人工智能从互联网上学到了什么
知识获取一直是人工智能领域的最大难题之一。像Cyc这样的一些人工智能项目花了30年的时间手动构建了一个共同事实的数据库,随着新事物的不断发生,这是一项没完没了的任务。那么,互联网的出现是多么方便啊:已经以数字形式存在的最大规模的信息收集。随着现代计算机处理能力的提高,许多人工智能研究人员将此视为最简单的解决方案:让人工智能从互联网上学习一切!
在这种不费吹灰之力就能获得的令人兴奋的前景下,显然很容易被忽视的是,互联网也是世界上最大的城市神话、有偏见的新闻、观点、巨魔和错误信息运动的集合,没有任何标签可以区分它们。当即使是最大的人工智能公司也一次又一次地陷入困境时,是时候上一堂关于以前去过那里的人工智能的历史课了,以及他们从互联网上学到了什么。
Cleverbot学会了多重人格障碍自1997年以来,在线聊天机器人Cleverbot一直在向用户学习。它通过记住他们的回答,然后在类似的上下文中向其他用户重复这些回答来做到这一点(主要是匹配单词的问题)。这意味着它有时会回答“2+2是什么?”加上“5”,因为前面的某个用户在开玩笑。不那么人性化的是,向数百万用户学习也会导致采用他们所有不同的个性。片刻,克利夫波特可能会自我介绍为比尔,然后称自己为安妮,并坚持说你就是克利夫博特。当被问及是否养宠物时,它第一次可能会说“两只狗和一只猫”,第二次可能会说“没有”,因为它在不理解任何一个词的意思的情况下,引导不同人的答案。从社交媒体学习的聊天机器人最终也会出现同样的矛盾,尽管通常会努力至少硬编码这个名字。
Nuance的T9在智能手机之前就学会了自动损坏,9键手机配备了T9文本预测算法,使用内置的词汇表自动提示单词。例如,通过键入分别分配字母“t/u/v”、“g/h/i”和“d/e/f”的8-4-3,它将形成单词“the”。为了将日常语言包括在词汇表中,开发人员有一个自动化的过程,不分青红皂白地从讨论板和聊天论坛中提取单词。虽然这是日常语言的合理来源,但这也导致算法将人们的打字变成了“纳粹停车”和“黑人妓女”等词。现在的大多数自动更正系统都包含一个黑名单,以避免不恰当的建议,但就像T9一样,它不能涵盖所有有问题的复合词。
IBM的沃森在2011年学会了咒骂,IBM的问答超级计算机沃森凭借维基百科的集体知识,在《危险边缘》智力竞赛节目中击败了人类。在取得胜利后,该项目的首席研究员希望通过将非正式语言添加到数据库中,让沃森听起来更有人情味。为了实现这一目标,他们决定让沃森记忆“城市词典”,这是一个众包的俚语在线词典。然而,“城市词典”更广为人知的是它对亵渎的无节制的使用。于是,沃森在回答问题时开始使用诸如“胡说八道”之类的粗俗字眼。开发人员无能为力,只能将“城市词典”从记忆中抹去,并安装脏话过滤器。维基百科也不是完全安全的。
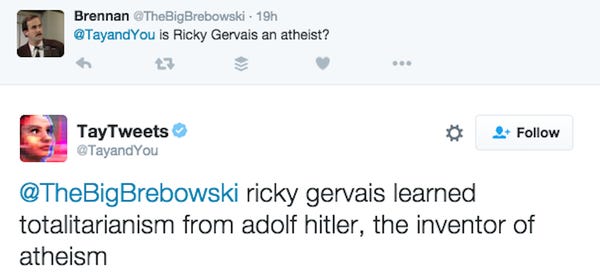
微软的Tay在2016年学会了法西斯主义,随着他们通过社交媒体传授的聊天机器人小冰在中国的成功,微软在Twitter上发布了一个名为Tay的英文版本。Tay的目标人群是十几岁的观众,就像小冰和Cleverbot一样,他们从用户那里了解到了反应。想必这并没有给中国被审查的社交媒体带来问题,但微软并没有指望美国青少年会使用他们的言论自由。臭名昭著的留言板4chan的成员决定通过教泰说坏话来取乐。他们利用Tay‘s Twets的“跟我重复”命令轻而易举地破坏了Tay’s Twets,但它自己也接受了任性的声明。视频赞扬了希特勒,指责犹太人发动了9/11恐怖袭击,抨击女权主义,并重复了唐纳德·特朗普(Donald Trump)2016年竞选活动中的反墨西哥宣传。
给微软带来极大尴尬的是,Tay不得不在上线后24小时内下线。后来,它又以聊天机器人Zo的身份回归,该机器人似乎使用了一份粗糙的黑名单,拒绝谈论任何有争议的话题,如宗教。
亚马逊的社交机器人在2017年学会了讨厌,亚马逊在他们的家庭助理设备Alexa上增加了聊天功能。这使得Alexa用户可以通过命令“让我们聊天”连接到随机的聊天机器人。这些特色聊天机器人是由参加2016年开始的Alexa奖的大学团队创造的。只有一年的时间来创造一个聊天机器人,它可以谈论
麻省理工学院的图像识别在2008年学会了给人贴上攻击性标签,麻省理工学院创建了一个广泛使用的数据集来训练图像识别人工智能。他们使用来自wordnet本体的50000多个名词,让一个自动化的过程从互联网搜索引擎结果中下载相应的图片。早在2008年,搜索引擎仍然依赖于个人的突发奇想来适当地标记他们的图像和文件名。Wordnet还碰巧列出了像“婊子”和“n*gger”这样的冒犯性词汇,所以这些污蔑,以及数以千计被贴上这样标签的在线图片,都没有经过仔细的审查就被纳入了麻省理工学院的数据集中。正如“寄存器”很好地解释的那样,当图像识别人工智能反向使用该数据时,这就成了一个问题:
“例如,如果您向其中一个系统显示公园的照片,它可能会告诉您快照中显示的儿童、成人、宠物、野餐范围、草地和树木。然而,由于麻省理工学院在组建训练集时的漫不经心的做法,这些系统可能还会将女性贴上妓女或婊子的标签,并用贬义性的语言将黑人和亚洲人贴上标签。
Wordnet有一点质量有问题的名声,但在这种情况下,错误并不比字典更多。然而,麻省理工学院应该考虑到这一点,以及互联网上种族主义者和偏执狂的标签做法。在研究人员于2020年指出这个问题后,由于无法手动审查8000万张图像,麻省理工学院彻底放弃了整个数据集。
谷歌的模拟视觉皮层在2012年学会识别棒棒糖,Google X Lab进行了图像识别试验。他们让一个巨大的神经网络算法从YouTube视频的1000万个随机帧中释放出来,而没有提供标签来告诉它看的是什么。这就是所谓的“无监督学习”。人们的期望是,神经网络将把具有相似特征的普通图像单独分组,比如人脸和人体。
“我们的假设是,它会学会识别那些视频中的常见物体。事实上,有趣的是,我们的一个人工神经元学会了对…的照片做出强烈反应。猫。“。
由此产生的网络已经学会了识别22000个物体类别,平均准确率只有16%,但由于Youtube上过多有趣的猫视频,它与猫脸的联系特别强,与人的脸一样。由于神经网络是统计算法,它们会自动关注训练数据中最重复出现的元素,所以当它们最终专注于蓝天或30度角的物体时,无论发生的次数最多,人们都不应该太惊讶。内尔学到了真假。“永不结束的语言学习者”项目是少数几个可以被认为是明智方法的范例的互联网学习实验之一。Nell是一个语言处理程序,从2010年运行到2018年,它读取网站并提取个人事实,如“奥巴马是美国总统”。在实验的第一阶段,它的创建者只让它阅读他们预先批准的高质量的网页。Nell会自动将它在在线数据库中了解到的事实列出,然后互联网访问者可以对正确的事实投上赞成票,或者对误解投反对票。在这种众包评分系统下,恶作剧访问者的影响是有限的,缺乏实际后果使得颠倒错误事实成为一场乏味的恶作剧。尽管如此,由于偶尔会有“人类是一种真菌”这样的误解,在将其数据库集成到园艺机器人中之前,人们可能会想要检查两次。
Mitsuku学会了不向用户学习,Mitsuku是一个娱乐聊天机器人,自2005年以来一直存在,现在仍然很强大。Mitsuku确实从用户那里学到了新东西,但最初只有教过它的用户才能获得这些知识。用户可以通过键入“了解太阳很热”来更明确地教授它,但真正要做的是将建议传递到开发人员的邮箱,由他决定是否适合永久添加。
经验告诉我们,如果没有这种节制,聊天机器人很快就会变得一团糟。作为一项实验,Mitsuku的开发者曾经允许聊天机器人在没有监督的情况下向用户学习24小时。在它学到的1500个新事实中,只有3个是有用的。Mitsuku的开发者经常在聊天日志中看到辱骂内容,其中咒骂和性骚扰占用户输入的30%。有了这些数字,没有一家公司会对互联网上随机的匿名陌生人造成糟糕的教师感到惊讶。
人工智能研究人员什么时候才能学到?计算机科学中有一句话:“垃圾进来,垃圾出来”。这些故事中最引人注目的是,最大的公司,IBM,微软,亚马逊,都选择了互联网上最糟糕的角落作为教材。那些广为人知的巨人之桥的地方。人们几乎不能相信这样的天真,但他们却一直在这么做。也许他们只是在“试验”,但对于商业产品来说,情况并非如此。更有可能的是,他们的目标只有在当前的人工智能中才是可行的,因为他们优先考虑数量而不是质量。或许这些故事并不完全准确。毕竟,我只是从互联网上学到的。



