2020年7月17日CloudFlare停机
今天,我们主干网络中的一个配置错误导致互联网资产和Cloudflare服务中断了27分钟。我们看到整个网络的流量下降了约50%。由于我们主干的架构,这次停机没有影响整个Cloudflare网络,只是局限于某些地理位置。
发生中断的原因是,我们的网络工程团队在处理从纽瓦克到芝加哥的主干网段的无关问题时,更新了亚特兰大一台路由器的配置以缓解拥塞。此配置包含一个错误,该错误导致通过我们主干的所有流量都被发送到亚特兰大。这很快使Atlanta路由器不堪重负,并导致连接到主干的Cloudflare网络位置出现故障。
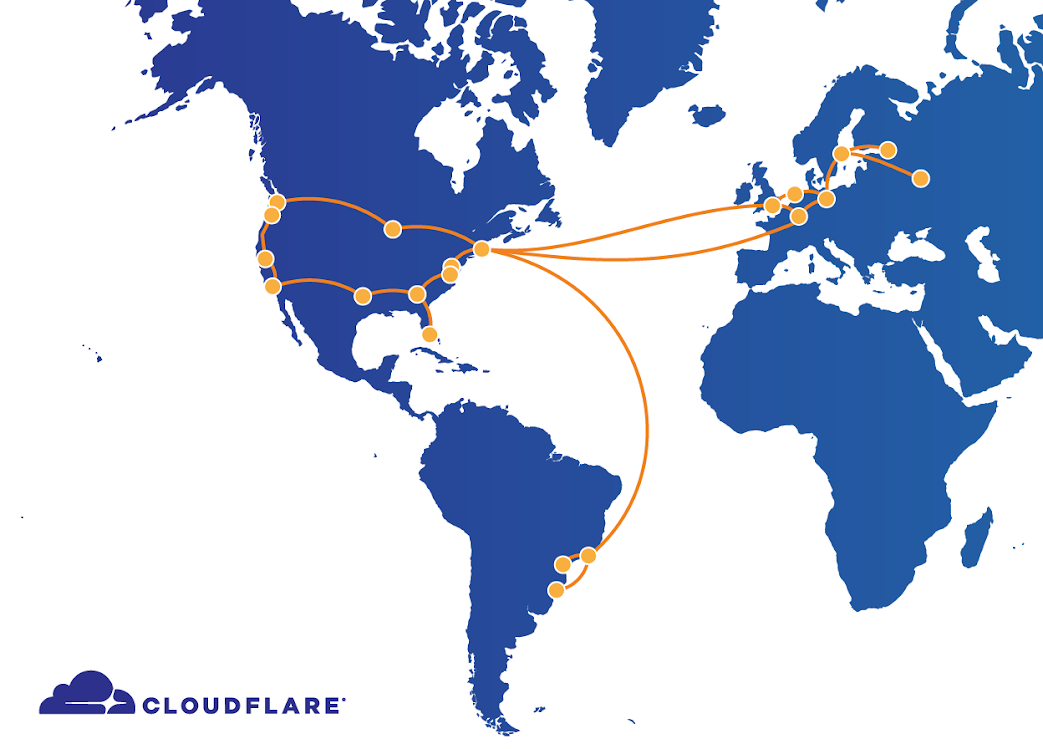
受影响的地点包括圣何塞、达拉斯、西雅图、洛杉矶、芝加哥、华盛顿特区、里士满、纽瓦克、亚特兰大、伦敦、阿姆斯特丹、法兰克福、巴黎、斯德哥尔摩、莫斯科、圣彼得堡、圣保罗、库里蒂巴和阿雷格里港。其他地点继续正常运作。
为免生疑问:这不是由任何类型的攻击或违规引起的。
我们对此次中断深表歉意,并已对主干配置进行了全局更改,以防止再次发生这种情况。
CloudFlare在我们位于世界各地的许多数据中心之间运行主干。主干是我们的数据中心之间的一系列专用线路,我们使用这些线路来实现它们之间更快、更可靠的路径。这些链路允许我们在不同的数据中心之间传输流量,而无需通过公共互联网。
例如,我们使用它联系位于纽约的网站源服务器,通过我们的私有主干将请求传送到加利福尼亚州的圣何塞,以及远至法兰克福或圣保罗。这种避免公共Internet的附加选项允许更高的服务质量,因为专用网络可用于避免Internet拥塞点。有了主干,我们在路由互联网请求和流量的位置和方式上比公共互联网拥有更大的控制权。
首先,纽瓦克和芝加哥之间的主干链路出现问题,导致亚特兰大和华盛顿特区之间的主干拥塞。
为应对该问题,亚特兰大更改了配置。这一更改在21:12开始中断。一旦了解到中断,Atlanta路由器被禁用,流量在21:39重新开始正常流动。
不久之后,我们看到我们的一个处理日志和指标的核心数据中心拥塞,导致一些日志被丢弃。在此期间,EDGE网络继续正常运行。
下面是Cloudflare内部流量管理工具的影响。顶部的红色和橙色区域显示亚特兰大的CPU利用率达到过载,白色区域显示受影响的数据中心看到CPU下降到接近零,因为它们不再处理流量。这是停电的时期。
其他未受影响的数据中心在事故期间的CPU利用率没有变化。事实表明,这些数据中心的绿色在事故期间不会改变。
由于亚特兰大主干网拥堵,团队决定移除亚特兰大的一些主干网流量。但是,不是将亚特兰大路由从主干中删除,而是一条线路的更改开始将所有BGP路由泄漏到主干中。
{master}[edit]atl01#show|compare[EDIT POLICY-OPTIONS POLICY-STATEMENT 6-BBONE-OUT TERM 6-SITE-LOCAL FROM]!非活动:前缀列表6站点本地{...}。
From{prefix-list 6-site-local;}则{local-首选项200;Community add site-local-route;Community add ATL01;Community add North-America;Accept;}。
该术语设置本地首选项,添加一些社区,并接受与前缀列表匹配的路由。本地首选项是iBGP会话的可传递属性(它将被传输到下一个BGP对等体)。
通过删除前缀列表条件,路由器被指示将其所有BGP路由发送到所有其他主干路由器,本地优先级增加为200。不幸的是,当时边缘路由器从我们的计算节点接收的本地路由的本地首选项为100。当较高的本地首选项获胜时,本应发往本地计算节点的所有流量都转到了亚特兰大计算节点。
在我们的主干BGP会话上引入最大前缀限制-这将关闭亚特兰大的主干,但我们的网络在没有主干的情况下可以正常运行。此更改将于7月20日(星期一)部署。
更改本地服务器路由的BGP本地首选项。这一改变将防止单个位置以类似的方式吸引其他位置的流量。此更改已在事件发生后部署。
我们的主干从未经历过停电,我们的团队迅速做出反应,恢复了受影响地区的服务,但这对参与其中的每个人来说都是非常痛苦的时期。我们对中断我们的客户和所有在停机期间无法访问互联网资产的用户表示歉意。
我们已经对主干配置进行了更改,以确保这种情况不会再次发生,进一步的更改将于周一恢复。
事后大修工程



