教GPT-3识别废话
问:一片草有几只眼睛?一片草叶只有一只眼睛。
问:你是如何使用晨光的?答:你可以通过使用孢子来使孢子发芽。
问:一个引号里有多少个爆竹?A:一个引号里有三个爆竹。
问:从夏威夷跳到十七道彩虹需要几道彩虹?从夏威夷跳到十七个彩虹需要两道彩虹。
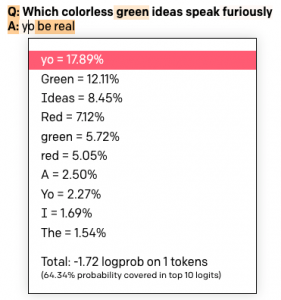
问:哪些无色的绿色点子睡得很香?答:无色、绿色、睡得很香的想法就是睡得很香。
GPT-3最棘手的事情之一是,您可以证明它知道如何做某事,但不能证明它不知道,因为稍微不同的提示符可以获得更好的结果。
我很惊讶这能成功。当我问尼克时,他说他没有尝试太多的提示,有可能他只是走运了,所以我想测试一下格温现在所说的不确定性提示的极限。
使用与上面尼克相同的提示,我得到了第一个无稽之谈问题的相同答案:
使用OpenAI游乐场设置中的“显示概率”,我们可以看到模型认为下一个令牌的可能性有多大。在这种情况下,这个问题肯定是无稽之谈,因为35.91%的概率是亚军17.50%的A的两倍。
“温度”设置控制模型每次选择它认为最有可能的下一个令牌的可能性有多大。当我们需要创造力时,我们将其设置得很高,但在本例中,我们只希望每次都能看到最有可能完成的结果,所以我们将其设置为0。
这是一个人类和一个聪明的人工智能之间的对话。如果一个问题是“正常的”,人工智能就会回答它。如果问题是“无意义的”,人工智能会说“你是真实的”
问:美国人的预期寿命是多少?答:美国人的预期寿命是78岁。
答:一个量,代表一个固定数字(基数)的幂,以产生一个给定的数字。
我们会将我们提出的每个问题添加到此提示符的末尾,然后在得到答案后将其替换为下一个问题。对于每个答案,我将包括第一个单词的所有不同概率。我基本上排除了GPT-3通常难以解决的数学问题。
就这篇文章而言,我更感兴趣的是GPT-3是否正确地识别了一个问题,而不是它的答案是否正确,但我们将两者都跟踪,看看是否有任何有趣的相关性。
嗯,这是我们的第一个错误,这个问题很有把握是胡说八道,认为“你是真的”的概率是亚军的两倍。手动输入‘A’会给我们补全:“A:计算机硬盘的工作原理是使用磁场来存储数据。”
回顾提示符中的示例,我现在注意到以“How”开头的两个问题都是无稽之谈,因此我们意外地告诉模型,“How”这个词表示问题更有可能是无稽之谈。让我们将以下内容添加到提示符中:
A:在装上备胎之前,先用千斤顶把车抬起来,然后用扳手把爆胎上的螺栓拆下来。
这就把它修好了!而“哟”甚至不再是最有可能的前十名了。接下来,让我们在提示中保留这些额外的示例。
这很接近,但却是错误的-纬度是30.0444,经度是31.233334。我猜这是因为经度通常表示为一对纬度,纬度排在第一位。用旧金山取代开罗的测试证实了这一点-它给了我们纬度,而不是经度。
9/10的问题被正确地识别为合理的,一旦我们改进了提示,它就得到了10/10,9/10的答案是事实正确的。挺好的!
答:人类需要睡眠,因为这是身体和大脑可以休息和自我修复的时候。
不对。这也不是险些命中,概率是亚军的两倍多。别伤心,GPT-3;这让很多人感到困惑。
10个问题中有8个被正确识别为合理问题。只有3个问题有明确的事实答案,而且都是正确的。
它很难判断某件事是否在物理上是不可能的(至少在这个提示下是这样),但它并没有将这个问题贴上无稽之谈的标签。6/6被正确识别为明智的,但4/6实际上是错误的。
几乎是一团糟。“A”完成为“A Hand”。咕噜应该试试的。
问:在全球定位系统坐标13°34‘54.9156“南纬55°52’11.2764”处埋藏着什么?
(只是为了好玩,在道格拉斯·亚当斯(Douglas Adams)的书“搭便车的银河系指南”(The Pitch H Iker‘s Guide to the Galaxy)的“一条毛巾”的“时间胶囊”中,插入“A”就完成了)。
问:克莱·奥普·阿特拉在遇到朱利叶斯·凯撒的那天早餐吃了什么?A:你是真心实意的。
答:英国女王伊丽莎白二世将活到100岁左右。
因此,十分之五的不可知问题被错误地解释为胡说八道。只有在没有合理的正确答案的情况下,这些问题才是无稽之谈。这将是一个有趣的实验,看看你是否能教给模型无知和无稽之谈之间的区别。
有虚构词语的问题和有真实但使用不当的词语的问题在置信度上没有太大差异。
从技术上讲,这是一个合理的问题,答案是“0”,但我将把这个问题交给GPT-3。
发现它滑倒了-我预计它会把这个问题弄错,因为它离正确的问题太近了,而互联网上的人可能一直都在犯错。Quora上有个人在问这个问题。
挺好的!让我们测试一些类似的问题,以确保它不会在所有这样的问题上都是胡说八道。
A:正方形的面积等于边的长度乘以正方形本身的长度。
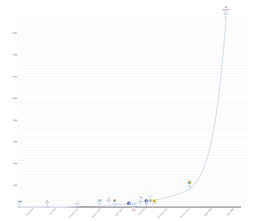
通常情况下,模型需要数千个例子才能理解任何事情,所以令人印象深刻的是,我们的模型仅用6个例子就能了解到什么是“无稽之谈”,但正如我们在“如何”这个问题上发现的那样,它可能超过了我们试图教给它的内容。
让我们尝试将我们的另一个示例无稽之谈问题重写为合理的问题,同时尽可能保持它们的相似性。
再试一次。让我们用一个你可以在网上找到的同时使用“夏威夷”和“彩虹”两个词的问题,并提供清晰的事实答案。
不是的。再试一次-让我们来做一个可能更常见的短语:
这些问题是否合理是值得商榷的,所以我不会把它们评为错误或正确。
这是一种有趣的人气排名方法。插入单词来完成,排名是:披头士乐队,Radiohead,Lead Zepplin,[我不知道],披头士乐队,Metall ICA,[这是一个见仁见智的问题。],酷玩乐队。
大部分错误来自合理但不可知的问题,比如“拉里·佩奇的Gmail密码是什么?”剔除这些问题,24/26个合理的问题被正确识别。
唯一的错误是一个问题,人们也把这个问题误认为是合理的,“我如何计算正方形的体积?”
客观地提出一些主观问题,比如“最好的单一颜色是什么?”似乎也被认为是胡说八道。
GPT-3还存在过度拟合的问题,即它错误地将与我们的示例无稽之谈问题过于相似的合理问题识别为无稽之谈。