知识图嵌入的深度学习
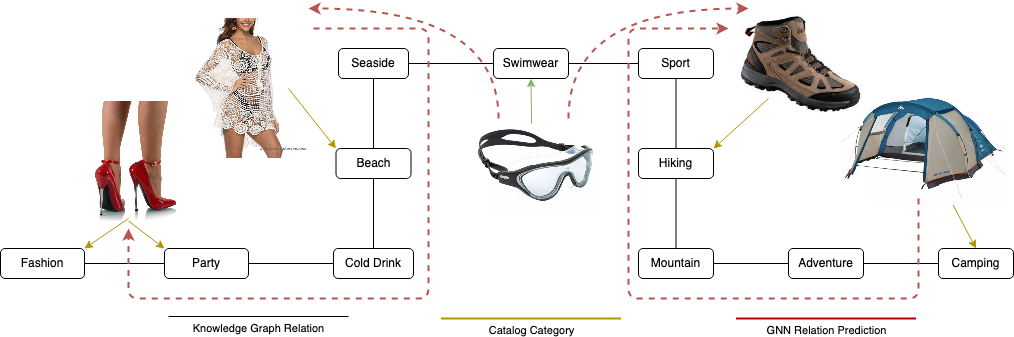
是什么让行李箱里一双时髦的鞋子和一件泳衣不容错过,为周末去海滩做准备?为什么不在刚买的徒步旅行靴中一键预订在白云山露营,因为你喜欢冒险呢?发明这些建议的系统可能利用了网络的力量,我们集体生活的隐喻,以及它的所有复杂性和纠结的依赖关系。
特别是,两种类型的网络,数据网络和人工神经元网络结合在一起,为各种有趣的应用开辟了道路。数据网络的典型例子包括社会网络和知识图,而另一方面,基于神经网络的一类新的机器学习任务在过去几年中已经成长起来。这种深度学习技术的谱系属于图形神经网络(GNN),它们可以揭示隐藏在图形数据中的洞察力,用于分类、推荐、问题回答和预测实体之间的新关系。你想知道更多关于他们的事吗?
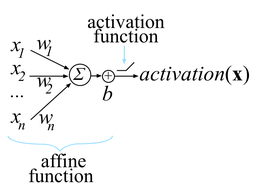
当我们谈论机器学习任务时,我们指的是一组找到输入和输出之间相关性的算法。输入基本上是一个数字列表,也称为矢量化要素:
知识图中节点的矢量表示应最大限度地保留压缩在低维空间中的单个节点自身属性中携带的信息。换句话说,嵌入(矢量化表示的名称)应该用向量标识相关符号,并且这样的向量应该尽可能小。本文的目的是要找到一种合适的方法从知识图中生成良好的嵌入。
为了在下游机器学习任务中有用,嵌入不仅应该识别相关的符号,而且应该具有重要的属性。根据最喜欢的距离函数,对于我们定义的任何“相似性”标准,彼此相似的符号都应该与同样相似的嵌入相关联。在上面的示例中,徒步旅行嵌入与山上而不是海边的关系更密切。嵌入对于那些在自然语言处理中实践的人来说是非常熟悉的,它们是基于“一个词的特征是它所保持的伙伴(R.Firth)”的原则,并且采用跳跃语法技术来预测被给定的前辈和后继者集合包围的最有可能的词。应用于一个庞大的语料库,训练好的跳文法(或其互补弓形)网络将包含满足相似性质的嵌入。
虽然文本中的单词严格按顺序排列(一个前导节点和一个后继节点),但在图中,一个节点可能包含多个关系,似乎这还不够,这些关系可能会彼此不同。表征学习蓬勃发展,新的学习方法不断涌现。
此后,我将只介绍两种在图中生成嵌入的技术。为了便于统计,我在Scala中实现了Deepwalk和Graph卷积网络(GCN),其中ND4J用于矩阵,Deeplearning4J作为神经网络框架。
Deepwalk(及其后继的Node2Vec)是一种无监督算法,是图形表示学习领域中最早的算法之一,它的设计简单,因为它在捕获拓扑和内容信息方面非常有效。原则上,它等同于前面提到的跳转语法,但是图形结构如何匹配文本中的单词流序列呢?该算法从任何选择的节点开始,以受控的随机方式访问其邻居和整个网络。随机游走在两种不同的方法之间进行平衡,这两种方法在一种情况下强调紧密相关节点的差异,而在另一种情况下强调距离较远的群集之间的差异。第一种方法是广度优先搜索(BFS),它相对于前一个节点在当前节点的兄弟节点中选择要访问的下一个节点。第二种方法是深度优先搜索(DFS),它从与当前节点相连的节点中选择新节点。第一种方法与当前节点的所有邻居保持一致,而第二种方法倾向于深入探索网络。
图形卷积网络,顾名思义,与卷积神经网络算法有一些共同之处,而卷积神经网络算法引领了视觉识别的巨大飞跃。如果一个带有节点和边的图在二维相邻矩阵中被转置,没有什么可以阻止我们运行滑动窗口函数来压缩像素网格并提取特征,就像CNN所做的那样。与CNN的亲和力到此为止,因为当我们细化图像时,我们更感兴趣的是复杂的视觉特征,而不是单个像素,而在知识图中,我们希望在单个节点中卷积它的邻居,并递归地处理整个网络的信息。
GCNS背后的原理将其基础建立在几十年前魏斯费勒-雷曼测试中描述的一种方法上。该测试确定两个任意图是否同构,即它们具有完全相同的结构。根据算法,所有节点都使用相同的值进行初始化,让我们将数字1作为所有节点的初始化值。然后,将该值加上其邻居的值分配给该节点,并迭代此步骤。正如您可能认为的那样,在第一轮中,节点已经包括了第一级邻居的信息,但是在第二次迭代中,节点将获得第二行节点的提炼概念,依此类推,随着迭代的进行。测试将确认同构,即在任意次数的迭代之后,节点的当前值的分区是否没有改变。尽管最终校验与GCNS无关,但该方法提供了在节点之间迭代卷积信息的方法。
Kipf&;Well(ICLR 2017)中描述了GCN方法,该方法属于消息传递方法家族,而对于“消息”,我们只打算使用单个节点的内容,而“传递”是渗透到整个网络中的卷积。在Weisfeiler-Lehman测试中,传递信息的方式只是简单的值之和,而在GCNS中,卷积依赖于频谱传播规则。这是什么传播规则?让我们假设我们知道图的结构(节点和关系)和所有节点的内容(特性)。传播规则采用线性矩阵乘法,但为了不引起下游任务中梯度的消失或爆炸,对特征进行归一化,并在邻接矩阵中添加自环。
我用小的空手道数据集、一组假的节点特征(只是一个对角线矩阵)和一组随机的权重创建了一些实验。我在下面的图像中按顺序重复了4次实验(没有挑剔),在运行光谱算法的2次迭代后,节点的颜色表示它们的相似性。
结果显然是令人惊叹的!这两个集群还没有细化,但正如您可以看到的,图(D)几乎与我们使用Deepwalk获得的结果完全相同!这些嵌入仅用随机权重和2次递归迭代来详细说明。为什么不应用一些学习机制来精炼几个示例的集群呢?
我开始写这篇文章是关于你的电子商务如何根据你的客户的假期偏好推荐新商品,我将用一个更相关的数据集进行一些实验。如果您不熟悉ConceptNet,它是一个包含3400万个节点、34种不同关系(我用ConceptNet了解其他想法,请查看它们!)的庞大的一般事实图形数据库。我把它完全转换成了猫头鹰数据库。关于我们感兴趣的主题,山和海边,我提取了大约3000个节点。然后,我用谱传播规则创建了一个两层神经网络。我用邻接矩阵、节点名称的单词嵌入作为输入特征和一些标记节点,总共4个,其中2个节点被归类为“海边”类,2个节点被归类为“山”类,另外2个节点被归类为“海边”类,2个节点被归类为“山”类。有2个类别的4个标签节点是我对3000个标签中所有其余标签进行分类所需的全部。就整个数据集而言,这是4/3000标签条目的比率,不是很有趣吗?这就是半监督学习这个名字的原因。
这种分类方法确实很快,但也有一些缺点。频谱传播规则考虑了邻接矩阵,邻接矩阵是二维矢量中的整个网络。对于相对较小的数据集,这不是问题,但当涉及到真正的大数据时,这种方法实际上是不可行的。FastGCN应运而生,可以扩展到大尺寸的图形数据库。