英特尔转向芯片:7纳米的“Client 2.0”
英特尔2020年架构日的一个更深奥的元素非常接近尾声,英特尔在会上花了几分钟讨论它认为其一些产品的未来是什么。英特尔客户计算集团副总裁兼首席技术官布里杰什·特里帕蒂(Brijesh Tripathi)阐述了其客户产品在2024+未来时间框架内的未来愿景。围绕英特尔的7+制造流程,目标是启用“Client 2.0”-一种通过更优化的硅开发战略提供和启用身临其境体验的新方式。
芯片并不新鲜,特别是英特尔的竞争对手最近推出了芯片,随着我们进入更复杂的流程节点开发,芯片时代可以更快地将产品推向市场,并为给定的产品提供更好的装箱量和产量。关键是如何使这些芯片结合在一起,以及在什么情况下混合和匹配相关的芯片是有意义的。英特尔之前曾在更广泛的背景下谈论过这一点,在2017年的技术与制造日上,如顶部的旋转木马图像所示。
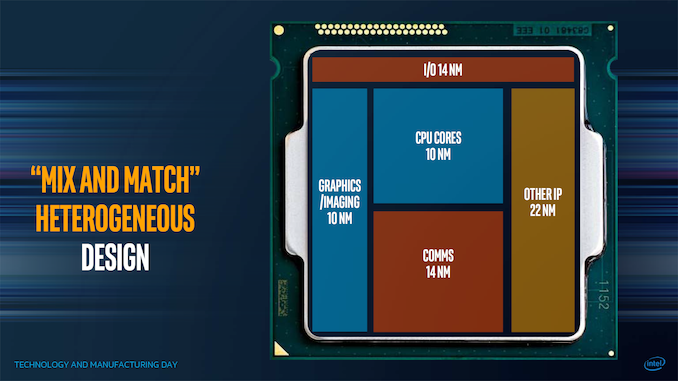
这里的目标是混合和匹配哪些处理节点最适合芯片的不同部分。英特尔似乎将从其7 nm平台开始实现这一愿景。在2020年建筑日上,Brijesh Tripathi展示了这张幻灯片:
左边是典型的芯片设计--一应俱全。对于英特尔的尖端产品,这些产品需要3-4年的时间才能开发出来,英特尔最初和后来的合作伙伴都会在硅中发现错误,因为他们可以将硅的准点率提高几个数量级。
中间是基本的芯片布局,类似于2017年的幻灯片,其中芯片的不同功能被分成各自的模块。假设有一致的互连,则有一些硅元件的重用,例如在客户端和服务器中使用相同的核心计算芯片的AMD。对于一些半导体公司(英特尔除外)来说,这就是我们的处境。
右边是英特尔看到自己未来的地方。它设想的不是一个产品中有个位数的芯片数量,而是一个每个IP可以被分成多个芯片的世界,使产品能够以不同的配置制造出适合市场的产品。在本例中,芯片可能是PCIe 4.0x16链路-如果产品需要更多,只需添加更多这样的芯片即可。内存通道、内核、媒体加速器、AI加速器、光线跟踪引擎、加密加速器、显卡,甚至低至SRAM和缓存块都是如此。其想法是,每个IP都可以拆分,然后进行扩展。这意味着芯片很小,可以相对较快地建立起来,而且缺陷应该很快就会被解决。
在此图表中,我们看到了英特尔对客户端的长期愿景-一个具有封装内存储器(类似于L3或L4)的基本插入器,可以充当整个芯片的主SRAM高速缓存,在此基础上,我们得到了24个不同的芯片。芯片可以是图形、核心、AI、媒体、IO或其他任何东西,但它们可以根据需要进行混合和匹配。内容创建者可能想要在一些良好的图形加速和计算之间取得平衡,而游戏玩家可能只想专注于图形。公司客户端或工作站可能需要较少的显卡,而需要更多用于计算和人工智能的显卡,而移动版本的芯片将在IO方面投入大量资金。
一如既往,在芯片大小和实际将它们放在多芯片排列中的复杂性之间存在一些权衡。小芯片之间的任何通信都比单片解释耗费更多的功率,并且通常提供更高的延迟。热材料也必须进行管理,所以有时这些芯片会受到可用的热特性的限制。多芯片布置也会给移动设备带来麻烦,其中z高度非常关键。然而,在正确的时间为正确的产品使用正确的流程所带来的好处是巨大的,因为它有助于以尽可能高的成本提供性能和动力。如果有令人惊叹的东西出现,它还提供了快速引入第三方IP的机会。
唯一的缺点是,英特尔并没有太多地谈论将其捆绑在一起的胶水。芯片策略依赖于复杂的高速互连协议,无论是自定义的还是其他的。目前英特尔芯片到芯片连接的使用要么是简单的内存协议,要么是FPGA结构扩展--像UPI这样的大型服务器CPU不一定能胜任这项任务。CXL可能是这里的未来,但是目前的CXL是建立在PCIe之上的,这意味着每个芯片都需要一个复杂的CXL/PCIe控制器,这可能很快就会耗电。
英特尔表示,他们正在发明新的封装技术和新级别的连接,以在硅之间发挥作用-目前还没有关于协议的披露,但英特尔承认,要达到这个级别的规模,它必须超越公司目前的规模,这将需要在这一领域创建标准和创新。目标是创建和支持标准,第一个版本将内置一些标准化。英特尔表示,这是一种极端分解的方法,并且要注意,并不是所有连接的东西都必须是高带宽(例如USB)或一致的互连-英特尔认为这一目标涉及整个频谱中的几个协议。
还有开发者市场,它可能习惯于在任何给定的产品中实现更同质化的资源。如果没有仔细的规划和相关的编码,例如,如果开发人员期望一定的计算与图形比率,则某些芯片配置可能会崩溃。这不是OneAPI可以轻松修复的。
这些都是英特尔必须解决的问题,尽管要实现这一目标还需要几年时间。我们被告知内部名称是Client 2.0,尽管随着英特尔开始更详细地讨论它,它可能会增加更多的营销手段。
发表评论,这里唯一的缺点是,英特尔并没有太多地谈论将其捆绑在一起的胶水。";嗯.。你显然错过了EMIB和Foveros的最后几年?更不用说已经使用这些互连的所有产品了?另外-->;称Emib和Foveros为胶水,与AMD 1970年的时代相比,塑料中的铜痕迹就像是把太空X龙2称为水星1号一样的另一个太空舱。
回覆。
你混合了两种不同的东西:你谈论的是胶水在层与层之间的垂直粘合。伊恩说的是芯片到芯片的通信。如果你了解AMD技术,想想像Infinity Fabric这样的东西。顺便说一句,英特尔有过一次使用胶水的经历--看看凯比湖G,里面有织女星芯片。在这种情况下,它只是一个简单的PCIe连接(而且也不是一个快速的连接)。回覆。
确实如此。[/Tealc][/Tealc]没有沟通的基础,英特尔在这里空穴来风。看看AMD的无限结构的功率预算,当它涉及到核心和非核心。当小芯片的数量增加时,非核心功率预算也会增加(并且离线性也不远)。Https://www.anandtech.com/show/13124/the-amd-threa...。英特尔的许多小芯片策略(特别是在没有魔法通信系统的情况下)将耗尽每个小芯片上的全部电力预算,彼此交谈时会说:“我没有可用的电力来做任何工作。”(英特尔的许多小芯片策略(尤其是在没有魔法通信系统的情况下)将耗尽每个小芯片上的全部电力预算。回覆
就好像AMD或英特尔会为小批量部件提供自定义互连一样?回覆。
Kaby Lake-G上的EMIB用于将GPU连接到内存,而不是CPU连接到GPU。Https://www.extremetech.com/wp-content/uploads/201...。Https://www.techspot.com/review/1654-intel-kaby-la...。回覆。
Hetzbh是对的。我指的是交换矩阵互联,而不是芯片到芯片的连接。它在下一句话和段落的其余部分逐字逐句地讨论高速交换矩阵协议。仅仅在上下文中仅提到物理互连本身就有点奇怪。此外,在我的文章中,我详细介绍了英特尔正在开发的所有不同级别的物理互连,您已经在我的文章中发表了很多评论。从字面上看,下面的相关阅读部分是我关于这些主题的几篇文章。你到底想愚弄谁?回覆。
所有的节目,这一次他们找人做新的BS幻灯片,让它看起来很新鲜。还有一些新的闪闪发光的垃圾可以炫耀。Dafaq是游戏玩家和创作者的芯片设计,在人工智能的基础上,你会把什么样的人工智能塞进英特尔,那个带有Big Little垃圾的英特尔硬件调度器,以弥补巨大的核心SMT性能?伙计,他们真的没有想法,伊恩关于哪种胶水的方面在这里非常合适,我们知道AMD处理器在Infinity结构方面有局限性,IMC如何在整个Ryzen芯片上与缓存和其他IP一起工作,以及AMD是如何在学习的过程中改进它的,我们知道AMD处理器在Infinity结构、IMC如何与整个Ryzen芯片上的高速缓存和其他IP一起工作,以及AMD如何在学习过程中改进它。英特尔没有显示它们,产品在哪里,复制AMD是他们现在正在做的事情,芯片设计,现在这个,还有什么,等待7纳米?XE被外包给台积电,如果失败了,那么Raja就可以退休了。让我们看看Ice Lake在至强平台上首先提供了什么,以及RKL希望如何与他们的5.0 GHz时钟相关,但由于耗电的14 nm++设计上的不可伸缩环形总线导致内核数量较少,14 nm++肯定是一项技术壮举,在7 nm上与AMD部件竞争,但现在它已经很老了,SMT的性能已经受到了打击。回覆。
他们现在正在做的就是复制AMD,嘿,这让他们在AMD64天里保持了相关性,并为他们赢得了足够的时间,让他们通过工程走出了他们挖的奔腾4号形状的洞。也许这次也能救他们一命。回覆。
这个关于芯片、Intel AMD等人的演讲让我想起了我第一次安装RS/6000。5个筹码,我想...。嗯,维基上说90年代早期的多芯片版本(当时我参与了)至少有6个芯片。成本较低的RIOS.9配置有8个离散芯片-一个指令缓存芯片、一个定点芯片、一个浮点芯片、两个数据缓存芯片、存储控制芯片、输入/输出芯片和一个时钟芯片。";维基回复的想法也差不多



