我的实习经历:使用精简词典进行Brotli压缩
Brotli是一种最先进的无损压缩格式,所有主流浏览器都支持它。它能够实现比无处不在的gzip好得多的压缩比,并且正在迅速流行起来。CloudFlare尽可能使用Google brotli库来动态压缩Web内容。2015年,我们深入研究了brotli的工作原理及其压缩优势。
在文本Web内容压缩的上下文中,brotli文件格式的一个更有趣的特性是包含了一个内置的静态词典。该词典相当大,除了包含多种语言的各种字符串外,它还支持对这些单词应用多个转换的选项,从而增加了它的通用性。
开源的brotli库实现了brotli的编码器和解码器,它为编码器预定义了11个质量级别,更高的质量级别需要更多的CPU来换取更好的压缩比。由于静态字典功能的CPU成本较高,因此从级别5开始有限地使用,并且仅在级别10和11全面使用。
我们对有限字典使用方法进行了改进,并添加了优化以在压缩Web内容时以可忽略的性能影响改善5到9级的压缩。
Brotli主要使用LZ77算法来压缩其数据。我们之前关于Brotli的博客文章提供了一个介绍。
为了改进对文本文件和网页内容的压缩,brotli还包括一个静态的预定义词典。如果字节序列不能与使用LZ77的较早序列匹配,则编码器将尝试通过引用静态字典来匹配该序列,可能使用多个转换中的一个。例如,每个HTML文件都包含不能用LZ77压缩的开始<;html>;标记,因为它是唯一的,但它包含在brotli静态字典中,并将被替换为对它的引用。引用通常比序列本身占用更少的空间,从而减小压缩文件的大小。
这部词典收录了6种语言的13504个单词,长度从4到24个字符不等。为了改进对真实文本和Web数据的压缩,一些词典单词是Web内容中常见的短语(当前)或字符串(‘type=“text/javascript”’)。与通常的LZ77压缩不同,字典中的单词只能作为一个整体进行匹配。Brotli格式不支持在词典单词中间开始匹配,在单词结尾之前结束匹配,甚至扩展到下一个单词。
取而代之的是,该词典支持120个词典单词的转换,以支持更大数量的匹配并查找更长的匹配。转换包括添加后缀(“work”变为“work”),添加前缀(“book”=&>;“the book”),使第一个字符大写(";process";=>;&34;process";)或将整个单词转换为大写(“html”=&>;“HTML”)。除了使单词变长或大写的转换之外,Cut转换还允许缩短匹配(“Consistent”=>;“consistent”),这使得查找更多匹配成为可能。
在包含转换的情况下,静态词典包含1633,984个不同的单词--对于穷举搜索来说太多了,除非使用较慢的brotli压缩级别10和11。当使用较低的压缩级别时,brotli要么禁用词典,要么只搜索大约5500个单词的子集,以便在可接受的时间范围内找到匹配项。它还只考虑无法找到LZ77匹配项的位置的匹配项,并且只使用CUT变换。
我们对brotli字典的方法使用了比默认字典更大但更专业的字典子集,使用更积极的启发式算法来提高压缩比,而性能损失可以忽略不计。为了提供更专业的词典,我们从服务器向压缩器提供了内容类型提示,依靠Content-Type标头告诉压缩器它是否应该使用用于HTML、JavaScript或CSS的词典。未来,词典还可以通过主机代管语言进一步完善。
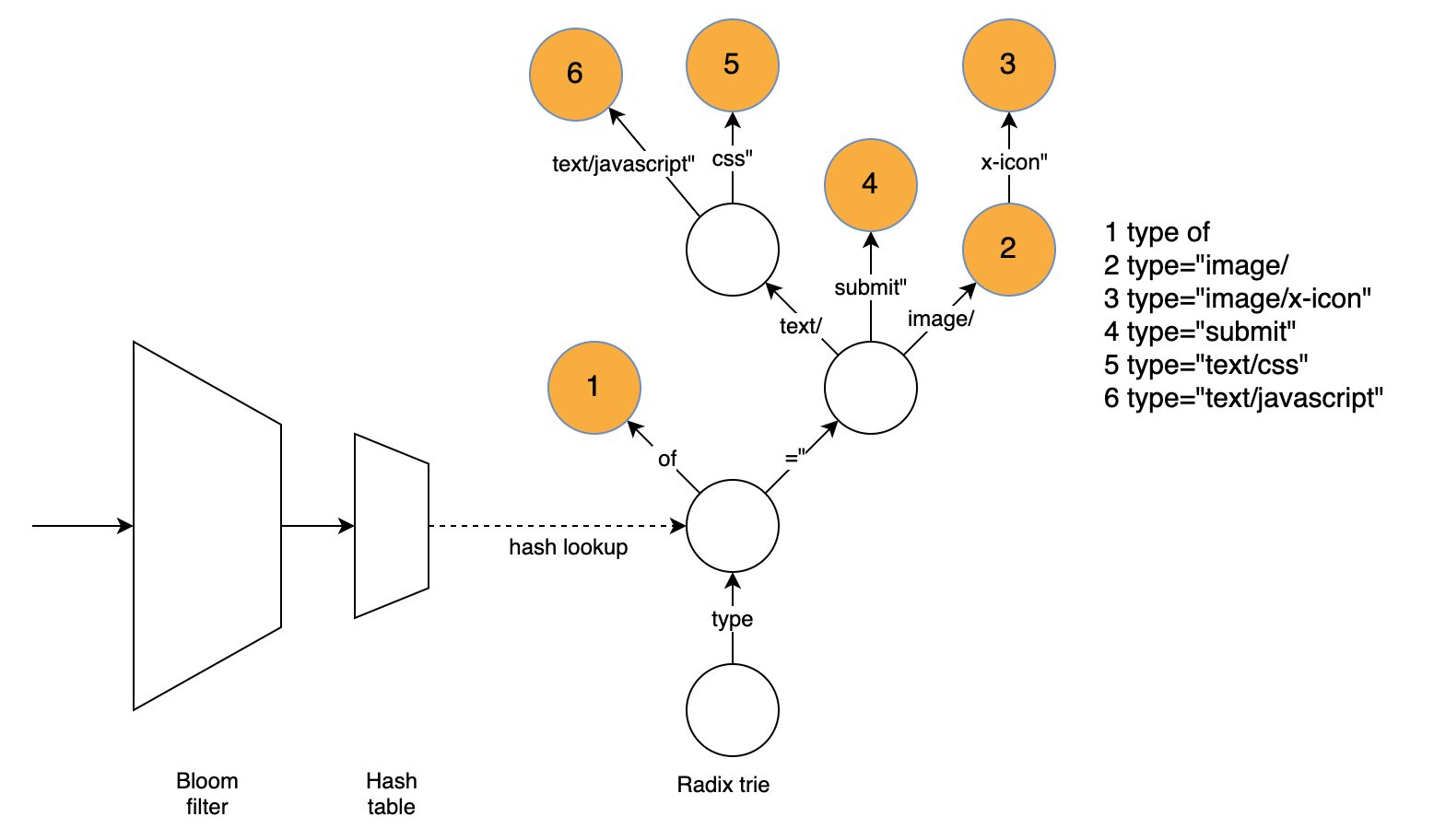
为了在不牺牲性能的情况下提高压缩性能,如果我们想要比brotli默认情况下更彻底地搜索字典,我们需要一种快速查找匹配的方法。我们的方法使用三种数据结构来直接查找匹配词。基数trie负责查找单词,而哈希表和Bloom filter用于加快基数trie的速度,并快速消除许多使用字典无法匹配的单词。
基数trie很容易找到最长的匹配词,而不必尝试匹配几个词。为了找到匹配项,我们根据当前位置的文本遍历图表,并记住具有匹配词的最后一个节点。基数trie支持压缩节点(具有多个字符作为边缘标签),这极大地减少了典型词典单词需要遍历的节点数量。
我们找不到匹配的大量位置减慢了基数Trie的速度。一个重要的发现是,大多数不匹配的字符串在前四个字节中都有一个不匹配的字符。即使对于存在匹配的位置,也会花费大量时间遍历前四个字节的节点,因为靠近树根的节点通常有很多子节点。
幸运的是,我们可以使用哈希表查找相当于四个字节的节点,如果存在则进行匹配,或者拒绝匹配的可能性。因此,我们查找字符串的前四个字节,如果有匹配节点,我们将从那里遍历trie,这样会更快,因为每个四字节的前缀通常只有几个相应的字典字。如果没有匹配节点,这个位置就不会有匹配词,我们就不需要进一步考虑了。
虽然哈希表的设计目的是快速拒绝不匹配,并避免缓存未命中和Trie中的高搜索成本,但它仍然面临类似的问题:我们可能会使用给定位置的哈希值搜索几个4字节的前缀,结果发现没有找到匹配。此外,由于缓存未命中,散列查找的成本可能很高。
为了快速拒绝与词典不匹配但仍可能导致缓存未命中的单词,我们使用k=1的Bloom过滤器来快速排除大多数不匹配的位置。在k=1的情况下,过滤器只是一个查找表,其中有一位指示对于给定的散列值是否存在任何匹配的4字节前缀。如果给定位的散列值为0,则不会有匹配。由于布隆过滤器对每个四字节前缀最多使用一位,而哈希表需要16字节,因此缓存未命中的可能性要小得多。(结构的实际大小略有不同,因为两个结构中都有许多空白空间,而Bloom过滤器有两倍的元素来拒绝更多不匹配的位置。)
这对性能非常有用,因为Bloom Filter查找只需要一次内存访问。Bloom过滤器的设计既快速又简单,但仍会拒绝一半以上的非匹配位置,从而使我们可以省去完整的散列查找,这通常意味着缓存未命中。
只在某些位置搜索词典这也是使用股票词典来完成的,但我们的搜索力度更大。虽然股票字典只考虑LZ77匹配查找器找不到匹配的位置,但我们也根据Brotli成本模型考虑匹配较差的位置:LZ77匹配较短或当前位置和参考位置之间的距离较长的位置通常只提供很小的压缩改进,因此值得尝试在静态字典中找到更好的匹配。
只考虑最长的匹配,然后对其进行转换,而不是查找和转换某个位置的所有匹配,基数trie只给出最长的匹配,然后进行转换。这种方法会带来巨大的性能提升。在大多数情况下,这会导致找到最佳匹配。
只包含一些转换,虽然所有转换都可以提高压缩比,但我们只包含那些能够很好地处理数据结构的转换。在找到未转换的匹配项后,可以轻松地应用后缀转换。对于大写转换,我们在基数trie中包括单词的未转换版本和大写版本。前缀和剪切转换不能很好地处理基数Trie,因此不支持超过1个字节的剪切和前缀转换。
在低压缩级别时,Brotli从词典的13,504个单词中搜索~5,500个单词的子集,这对压缩有负面影响。要存储整个词典,我们需要在Trie中存储大约31,700个单词,考虑到ASCII序列的大写转换输出和散列中的大约11,000个4字节前缀。这会降低哈希表和基数trie的速度,因此我们需要找到适合Web内容的字典的另一个子集。
为此,我们使用了包含代表性内容的大型数据集。我们确保使用来自世界多个地区的网络内容,以反映语言多样性并优化压缩。基于这个数据集,根据Brotli成本模型,我们确定了哪些单词是最常用的,并导致了最大的压缩改进。我们只收录基于这个计算的最有用的单词。此外,如果某些单词根据其散列值降低了对其他更常用单词的散列表查找速度,则会删除这些单词。
我们已经为HTML、CSS和JavaScript内容生成了单独的字典,并使用MIME类型来标识要使用的正确字典。我们目前使用的词典包括整个词典的15%-35%,包括大写转换。根据数据类型和所需的压缩/速度权衡,字典大小的不同选项可能会很有用。我们还开发了自动收集有关匹配的统计信息并基于此生成简化词典的代码,这使得将其扩展到其他文本格式(可能是大多数非英语或XML数据的数据)变得容易,并为这类数据获得更好的结果。
我们在一个由HTML、CSS和JavaScript文件组成的大型数据集上测试了缩减后的词典。
这一改进对于小文件来说尤其显著,因为LZ77压缩对它们的效果较差。由于对大文件的改进要小得多,所以我们只测试了256KB以下的文件。我们使用压缩级别5,与我们目前在边缘上用于动态压缩的压缩级别相同,并在英特尔酷睿i7-7820HQ CPU上进行了测试。
压缩改进被定义为1-(使用缩小字典的压缩大小/没有字典的压缩大小)。然后,对每个输入大小范围求该比率的平均值。我们还提供了按文件大小加权的平均值。我们的数据集反映了典型的网络流量,涵盖了大范围的文件大小,小文件更为常见,这解释了加权平均值和未加权平均值之间的巨大差异。
有了改进的字典方法,我们现在也能够压缩HTML、JavaScript和CSS文件,有时甚至比使用更高的压缩级别更好,同时只多使用1%到3%的CPU。作为参考,使用压缩级别6超过5会使CPU使用率最多增加12%。
压缩优化、速度和可靠性的职业生涯



