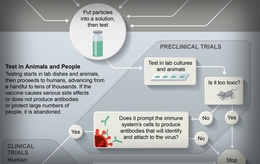
Facebook计划在人工审核之前使用机器学习对其审核队列进行排序,优先处理病毒式和潜在的严重内容

Facebook表示,它正在使用人工智能来优先处理潜在的有问题的帖子,供人类版主审查,因为它正在努力更快地删除违反其社区指导方针的内容。这家社交媒体巨头之前利用机器学习模型,主动删除低优先级内容,并将用户报告的高优先级内容留给人类审查者。但Facebook声称,它现在将用户和模特识别的内容合并到一个集合中,然后对其进行过滤、排名、重复数据删除,并将其交给数千名版主,其中许多人是合同工。
Facebook在节制方面继续投资的同时,有报道称,该公司未能阻止错误信息、虚假信息和仇恨言论在其平台上的传播。路透社(Reuters)最近发现了30多个页面和群组,这些页面和群组使用了关于罗辛亚难民和非法移民的歧视性语言。今年1月,西雅图大学(Seattle University)副教授凯特琳·卡尔森(Caitlin Carlson)公布了一项实验的结果,她和一名同事收集了300多条似乎违反了Facebook仇恨言论规则的帖子,并通过该服务的工具进行了报告。根据这份报告,只有大约一半的帖子最终被删除。最近,包括反诽谤联盟(Anti-Defamation League)、全国有色人种协进会(National Association For The Advantage Of Colorous People)和改变颜色(Color Of Change)在内的民权组织声称,Facebook未能执行其仇恨言论政策。这些团体组织了一场广告抵制活动,1000多家公司在一个月的时间里减少了社交媒体广告支出。
Facebook表示,其人工智能系统现在给予Facebook、Instagram、Facebook Messenger和其他Facebook网站上迅速分享的潜在令人反感的内容更大的权重,而不是几乎没有分享或浏览量的内容。当报告或检测到与真实世界的危害相关的消息、照片和视频(如自杀、自残、恐怖主义和剥削儿童)时,它们的优先级高于其他类别(如垃圾邮件)。除此之外,包含类似于之前违反Facebook政策的内容的信号的帖子更有可能排在审核队列的顶端。
Facebook的系统使用一种名为“完整帖子完整性嵌入”(WPIE)的技术,可以吸收海量的信息,包括图像、视频、文本标题和正文、评论、光学字符识别图像中的文本、从录音中转录的文本、用户档案、用户之间的互动、来自网络的外部环境以及知识库信息。表示学习阶段使系统能够自动发现从数据中检测有害内容中的共性所需的表示。然后融合模型结合这些表示来创建数百万个内容表示或嵌入,这些内容表示或嵌入用于训练监督多任务学习和自我监督学习模型,这些模型标记每类违规的内容。
其中一个模型是XLM-R,这是一种自然语言理解算法,Facebook也在使用它通过其社区中心来匹配有需要的人。Facebook表示,XLM-R是在2.5TB的网页上训练的,可以在大约100种不同的人类语言之间进行翻译,它允许其内容审核系统跨方言学习,因此“每一次新的人类对违规的审查都会在全球范围内让我们的系统变得更好,而不仅仅是用审查者的语言。”(Facebook目前约有1.5万名内容评论员,他们总共会说50多种语言。)。
“值得注意的是,所有违反…的内容。Facebook的产品经理瑞安·巴恩斯(Ryan Barnes)周四对媒体表示:“我们仍在接受一些实质性的人力审查--我们正在使用我们的系统来更好地区分内容的优先顺序。”我们希望在违规内容不那么严重的情况下使用更多的自动化,特别是如果内容不是病毒式传播的,或者不是…的内容。很快就被很多人(在Facebook平台上)分享了。“。
多年来,Facebook在其许多部门一直在广泛地走向自我监督学习,即将未标记的数据与少量已标记的数据结合使用,以提高学习准确率。Facebook声称,其深度实体分类(DEC)机器学习框架在部署后的两年内使平台上的滥用账户减少了20%,其SybilEdge系统可以在不到一周的时间内检测到不到20个好友请求的虚假账户。在另一项实验中,Facebook的研究人员表示,他们能够训练一种语言理解模型,与1.2万小时的手动标记数据相比,仅用80小时的数据就能做出更精确的预测。
对于阳刚之气的预测,Facebook依赖于一个有监督的机器学习模型,该模型查看过去发布的帖子的例子,以及它们随着时间的推移累积的浏览量。模型标签不是孤立地分析视图历史记录
撇开男子气概预测不谈,Facebook断言,对自我监督技术的接受--以及内容的自动优先排序--让它能够更快地处理有害内容,同时让人类审查团队把更多时间花在复杂的决定上,比如那些涉及欺凌和骚扰的决定。在其他衡量标准中,该公司指出了其社区标准执行报告,该报告涵盖了2020年4月至2020年6月,显示该公司的人工智能检测到了2020年第二季度记录下的95%的仇恨言论。然而,目前还不清楚这在多大程度上是真的。
Facebook承认,《华尔街日报》报道中标注的许多内容将被给予较低的审查优先级,因为它不太可能像病毒一样传播开来。根据一起诉讼,Facebook未能删除那些协调8月底威斯康星州基诺沙致命枪击事件的人的页面和账户。非营利活动组织Avaaz发现,在过去的一年里,脸书上误导性内容的浏览量估计达到38亿次,医疗虚假信息(特别是关于新冠肺炎的信息)的传播速度超过了来自可靠来源的信息。巴布亚新几内亚的Facebook用户表示,该公司删除虐待儿童内容的速度很慢,或者未能删除。ABC Science在一个拥有6000多名粉丝的页面上识别出一张年轻女孩的裸照。
人工智能的能力是有限的,特别是在像表情包和复杂的深度假冒这样的内容方面。在Facebook的深度假冒检测挑战赛中,有2000多名参与者,超过3.5万人参与了这个表现最好的模型,与为这项任务创建的10万个公开视频的公开数据集相比,准确率只有82.56%。当Facebook发布仇恨模因数据集时,最准确的算法-Visual Bert Coco-达到了64.7%的准确率,而人类在数据集上的准确率达到了85%。这是一项基准,旨在评估消除仇恨言论的模型的性能。纽约大学(New York University)7月份发表的一项研究估计,Facebook的人工智能系统每天约有30万个内容审核错误。
Facebook人工智能模型和数据集的潜在偏见和其他缺陷可能会使问题进一步复杂化。美国全国广播公司(NBC)最近的一项调查显示,去年在美国的Instagram上,黑人用户被自动审核系统禁用账户的可能性比那些活动表明自己是白人的用户高出约50%。当Facebook不得不将内容版主送回家,并在隔离期间更多地依赖人工智能时,首席执行官马克·扎克伯格表示,错误是不可避免的,因为系统往往无法理解上下文。
撇开技术挑战不谈,一些团体指责Facebook的内容审核政策不一致、不明确,在某些情况下还存在争议,导致在删除辱骂帖子方面出现失误。据《华尔街日报》报道,Facebook经常不能迅速处理用户报告,不能执行自己的规则,允许内容--包括对“可怕的暴力”的描述和赞扬--继续存在,可能是因为它的许多版主距离遥远,没有意识到他们正在审查的内容的严重性。例如,根据《纽约时报》的一个数据库,今年夏天,与Qanon有关联的100个Facebook群以每周超过1.36万名新粉丝的速度增长。Qanon被FBI贴上了国内恐怖威胁的标签。
为了应对压力,Facebook在今年夏天和秋天实施了旨在打击违反标准的病毒式内容的规定。属于因违反其策略而被删除的组的成员和管理员暂时无法创建任何新组。Facebook在其推荐中不再包括任何与健康相关的群体,QAnon在该公司的所有平台上都被禁止。Facebook正在对违反其规则的政客帖子贴上标签,但不会删除。Facebook监督委员会是一个外部组织,它将就Facebook平台上应该允许哪些内容,不应该允许哪些内容做出决定,并影响先例。该委员会从10月份开始审查内容审查案件。
Facebook还采取了一种特别的方式来仇恨言论节制,以满足世界某些地区的政治现实。该公司在德国的仇恨言论规定比在美国更严格。在新加坡,Facebook同意在被政府认定为虚假的新闻报道上附加“更正通知”。在越南,Facebook表示,它将限制对被视为非法的“持不同政见者”内容的访问,以换取政府停止破坏该公司当地服务器的做法。
与此同时,有问题的帖子继续从Facebook的过滤器中溜走。在过去一周创建并迅速增长到近40万人的一个Facebook群中,呼吁在全国范围内重新计票2020年美国总统选举的成员交换了对所谓选举的毫无根据的指控
Facebook的克里斯·帕洛(Chris Parlow)是该公司版主工程团队的一员,他在简报会上表示:“这个系统是为了将人工智能和人类审查员结合起来,以减少完全错误。”“人工智能永远不会完美。”
成功打造AI卓越中心的最佳实践: 有关COE和业务部门访问的指南,请访问此处