根据芯片照片对8086算术/逻辑单元进行逆向工程
Intel8086处理器于1978年推出,开创了现代计算的进程。虽然x86处理器家族几十年来一直支持64位处理,但最初的8086是16位处理器,因此它具有16位算术逻辑单元(ALU)。1算术逻辑单元是处理器的心脏:它执行加法和减法等算术运算,也执行布尔逻辑运算,如按位AND和OR,以及位移位和旋转。由于快速的ALU对处理器的整体性能至关重要,因此ALU经常包含有趣的设计技巧。
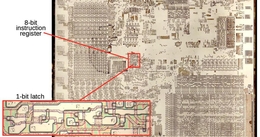
下面的芯片照片显示了8086处理器的硅芯片。ALU在左下角。其上方是通用和专用寄存器。左上角有一个用于地址计算的加法器。(为了提高性能,8086有一个单独的加法器,用于在访问内存时添加段寄存器和内存偏移量。)大型微码ROM在右下角。
8086死了,放大了算术逻辑单元的一位。这张照片去掉了金属层和多晶硅层,显示了硅层。
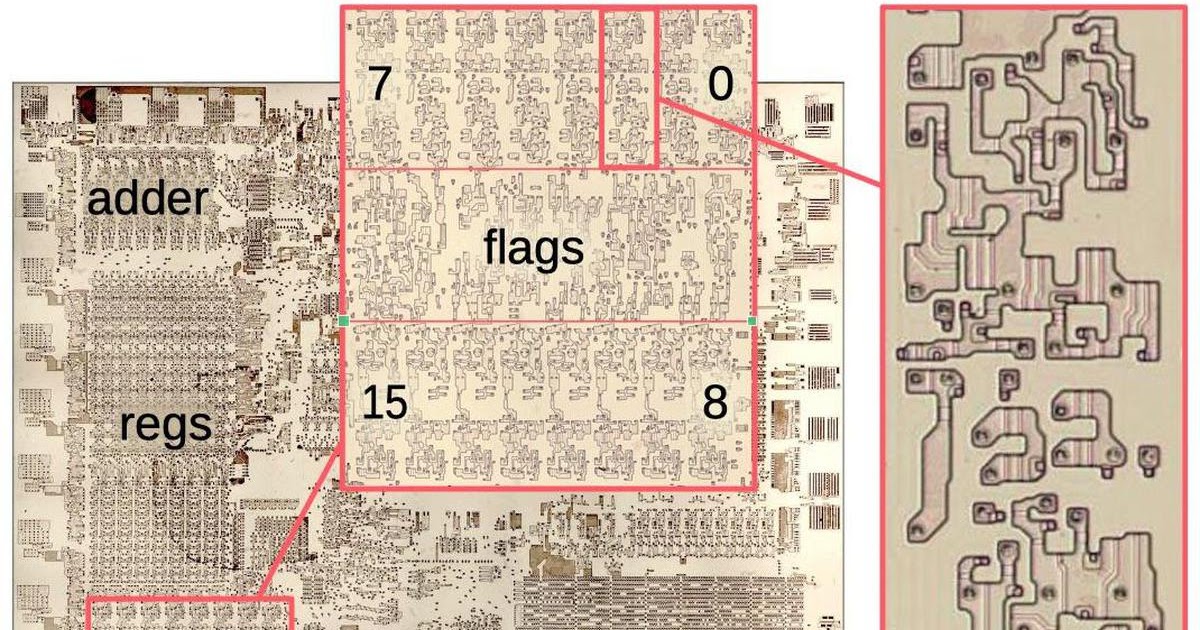
放大算术逻辑单元显示,它由16个几乎相同的级构成,每个位对应一个级。上行处理比特7到0,而下行处理比特15到8.3。在这两者之间,标志电路通过诸如零或非零、正或负、进位、溢出、奇偶校验等条件码来指示算术运算的状态。这些通常用于条件分支。
在这篇博客文章中,我对8086的ALU进行了反向工程,并解释了它是如何工作的。它比我研究过的其他老式算术逻辑单元要复杂得多,2使用了可以实现任意位功能的灵活电路。进位是用曼彻斯特进位链实现的,这一快速设计可以追溯到20世纪60年代的一台超级计算机。
8086';的算术运算单元电路有点棘手,所以我将首先解释它是如何将两个数字相加的。如果你学过数字逻辑,你可能会熟悉全加器,这是一个用来加二进制数的积木。具体地说,一个全加器需要两位和一位进位。它将这三位相加,并输出1位和以及进位输出位。(例如,二进制形式的1+0+1=10,因此进位输出为1,而和位为0。)16位加法器可以通过连接16个全加器来创建,其中一个全加器的进位输出馈入下一个全加器的进位输入。
下面的简图表示ALU加法器的一个阶段。它接受两个输入和进位输入,并对它们求和,形成一个1位和输出和一个进位输出。(请注意,进位信号从右向左移动。)和位输出是通过两个自变量和进位的异或产生的,使用底部的两个异或门。然而,产生进位更为复杂。
8086算术逻辑单元的简图,说明它是如何执行加法运算的。两个晶体管控制进位输出。
进位计算使用一种称为曼彻斯特进位链4的优化,可追溯到1959年,以避免当进位从一个阶段波动到下一个阶段时的延迟。其思想是并行地决定每个阶段是生成进位、传播现有进位还是阻塞进入的进位。然后,进位可以快速流经进位链。没有顺序求值。为了理解这一点,考虑一下添加两位和进位时的情况。对于0+0,无论任何进位,都不会进位。另一方面,无论任何进位,加1+1总是会产生进位;这种情况称为进位生成。有趣的情况是0+1和1+0;如果有进位,就会有进位。这种情况被称为进位传播,因为进位不变地通过级传播。
在曼彻斯特进位链中,进位传播信号打开或关闭进位线中的晶体管。在进位传播情况下,激活顶部晶体管,将进位输入连接到进位输出,从而进位可以流过。否则,激活下位晶体管,进位输出接收进位生成信号,如果两个自变量都为1,则生成进位。由于这些晶体管都可以并行设置,进位计算较快。当进位信号流经进位中的晶体管时,仍然存在一定的传播延迟。5个。
这解释了ALU是如何执行加法的,6但是逻辑功能呢?它如何计算AND、OR或XOR?假设您将进位传播XOR门替换为逻辑门(AND、OR或XOR),并将进位生成门替换为0,如下所示。输出将只是两个参数的AND(或OR或XOR),具体取决于新的门。(右侧的XOR门无效,因为使用0的XOR传递的值不变。)关键是,如果您可以用某种方式替换这些门,相同的电路就可以计算AND、OR和XOR。
为了计算逻辑函数,(在概念上)用不同的逻辑门替换XOR门,并且阻止进位生成。
另一个重要的操作是位移位。ALU通过以一种不寻常的方式利用进位线将值向左移位(如下所示)。7来自第一个自变量的位直接进入进位输出,向左发送一个位位置。接收到的进位位通过异或门,导致左移位一位。进位传播信号被设置为0;这既指示自变量位进位,又将异或门变为直通。(右移位由单独的电路实现,如下所述)。
向左移位一位利用进位线向左传递每一位。
因此,通过对具有不同功能的进位传播门和生成门进行重新编程,ALU可以重用该电路来执行各种操作。但是这些神奇的可重编程门是如何实现的?诀窍在于,任何两个变量的布尔函数都可以由真值表中的四个值指定。例如,并且具有下面的真值表,因此它可以由四个值指定:0,0,0,1:
如果我们将这些值送入多路复用器,并根据两个输入选择期望的值,我们将得到输入的AND,如果我们将0,1,1,0送入多路复用器,我们将得到输入的异或,其他输入也同样产生其他逻辑函数,有了合适的值,任何两个变量的逻辑函数都可以实现。8(一些特殊情况:0,0,0,0将输出常量0;而0,0,1,1将输出输入A。此多路复用电路用于进位传播门。进位产生门使用类似的半大小电路。9个
现在我已经介绍了背景,下面显示了完整的ALU电路,多路复用器取代了进位传播和生成门。在芯片上,进位输入和进位输出是颠倒的,这反映在下面。原理图还显示了从ALU到总线的连接,输出结果。底部的电路支持右移位操作,这不适合ALU的一般电路。对于这篇博客帖子,I';不适合于ALU的一般电路。对于这篇博客文章,I';还显示了从ALU到总线的连接,输出结果。底部的电路支持右移位操作,这不适合ALU的一般电路。对于这篇博客文章,I'。10个。
那个时代的8086和其他处理器是由一种叫做NMOS的晶体管建造的。硅衬底是通过砷或硼的扩散掺杂形成导电硅和晶体管的。在硅的顶部,多晶硅布线将晶体管和布线元件的栅极结合在一起。最后,顶部的金属层提供了更多的布线。(相比之下,现代处理器是由结合了NMOS和PMOS晶体管的CMOS技术建造的,它们有很多层金属布线。)。
上图显示了NMOS晶体管的结构,该晶体管可以看作是一个开关,允许电流在称为源极和漏极的两个扩散区域之间流动。晶体管由栅极控制,栅极由一种称为多晶硅的特殊类型的硅制成,栅极上的高电压使电流在源极和漏极之间流动,而栅极上的低电压阻止电流流动。
最简单的逻辑门是反相器;下图显示了反相器是如何由NMOS晶体管和电阻器构成的。11粉红色区域为掺杂硅,棕色线为顶部的多晶硅布线,多晶硅线与掺杂硅相交形成晶体管。当输入为低时,晶体管关闭,因此上拉电阻将输出拉高;当输入为高时,晶体管接通。这将输出连接到地,将输出拉低,从而使输入信号反转。
更复杂的门,如下面的2输入NOR门,使用类似的原理,当输入较低时,晶体管关断,因此上拉电阻将输出拉高。如果任何一个输入为高,相应的晶体管就会导通,并将输出拉低。因此,该电路实现了NOR门。芯片布局与原理图匹配,但由于节省空间优化,外观复杂。您可能会认为晶体管是简单的矩形,但硅区形状不规则,以最大限度地利用空间。此外,其他晶体管(不属于NOR门)共享接地以节省空间。
在8086';的算术逻辑单元中实现的NOR门。这张照片的金属线已经被移除,显示了下面的硅和多晶硅。
多路复用器是使用一种完全不同的技术构建的:传递晶体管。传递晶体管不是将输出拉到地面,而是将输入信号传递到输出。在多路复用器中,每个输入连接到不同的一对晶体管。根据自变量,正好有一对晶体管将两个晶体管都打开。例如,如果arg2为0,arg1为1,则左上角的晶体管对将ctl01连接到输出。其他每一个输入都将被。将其传递到输出。(这种传递晶体管方法比用标准逻辑门构建多路复用器更紧凑。)。
下图显示了一个标有主要组件的ALU级。您可以看到前面所述的反相器、NOR门和多路复用器。其他组件使用类似的技术实现。此图可以与较早的原理图进行比较。略带红色的水平线是金属层的残余,在此照片中去除了金属层。这些线路传输控制信号、电源和地。
下图(取自8086专利)显示了ALU如何通过ALU总线连接到处理器的其余部分。上面的讨论涵盖了图中间的全功能ALU,它接受两个16位输入并产生16位输出。这些输入由三个临时寄存器提供:A、B和C。(这些临时寄存器对于程序员是不可见的,不应与8086的AX、BX和CX寄存器混淆。稍后我将提到这些寄存器的几个重要特性。任何寄存器都可以提供ALU的第一个输入,但第二个输入总是来自B寄存器。这些寄存器与ALU总线有双向连接,因此可以写入和读取。ALU的一个不同寻常的特点是,它通过ALU总线与8086的其余部分有一个单一的数据连接。12这似乎是一个瓶颈,因为加载寄存器需要两个时钟周期,然后需要另一个时钟周期来访问结果。但显然,这辆单人巴士对8086来说已经足够好了。
上面所示的处理器状态字(PSW)保存条件标志、ALU结果上的状态位:零、负、溢出等等。虽然PSW在上图中看起来微不足道,但文章顶部的芯片照片显示,它约占ALU电路的三分之一。由于其复杂性,我将把标志电路留到后面讨论:每个标志都有处理许多特殊情况的独特电路。
下面的示意图显示了ALU临时寄存器的反向工程实现的一位。寄存器由锁存器实现;每个框代表一个锁存器,即一个保存一位的电路。两个大的AND-NOR门充当多路复用器,选择其中一个锁存器的输出。上部门选择一个寄存器进行读取。下部门选择其中一个寄存器作为ALU的自变量。
虽然6输入AND-NOR门多路复用器看起来可能很复杂,但使用NMOS晶体管实现起来很简单。该原理图显示了它是如何由6个晶体管和一个上拉构成的。您可以验证,如果一对中的两个晶体管都通电,则输出将被拉到地,从而提供AND-NOR功能。
锁存电路如下所示。我已经详细地写过8086的锁存器,所以我将给出一个简单的总结。锁存器的想法是它可以稳定地保持0或1位。当时钟信号为高时,上部晶体管导通,将逆变器连接成环路。如果第一个逆变器的输入为1,则它输出0到第二个逆变器,第二个逆变器输出1,因此它们保持在该状态。
这个锁存器的特别之处在于它是一个动态锁存器。当时钟信号CLK&39;为低时,环路中断,但是由于导线和晶体管的电容,第一个反相器上的输入保持不变。当CLK&39;再次变高时,该电压被刷新。或者,当CLK&39;8086使用动态锁存器,因为锁存器紧凑,只使用两个晶体管和两个反相器。锁存器用硅实现,如下所示。
下图总结了临时寄存器实现的组件。该电路重复16次以完成寄存器。13寄存器的输出馈送到前面描述的ALU电路。
ALU使用三个临时寄存器来保存参数。此图显示了One Bit的实现。
Intel8086虽然电路复杂,但其特点足以在显微镜下进行研究。算术逻辑单元是处理器的关键部件,占据了芯片的很大一部分。通过仔细的检查,可以对其电路进行反向工程,揭示了其有趣的结构。它使用曼彻斯特进位链进行快速进位传播。进位产生和进位传播信号是由多路复用器产生的,多路复用器用作任意函数发生器,用少量电路构成灵活的ALU。ALU是由。
您可能已经注意到,8086的ALU不支持乘法、除法或多位移位,即使8086有用于这些操作的指令。这些操作是在微码中使用更简单的ALU操作(用于乘法和除法的移位、用于乘法和除法的减法,以及用于较大移位的重复的单位移位)来计算的。
ALU的一些功能仍有待描述,特别是条件标志和ALU控制信号是如何从操作码生成的。我计划很快写下这些内容,所以请在Twitter@kenshiriff或RSS上关注我以获取更新。
ALU大小几乎总是与处理器字长匹配,但也有例外。值得注意的是,Z-80是一个8位处理器,但有一个4位ALU。因此,Z-80的ALU对每个算术运算运行两次,一次处理一半字节。一些早期的计算机使用1位算术逻辑单元来降低成本,但这些串行处理器速度很慢。-↩。
我已经研究了其他各种早期微处理器的算术运算单元,包括8008、Z-80和8085。我还对74181和AM2901算术运算单元芯片进行了逆向工程。-↩。
ALU';此布局是数据路径中位排序的结果:位是交错的15-7-14-6-...-8-0,而不是线性的15-14-...-0。这种交错背后的原因是,通过交换位对,可以很容易地交换16位字中的两个字节。ALU被分成两行,以便它适合可用的水平空间。即使使用高而窄的布局,也可以很容易地交换16位字中的两个字节。即使是在高、窄的布局中,也可以很容易地交换16位字中的两个字节。ALU被分成两行,以便它适合可用的水平空间。即使对于高而窄的布局,这种交织背后的原因是它使得交换16位字中的两个字节变得容易。算术运算单元的一位比寄存器文件的一位宽。将算术运算单元拆分成两行可以保持位间距大致相同,从而避免了寄存器堆和算术运算单元之间的长导线。-↩。
曼彻斯特进位链是由曼彻斯特大学开发的,并在1959年的“数字计算机中的并行加法:一种新的快速进位电路”一文中进行了描述。它用于阿特拉斯超级计算机(1962年)。-↩。
算术逻辑单元还使用跳跃进位技术来加速进位计算;i';例如,如果比特8有进位输入,并且进位传播被设置为比特8、9、10和11,则可以立即确定比特12有进位输入。因此,通过将进位输入和四个进位传播值进行AND运算,可以立即计算比特12的进位输入。类似的跳跃进位电路允许进位从位2跳到位4,以及从位4跳到位8。这些跳位进位电路减少了ALU';最坏情况下的计算时间。跳跃进位电路解释了为什么算术逻辑单元中的每一级都相似但不完全相同。请注意,对于逻辑运算或移位,进位传播或进位生成为0,因此跳跃进位不会激活和破坏结果。↩
我应该提一下减法是如何处理的。典型的ALU在加法之前将其中一个输入反转,重复使用加法电路进行减法。但是,8086的ALU通过改变多路复用器的输入来实现减法,如下所示。这利用了通用多路复用器,避免了实现单独的求反电路。(比较操作以减法实现,但不存储结果。如果差值为零,则值相等,而正差表示第一个值较大。)。
减法类似于加法,但第二个参数被否定。这是通过将进位生成AND门的一个输入反相并将进位传播XOR改变为XNOR来实现的。
处理器实现左移一位的典型方式是将值加到自己身上。我不知道为什么8086使用进位方法而不是加法。。↩。
FPGA(现场可编程门阵列)使用类似的技术来实现任意逻辑功能。真值表存储在查找表(LUT)中。这些查找表通常更大;6个输入的查找表有26=64个条目。FPGA和算术逻辑单元之间的一个不同之处在于,FPGA是编程的,然后门功能是固定的,而算术逻辑单元门可以在每次操作中改变功能。-↩。
如果参数1为0,则进位生成多路复用器返回0。换句话说,它只实现真值表的两种情况,并且有两个控制输入。为了处理另外两种情况,它被时钟信号拉低,因此输出为0。因为它是由时钟驱动的,并且取决于电路电容保持的值。
.