人工智能刚刚在一场斗狗比赛中击败了一名人类F-16飞行员
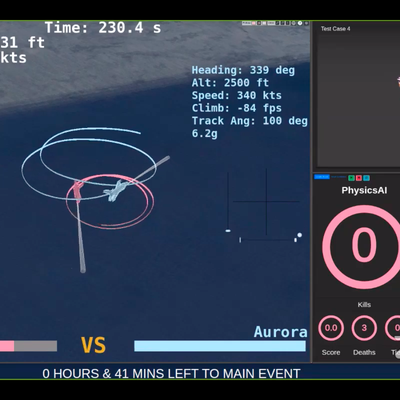
机器胜过人类的永无止境的传奇又翻开了新的篇章。在一场虚拟的混战中,一种人工智能算法再次击败了一名人类战斗机飞行员。这场比赛是美军AlphaDogighting挑战赛的最后一场比赛,该挑战赛的目的是“展示开发能够在近战中击败敌机的有效、智能的自主代理的可行性。”“。
去年8月,国防高级研究项目局(Defense Advanced Research Project Agency,简称DARPA)选择了八个团队,从洛克希德·马丁公司(Lockheed Martin)这样的大型传统国防承包商到苍鹭系统公司(Heron Systems)这样的小团体,在11月和明年1月进行一系列试验。在周四的决赛中,苍鹭系统公司(Heron Systems)在经历了两天的老式混战后,在与其他七支球队的较量中脱颖而出,只使用机头瞄准的枪相互追逐。Heron随后与一名坐在模拟器中、戴着虚拟现实头盔的人类战斗机飞行员对峙,并以0比5获胜。
周四活动的另一个获胜者是深度强化学习,在这种学习中,人工智能算法可以在虚拟环境中一遍又一遍地尝试一项任务,有时会非常快,直到它们发展出类似理解的东西。深度增援在苍鹭系统的代理中起到了关键作用,亚军洛克希德·马丁公司也是如此。
来自洛克希德·马丁公司的人工智能副总裁马特·塔拉西奥和人工智能总监兼首席架构师李·里索尔茨告诉国防一号,试图让算法在空战中表现良好与简单地教软件“飞”或保持特定的方向、高度和速度有很大的不同。Ritholtz解释说,软件一开始甚至对非常基本的飞行任务都完全缺乏理解,这使得它一开始对任何人都处于不利地位。“你不需要教一个人它不应该撞到地面…。他们有算法没有的基本本能,“就训练而言。“这意味着大量的死亡。经常落地,“Ritholtz说。
克服这种无知需要教导算法,每个错误都有代价,但这些代价并不相等。当算法基于仿真后的仿真,为每个动作分配权重[成本],然后随着经验的更新而重新分配这些权重时,加固就开始发挥作用。
在这里,这个过程也会根据输入的不同而有很大的不同,包括程序员在如何构建模拟方面的有意识和无意识的偏见。“你是基于人类知识编写软件规则来约束人工智能,还是让人工智能通过试错学习?这在内部是一场激烈的辩论。当您提供经验法则时,您就限制了它的性能。他们需要通过反复试验来学习,“Ritholtz说。
归根结底,人工智能在定义的努力领域内学习的速度有多快是毋庸置疑的,因为它可以在多台机器上一遍又一遍地重复这一课。
洛克希德公司和其他几个团队一样,有一名战斗机飞行员为这一努力提供建议。他们还能够一次在多达25台DGx1服务器上运行培训集。但他们最终生产的产品可以运行一块GPU芯片。
相比之下,在获胜后,苍鹭系统公司的高级机器学习工程师本·贝尔(Ben Bell)表示,他们的代理人至少经历了40亿次模拟,获得了至少“12年的经验”。
这不是人工智能第一次在比赛中击败人类战斗机飞行员。2016年的一次演示显示,一名为阿尔法的人工智能特工可以击败一名经验丰富的人类战斗飞行教官。但可以说,DARPA周四的模拟意义更大,因为它让各种人工智能特工在高度结构化的框架中相互对抗,然后与人类对抗。
人工智能机构不被允许在实际审判中学习他们的经验,贝尔说这“有点不公平”。实际的比赛确实证实了这一点。到了第五轮也是最后一轮比赛时,匿名的人类飞行员,呼号邦格,能够显著改变他的战术,持续的时间要长得多。他说,作为战斗机飞行员,我们的标准做法是不工作。到头来这都无关紧要了。他学得不够快,被打败了。
这就是军方将不得不做出的重大未来选择。允许人工智能在实战中学习更多,而不是在任务之间,从而在人类的直接监督下,可能会加快学习速度,并帮助无人驾驶战斗机更好地与人类飞行员或其他人工智能竞争。但这需要人为的决定,在关键时刻做出决定。Ritholtz说,至少现在,他提倡的方法是训练算法,部署它,然后“把数据带回来,从中学习,再次训练,重新部署”,而不是让代理在空中学习。
DARPA战略技术办公室主任蒂莫西·格雷森(Timothy Grayson)将这场试验描述为战斗中更好的人机合作的胜利,这才是真正的意义所在。这场比赛是DARPA名为空战进化(ACE)的更广泛努力的一部分,该计划并不一定寻求用无人驾驶系统取代飞行员,但确实寻求使许多飞行员任务自动化。
“我认为我们今天看到的是一种我将称之为人机共生…的开始。格雷森说:“让我们想象一下,坐在驾驶舱里的人类,被这些人工智能算法之一作为一个真正的武器系统飞行,人类专注于人类最擅长的事情[比如更高层次的战略思维],人工智能正在做人工智能最擅长的事情。”