Facebook工程:自动根本原因分析
根本原因分析(RCA)是修复任何错误的重要组成部分。毕竟,如果不深究问题,就无法解决问题。但是RCA并不总是那么简单,尤其是在像Facebook这样的规模上。当数十亿人在各种平台和设备上使用应用程序时,单个错误可以自行创建多个不同的问题,并且多个错误可以同时发生。
曾经有一段时间,应召唤的工程师不得不花费数小时甚至数天的时间来手动梳理错误报告,寻找可以帮助他们调试的模式。今天,他们可以使用Minesweeper,这是我们为使RCA自动化而开发的一种技术,可以根据其症状识别错误的原因。
基于Minesweeper的RCA是完全自动化和可扩展的,它以正式的统计概念为基础。我们使用Facebook应用程序的真实错误报告对Minesweeper进行的评估证明,它可以在几分钟内对成千上万的报告执行RCA,并且可以以85%的准确性确定错误的根本原因。
自开发以来,Minesweeper已成为Facebook抵御错误的第一道防线,并帮助我们防止了潜在的大规模中断影响我们应用程序上的人员。
每当有人通过Facebook应用程序报告错误时,错误报告系统通常会捕获该人在遇到该错误之前在该应用程序中执行的动作(或“事件”)的时间顺序跟踪。其想法是获取可能导致错误发生的原因的快照,例如以下示例:
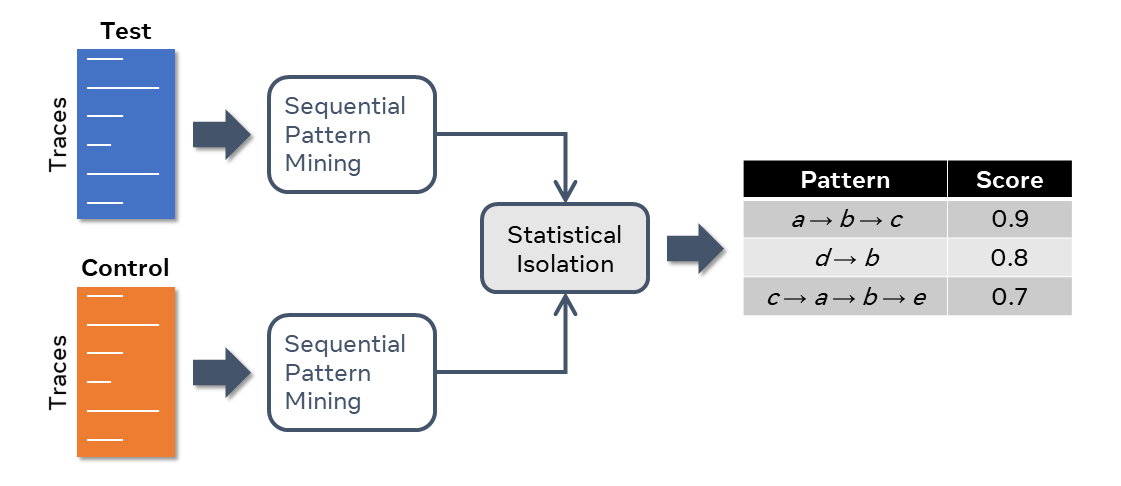
扫雷器扫描这些痕迹以寻找可能指出错误原因的独特模式。将包含错误的跟踪(测试组)与不包含错误的跟踪(对照组)进行比较。扫雷器发现了与对照组相比在统计学上与测试组不同的事件模式。这些模式可能与错误相关,因此可以指出其根本原因。
这是一个例子。假设(假设)有10个人正在使用Facebook应用程序。其中有五个人报告问题,并且在应用程序中跟踪了八个可能的事件(a,b,…到h)。在这些事件上,我们总共有10条痕迹,在测试组(T)中有5条来自遇到该bug的人,在对照组(C)中有5条来自其余没有发现该错误的人。
将Minesweeper应用于这些迹线时,首先要提取T和C中的顺序模式。顺序模式只是发生的事件的时间顺序,但不一定是一个接一个的发生(即,在它们之间可能存在其他不重要的事件)。
系统可以在此处提取的模式的一个示例是→c。对于每个模式,它计算在每个组(T和C)中出现的迹线数。在上面的示例中,此模式在T中出现了两次(t 1和t 2),因此在T中的支持为2。在这种情况下,在C中的支持也为2(t 7和t 8)。请注意,模式空间本质上是组合的,因此使用能够有效搜索该空间而不会发生指数爆炸的算法至关重要。
提取所有模式及其在T和C中的支持后,系统将执行统计隔离。对于每个模式P,它使用其支持来计算精度和召回率:
非正式地,精度描述了P在检测给定迹线是否在测试组而不是对照组中的精确度,而召回率则描述了测试组P可以覆盖多少。例如,图案b的精度为0.75,因为它总共出现在四条迹线上,其中三条在测试组中(即,它对测试组有75%的特异性)。召回率也为0.6,因为它出现在测试组的五分之三的痕迹中(即,它覆盖了测试组的60%)。
F1分数是两者的谐波平均值0.67。系统以这种方式计算所有模式的F1得分,并返回按F1得分排名的所有模式的列表,如下表所示。
在此示例中,结果显示模式b→c是排名最高的。在实际情况下,调试报告的工程师可以推断出按该顺序发生的事件b和c是可疑的,应进行仔细检查。
为了使Minesweeper能够在Facebook的规模和复杂性下工作,我们从数据挖掘社区借鉴了一个想法-顺序模式挖掘-来帮助跟踪事件在跟踪中出现的顺序。
在Facebook上,遇到成千上万与错误相关的痕迹并不罕见。为了解决这个问题,我们利用了PrefixSpan算法,该算法在顺序模式挖掘中非常高效,因此众所周知。为了根据模式对测试组的独特性对模式进行排序,从而对RCA有用,我们基于模式的精度和召回率利用了上述统计方法。最后,为了从可用性的角度使Minesweeper变得实用,我们解决了一些以人为中心的挑战,例如避免使用类似于解释根本原因的“冗余”模式。
Minesweeper在帮助Facebook的工程师分析和诊断回归(一组崩溃或错误报告中的突然尖峰)方面发挥了重要作用,在几分钟之内就可以提供洞察力,而这可能需要几天才能收集。由于Facebook应用程序的复杂性和产品发布周期,通常会同时进行多次回归,尤其是在发布新版本之后。但多亏了Minesweeper,从事面向用户回归的工程师可以对它们进行及时分析,从而使他们减少和减轻对Facebook服务的干扰比以往更加容易。
我们的论文“基于应用遥测的可扩展统计根本原因分析”提供了更多技术信息。