4K别名(2020)
如何提高您写入的软件的性能?将数据汇总到地址空间的连续区域是一种通常有用的方法,因为大多数程序都是对内存访问的瓶颈。整合对性能产生了积极影响,因为处理器在缓存行中获取数据,有两个原因。
连续和对齐的布局最小化存储程序数据所需的高速缓存行总数。
随后的操作数据已经在缓存行中的可能性增加了密集的布局。
这些好处是显而易见的,但是由于堆的布局,在使用JVM时从中获利需要一些工作。考虑在整个堆中铺设的Java对象是想到香肠;在内部和面包屑中,有一点肉。 Java对象具有定义大小的实现标题,通常为12个或16个字节,默认情况下对齐8个字节边界。这意味着如果您有一系列缠绕长期的对象数组:
甚至假设压缩引用,你最终结束了典型的香肠:12个字节的标题,八个字节为单词,四个字节的对齐阴影。这是33%的肉。
有关JVM对象布局的更多详细信息,请阅读内部的AlekseyShipilëv的对象。
如果您有包含这些WordMask对象的集合,这将在以前提到的两种方式影响应用程序性能:
需要解决三倍的内存并提取以处理整个集合而不是严格必要。
如果缓存行为64个字节,则八个龙可能适合,但只有两个整个WordMask对象。
围绕此方法 - 并且有很多关于它的方式 - 是转换对象图,以便您没有包装器的集合,而是一个数组的包装器:
假设再次压缩引用,这意味着您有12个字节的标题,四个字节的数组长度,数据,然后在末端浪费的相对空间浪费的相对空间可以忽略不计。这(虽然通常是堆)来提高性能。
我有一个名为多匹配器的玩具项目,给定一些分类规则,允许构建决策树,当查询时,将提供适用于输入对象的所有分类。对我的恐怖,我偶尔会听到那些人使用它或尝试。我写了关于它所的作用以及它在另一个帖子中的工作方式以及如何工作,但它并不重要。因此,我决定通过改进其数据的布局来提高其性能,并且可预见到比2x性能更好地提高其性能从整合获得。
在开始进入其他问题之前,您可以采取这种方法吗?一旦巩固了所有数据并增加了它在缓存中密集的可能性时,您可能希望利用SIMD。如果您启动的对象包含在内数组而不是单个字段:
多匹配器中的基本和非常简单的想法是为每个规则分配整数标识并通过约束来分解规则集。评估通过假设通过设置一点set的所有位来应用所有规则来开始.then ,从分类对象中提取值,并用于访问接受值的一组规则。该组与位设置相交。如果位设置变为空,则评估终止。当没有更多的值来提取时,位设置中留下的位是接受输入的规则。
long [] []面具;公共空白匹配(long [] stillmatching,int id){for(int i = 0; i< intermatching。长度; ++ i){stylmatching [i]& = masks [id] [i]; }}
Long []面具;尺寸;公共空白匹配(long [] stillmatching,int id){int offset = ID *大小; for(int i = 0; i< stillmatching。长度; ++ i){stylmatching [i]& = masks [i + offset]; }}
C2可以自动调制一些代码,例如上面的非常简单的循环。当它展开循环时,编译器对循环进行了一些分析,并且除了在归纳变量的值之外,不依赖于彼此的相同指令的通知块。有些说明块可以用特殊的说明书替换,这些说明书一次性地运行几个元素的载体;这取决于矢量对应指令的可用性。当这是成功的时,代码要快得多,并且当输入数据处于缓存中时特别有效。 Vladimir Ivanov在主题上幻灯片。
我碰巧知道C2的自动传输有一个限制,当时arrays.i知道这一点,因为我遇到了它调查了一个弱矩阵乘法基线和vladimir实际上在评论中解释了什么问题:
“关于C2自动矢量化问题,它是当前实现的限制:如果索引的不同,编译器无法证明不同的矢量化访问不会别名,所以它放弃了保持正确性(如果发生混叠,则不同的内存访问可以重叠干扰可观察到的可观察行为)。
Java中的任务比C / C ++更简单,但仍然必须证明源/目标阵列是不同的对象。
有一个开发标志-xx:+ superwordrtdepcheck(产品二进制文件中不可用,需要JVM重新编译),但它错过了正确的实现(PTR比较),只需在这种情况下启用矢量化。“
评论没有生存迁移我的博客到GitHub页面,但我仍然在我的电子邮件收件箱中并直接从像Vladimir这样的专家那样获取信息。
这意味着什么只有上面的代码只能在阵列肯定不同或者如果向量宽度划分偏移量时,只能安全地被安全地复制。如果有偏移量,则编译器需要证明阵列不同,而是C2刚刚放弃而不是做错了什么。
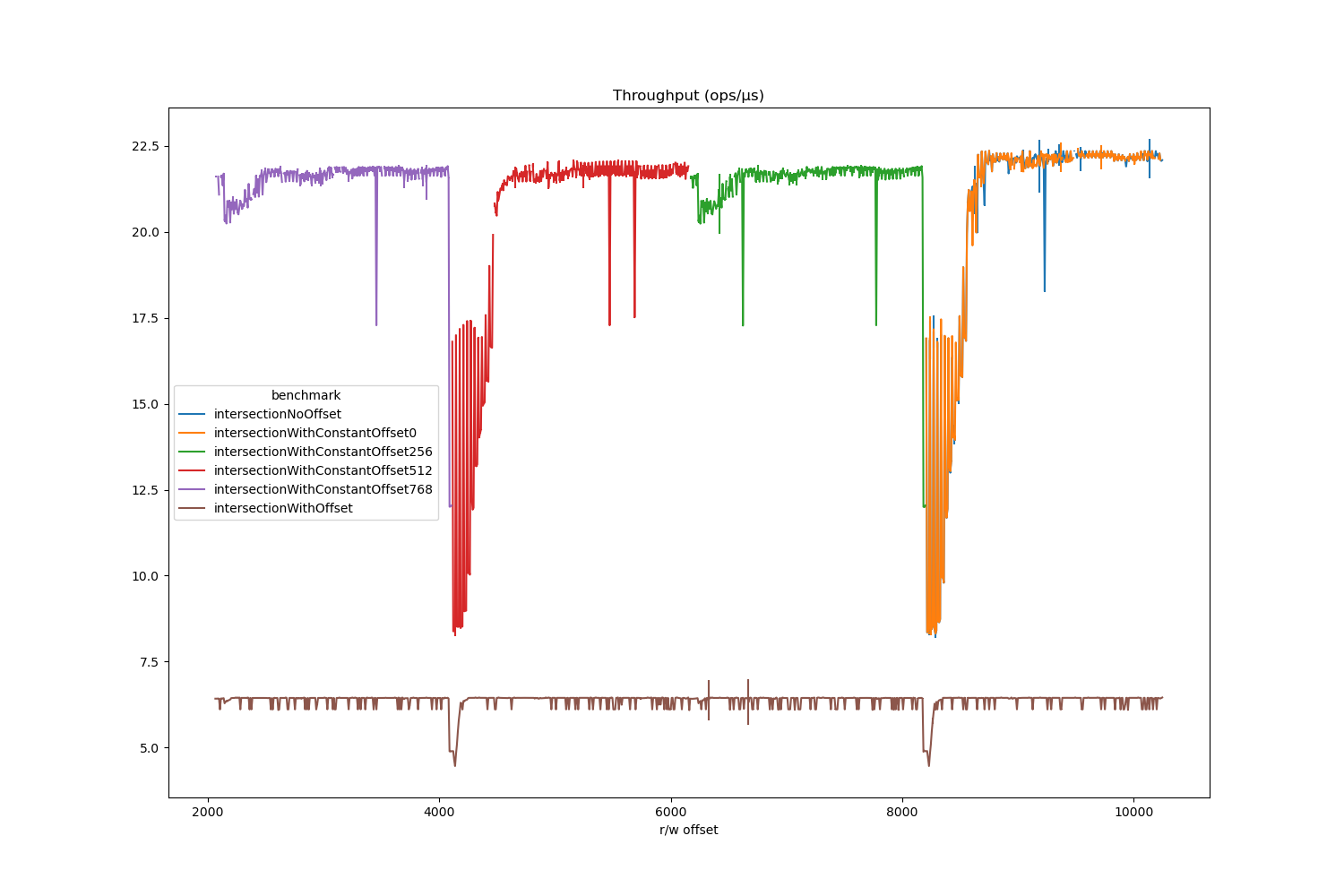
我写了一个快速的基准,说服自己通过扁平化长化追求更好的地方[] []将是令人反感的。结果是嘈杂的,因为它们在忙碌的笔记本电脑上运行(Ubuntu 18,JDK11,Skylake Mobile CPU)。 。这一点是表明避免偏移会更好;在任何合理的测量错误之外,并且我对无论如何都要检查拆卸。
基准(偏移)(索赔)(TargetSize)模式CNT评分误差单元集合0 1024 256 THRPT 5 6.118±1.049 OPS / USINTERECTION 256 1024 256 THRPT 5 8.025±1.413 OPS / USINTERECTION 512 1024 256 THRPT 5 6.099±1.363 OPS / USINTERECTION 768 1024 256 THRPT 5 8.005±1.472 OPS / USINTERSECTIONNOOFFSET 0 1024 256 THRPT 5 13.596±1.724 OPS / US
这种差异是(部分 - 在没有偏移的情况下通过自动传输解释的差异是解释的。没有偏移(参考)。
5.26%│││↗││0x00007f844c3f6aa0:vmovdqu 0x10(%r11,%rdx,8),%ymm0 3.10%││││││0x00007f844c3f6aa7:vpand 0x10(%r8,%rdx,8),%ymm0,% YMM0 12.08%││││││0x00007f844c3f6aae:vmovdqu%ymm0.0x10(%r8,%rdx,8)2.94%││││││0x00007f844c3f6ab5:vmovdqu 0x30(%r11,%rdx,8),%ymm0 9.36 %││││││0x00007f844c3f6abc:vpand 0x30(%r8,%rdx,8),%ymm0,%ymm014.32%││││││0x00007f844c3f6ac3:vmovdqu%ymm0,0x30(%r8,%rdx,8) 2.34%││││││0x00007f844c3f6aca:vmovdqu 0x50(%r11,%rdx,8),%ymm0 2.00%││││││0x00007f844c3f6ad1:vpand 0x50(%r8,%rdx,8),%ymm0,% YMM0 12.54%│││0x00007F844C3F6AD8:VMOVDQU%YMM0.0,0x50(%R8,%RDX,8)1.34%││││││0x00007F844C3F6ADF:VMOVDQU 0x70(%R11,%RDX,8),%YMM0 0.24 %││││││0x00007f844c3f6ae6:vpand 0x70(%r8,%rdx,8),%ymm0,%ymm0 15.32%││││││0x00007f844c3f6aed:vmovdqu%ymm0,0x70(%r8,%rdx,8)
││││││0x00007f5afc3f6699:mov 0x10(%rax,%r13,8),%r10 0.50%││││││0x00007f5afc3f669e:%r10,0x10(%r9,%RSI,8)16.95%││ ││││0x00007f5afc3f66a3:mov 0x18(%rax,%r13,8),%r10 1.01%││││││0x00007f5afc3f66a8:和%R10,0x18(%R9,%RSI,8)18.76%││││ ││0x00007F5AFC3F66AD:MOV 0x20(%rax,%r13,8),%r10 1.83%││││││0x00007f5afc3f66b2:和%r10,0x20(%r9,%rsi,8)19.30%││││││ 0x00007F5AFC3F66B7:MOV 0x28(%rax,%R13,8),%R10 1.63%││││││0x00007F5AFC3F66BC:和%R10,0x28(%R9,%RSI,8)
以上结果充分确认了我的信念,但这是它实际上变得有趣的地方。吞吐量的模式作为偏移的函数;高于256和768;低于0和512.虽然这些测量值非常差,但图案比噪音更多。这导致有趣的基准缺陷与称为4K别名的精确数据布局有关。
上面的模式 - 并且我呈现了以下一些更好的测量 - 是由称为4K别名的东西引起的,它只发生在英特尔硬件上。当处理器从内存加载数据时,负载通过称为负载缓冲区的队列来源;当它将数据返回到内存时,它会通过商店缓冲区。缓冲区基本上是独立的。在原则上,可以使用任何负载和存储事件的订购,就像您在未采取措施的情况下在软件中实现了一对未同步的队列一样?为确保满足订购保证。这些缓冲区的排序保证类型决定了架构的内存模型。
在x86处理器(如我的)上,商店和加载缓冲区是每个FIFO(例如,在ARM上不是真的)。如果地址不同,则无法重新排序,但如果地址不同,则可以重新排序加载。能够重新排序具有较旧商店的一些负载对于程序性能有益,并使基本意义;待处理的商店可能不可能更改正在加载的数据,因为它将进入不同的地址。这只是允许加载数据而无需等待无关存储来完成,这可能需要几个周期。禁止重新排序到同一地址的重新排序意味着,如果无论出于何种原因,写入必须存储到存储器而不是寄存器,则程序将慢下来和存储到存储到该存储器地址的瓶颈。
这是如何强制执行的?当有一个负载时,必须检查是否有一个待处理的存储到同一地址。如果有一个,则意味着负载必须陈旧:较早的指令,根据程序订单,应该已经修改了该地址的数据。它只是写入尚未完成的实施细节。负载需要等到可以读取正确的数据,并重新发行。
英特尔处理器的方式做到这一点是通过查询待处理的商店的商店缓冲区到负载的地址。如果有一个匹配,则负载是通过检查地址的低12位来确定的匹配。这意味着每当有一个偏移量的地址有一个偏移量2 ^ {12} $ 2 ^ {12}远离一个被加载的地址时,那么待处理的商店别名都会带上负载。所以负载将被虚幻重新发行,减慢程序每次发生这种情况时都很少循环。
这一切都意味着像上面那样的基准,其中来自一个阵列的数据被写入另一个阵列的数据,这是根据数据驻留在内存中的精确位置的基准。实际上,由于位置依赖效果导致的变化实际上可以是非常高。为了说明这一点,我写了一个更复杂的基准,隐式地改变分配的arrays的地址。如果偏移是静态最终的静态最终也会禁用自动传输器,因此包括常量的基准,因此也很想知道,因此包括常量的基准,因此包括常量的基准。动态偏移。
这样做的最简单方法是在两个数组之间分配数组,但这限制了阵列标题大小的最小偏移量。阵列的标题和数据将分配给两个数组之间的TLAB。由于Java对象默认为8字节,因此测量小于长时间的偏移量并没有意义。要确保阵列不会被垃圾收集移动,我使用epsilongc.i使用jol录制阵列的地址,所以我可以检查阵列是否处于我认为的相对偏移量。
Warning: Can only detect less than 5000 characters



