使用内存中的SQLite数据库加入CSV和JSON数据
新的SQLite-Utils Memory命令可以将CSV和JSON数据直接导入内存的SQLite Datbase,使用SQL组合和查询它,并将结果输出为CSV,JSON或各种其他格式的纯文本表。
我录制了这个视频演示了新功能 - 在下面的完整伴奏笔记。
SQLite-utils已经提供了一种将CSV和JSON数据导入SQLite-Utils Insert命令的SQLite数据库文件的机制。使用此处理数据涉及两个步骤:首先将其导入TEMP.DB文件,然后使用SQLite-Utils查询运行查询并输出结果。
使用SQL重新形状数据真实有用 - 由于SQLite-Utils可以以多种不同的格式输出,我经常发现自己在CSV文件中加载并将其退回为JSON,或反之亦然。
本周我意识到我有大部分的作品来减少这一步。新的SQLite-utils Memory命令(此处完整文档)针对临时内存的SQLite数据库运行。它可以导入数据,执行SQL并输出一个衬垫的结果,而不需要沿途的任何临时数据库文件。
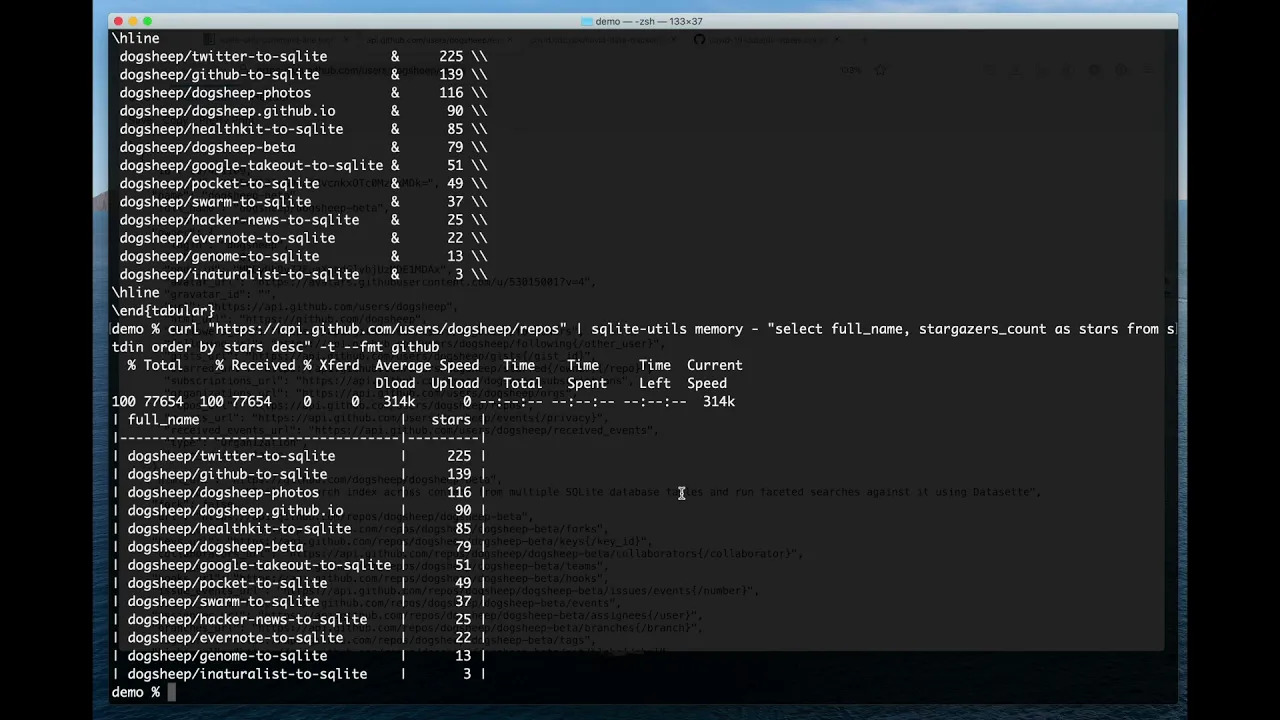
这是一个例子。我的dogsheep github组织有很多存储库。 github通过https://api.github.com/users/dogshep/repos at authentication-可选的api端点来制作那些可用的那些,它返回看起来像这样的json(简体):
[{" id&#34 ;: 197431109,"名称&#34 ;:" dogsheep-beta&#34 ;," full_name&#34 ;:" Dogsheep / Dogsheep-beta&#34 ;," size&#34 ;:61," stargazers_count&#34 ;:79," thepers_count&#34 ;:79,"叉子&#34 ;: 0," open_issues&#34 ;:11},{" id&#34 ;: 256834907,"姓名&#34 ;:" dogsheep-照片"" full_name&#34 ;:" dogsheep / dogsheep-photos&#34 ;," size&#34 ;: 64," stargazers_count&#34 ; 116,"看看者_Count&#34 ;:116,"叉子&#34 ;: 5," Open_issues&#34 ;:18}]
使用SQLite-Utils Memory,我们可以看到这3个最受欢迎的Repos按像这样的星星数:
$ curl -s' https://api.github.com/users/dogsheep/repos' \ | sqlite-utils记忆 - '选择full_name,forks_count,stargazers_count,从Stdin Order by Stars中的星星DESC限制3' -tifull_name forks_count stars ------------------------------------- Dogsheep / Twitter-to-sqlite 12 225dogsheep / github-to-sqlite 14 139dogsheep / dogsheep-photos 5 116
我们正在使用CURL将JSON获取,并将其管道进入SQLite-Utils Memory-The-Meary“从标准输入读取”。然后我们通过以下SQL查询:
STDIN是为工具中的数据提供的数据创建的临时表。查询选择了三个JSON属性,将Stargazers_Count重新创建到明星,按星级排序并返回前三个。
这里的-t选项意味着“作为格式化表的输出” - 我们获取json:
$ curl -s' https://api.github.com/users/dogsheep/repos' \ | sqlite-utils记忆 - '选择full_name,forks_count,stargazers_count,从Stdin Order by Stars中的星星DESC限制3' [{" full_name&#34 ;:" dogsheep / twitter-to-sqlite"" forks_count&#34 ;: 12,"星星":225},{ " full_name&#34 ;:" dogsheep / github-to-sqlite&#34 ;," forks_count&#34 ;:14,#34;星星":139},{&# 34; full_name&#34 ;:" dogsheep / dogsheep-photos"" forks_count&#34 ;: 5,"星星":116}]
$ curl -s' https://api.github.com/users/dogsheep/repos' \ | sqlite-utils记忆 - '选择full_name,forks_count,stargazers_count,从Stdin Order by Stars中的星星DESC限制3' --csvfull_name,forks_count,starsdogsheep / twitter-to-sqlite,12,225dogsheep / github-to-sqlite,14,139dogsheep / dogsheep-photos,5,116
-t选项支持使用--fmt指定的许多不同格式。如果我想通过星星生成顶部Reos的乳胶表,我可以这样做:
$ curl -s' https://api.github.com/users/dogsheep/repos' \ | sqlite-utils记忆 - '选择full_name,forks_count,stargazers_count,从Stdin Order by Stars中的星星DESC限制3' -t --fmt = laTex \ begin {表格} {lrr} \ hline full \ _name& forks \ _count&星星\\\ hine dogsheep / twitter-to-sqlite& 12& 225 \\ dogsheep / github-to-sqlite& 14& 139 \\ dogsheep / dogsheep-photos& 5& 116 \\\ hline \结束{表格}
我们也可以运行聚合查询 - 让我们在所有存储库中添加总体大小和星数:
$ curl -s' https://api.github.com/users/dogsheep/repos' \ | sqlite-utils记忆 - '从Stdin&#39选择sum(size),sum(stargazers_count); -t sum(size)sum(stargazers_count)----------- ---------------------843 934
(我认为这里的尺寸是以千字节测量的:GitHub API文档在这一点上不清楚。)
所有这些示例都使用JSON数据处理到工具中 - 但您也可以通过允许您对其执行连接的方式传递一个或多个不同格式的文件。
纽约时报通过随着时间的推移,在Covid案件和死亡中发布了美国的美国陈述。
CDC有一个未记录的JSON端点(我在这里归档)跟踪不同状态疫苗接种的进展情况。
我们将从该CSV数据到该JSON数据运行加入,并输出结果表。
首先,我们需要下载文件。为了我们的目的,CDC JSON数据并不是正确的形状:
sqlite-utils预期一个平坦的json armet对象 - 我们可以使用JQ重新塑造数据,如下所示:
既然我们在本地拥有数据,我们可以使用以下命令运行连接以将其组合:
$ sqlite-utils memory us-solual.csv vaccination_data.json"从T1加入T2上选择max(t1.date),t1.state,t1.cases,t1.dearts,t2.census2019,t2.dist_per_100k在t1.state = replace(t2.longname,'纽约州' 39;,'纽约')由t1组组.State Order by dist_per_100k desc" -tmax(t1.date)州病例死亡人口普查2019 dist_per_100k ----------------------------------- ------- -------- ------------------------2021-06-18哥伦比亚49243 1141 705749 1492482021-06-18佛蒙特州24360 256 623989 1462572021-06-18罗德岛152383 2724个1059361个1412912021-06-18马萨诸塞709263 17960 6892503 1396922021-06-18马里兰461852 9703 6045680 1381932021-06-18缅因州68753 854 1344212 1368942021 -06-18夏威夷35903 507 1415872 136024 ...
我在这里使用自动创建数字别名T1和T2,但我也可以使用他们的完整表姓名和#34;美国国家" (由于连字符所需的引号)和Vaccination_data代替。
replace()操作需要,因为vaccination_data.json文件调用纽约“纽约状态”,而美国陈述.CSV文件只需称之为“纽约”。
max(t1.date)和t1组.state是一个有用的sqlite技巧:如果执行一个组,然后询问值的max(),则从该表返回的其他列将是列的列包含最大值的行。
这个演示是一个延伸的一点 - 一旦我达到这种复杂程度,我更有可能将文件加载到磁盘上的SQLite数据库文件中,并在数据缩放中打开它们 - 但这是一个更复杂的加入的有趣示例行动。
SQLite-utils Memred命令具有另一个新泡沫的套筒:它会自动检测CSV或TSV文件中的哪个列包含整数或浮点值,并以正确的类型创建相应的内存中的SQLite表。这可以可预测的方式确保Max()和Sum()并按工作顺序,而不会意外地将1排序为高于11。
我不想打破sqlite-utils插入命令的现有用户的向后兼容性,所以我添加了那里的类型检测,作为新的选项,--detect-types或-d for short:
$ sqlite-utils插入my.db us_states us-solues.csv --csv -d [############################# ######] 100%$ sqlite-utils架构my.dbcreate表" us_states" ([日期]文本,[状态]文本,[FIPS]整数,[案例]整数,[Deaths] Integer);
Sqlite-utils:3.10-(总共78个版本)-2021-06-19 Python CLI实用程序和用于操纵SQLite数据库的库
dogsheep-beta:0.10.2-(20版本总计)-2021-06-13从多个SQLite数据库表中构建了内容的搜索索引,并使用Databette对其运行刻面搜索 Markdown-to-sqlite:1.0-(2版本总计)-2021-06-13 CLI工具,用于将标记文件加载到SQLite数据库中