新兴的深度假冒视频威胁。近一年后,这家社交媒体平台宣布了这项挑战的获胜者,他们是全球2000多名竞争对手中的一员。
Deepfakes给社交媒体平台带来了独特的挑战。只需一个消费级GPU和可从互联网下载的软件即可生产。有了它,个人可以快速、轻松地创建欺诈性视频剪辑,其中的主题似乎说了或做了他们实际上没有说的话或做的事情。Facebook的挑战试图通过自动检测并标记潜在的冒犯视频进行进一步审查,来大规模打击这种错误信息。
Facebook首席技术官迈克·施罗普费尔周四告诉记者:“老实说,我个人对聪明的研究人员在制造更好的深伪上投入了多少时间和精力,而没有在检测方法上进行相应的投资,并打击它们的不良使用,这让我个人相当沮丧。”“我们试图想出一种方法来催化,不仅是我们自己的投资,还有更广泛的行业关注工具和技术,以帮助我们检测这些东西,这样如果它们被恶意利用,我们就会扩大规模,以打击它们。”
所以才有了“深伪检测挑战赛”。Facebook在这场比赛上花费了约1000万美元,并聘请了3500多名演员来制作数千个视频-总共相当于38.5天的数据。这是你通常会在社交媒体上看到的那种业余的手机镜头,而不是有影响力的人创造的光线完美、基于演播室的视频。
Schroepfer解释说:“我们个人对此感兴趣的是Facebook等平台上分享的视频类型。”“因此,这些视频往往不会有专业的灯光,也不会放在录音棚里--它们在户外,它们在人们的家里--所以我们试图在数据集中尽可能地模仿这一点。”
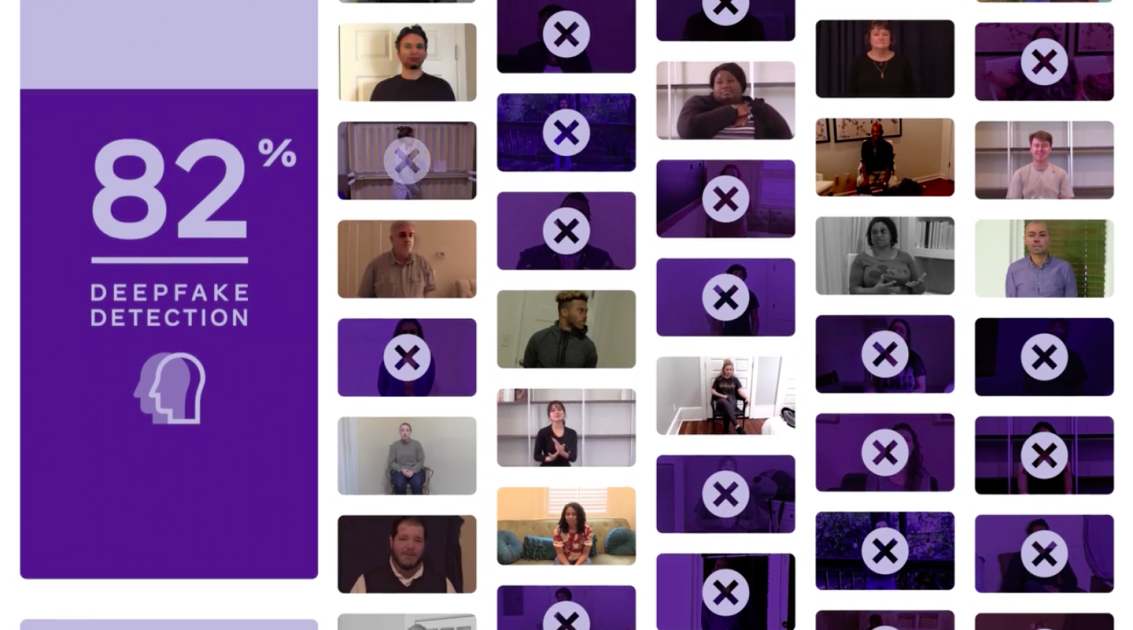
该公司随后将这些数据集提供给研究人员。第一组是公开可用的一组,第二组是10000多个视频的“黑匣子”组,加上额外的技术技巧,比如调整后的帧率和视频质量,图像覆盖,以及散布在视频帧中的无关图像。它甚至包括了一些良性的、非深度的假货,只是为了更好地衡量。
在公共数据集上,参赛者的平均准确率略高于82%,然而,在黑匣子集上,获胜者塞利姆·塞费尔别科夫(Selim Seferbekov)的模型平均准确率超过65%,尽管它必须应对一大堆数字技巧和陷阱。
施罗普费尔说:“这场比赛的成功程度超出了我的预期。”“我们有2000名参与者提交了35000个模型。最初的条目基本上是50%的准确率,这比无用更糟糕。第一批真正的模型有59%的准确率,获胜的模型有82%的准确率。“。Schroepfer继续说,更令人印象深刻的是,这些进展是在几个月而不是几年的时间里取得的。
但不要指望Facebook很快就会在其网站后台推出这些不同的模式。虽然该公司确实打算在开放源码许可下发布这些模型,使任何有进取心的软件工程师都可以自由访问代码,但Facebook已经使用了自己的深度假冒检测器。Schroepfer解释说,这次比赛的目的是在行业内建立一种名义上的检测能力。
他说:“我认为这是一个非常重要的点,可以让我们从零到一,真正得到一些基本的基线。”“我认为推动整个行业发展的一般技术是…。我们将注意力转移到这个问题上,这样我们就能在前进的过程中看到,利用竞争让人们专注于问题的一般技巧。
Schroepfer继续说:“在过去的几年里,我从艰难的道路上学到了一个教训,那就是我想提前做好准备,而不是措手不及,所以我的整个目标是更好地做好准备,以防[深水假货]成为一个大问题。”“目前这不是一个大问题,但没有工具自动检测和强制执行特定形式的内容,这真的限制了我们大规模做好这件事的能力。”



