使用 sqlite-utils 将转换函数应用于 SQLite 列中的数据

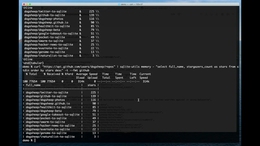
本周早些时候,我发布了 sqlite-utils 3.14,其中包含一个强大的新命令行工具:sqlite-utils convert,它将转换函数应用于存储在 SQLite 列中的数据。任何处理数据的人都会告诉你,90% 的工作都在清理它。对 SQLite 文件中的数据运行命令行转换被证明是一种非常有效的方法。这是一个简单的例子。假设有人在州表的计数列中为您提供了带有逗号格式的数字的数据,例如 3,044,502。 convert 命令有四个参数:数据库文件、表名、列名和一个包含定义要应用的转换的 Python 代码片段的字符串。转换函数可以是你可以用 Python 表达的任何东西。如果您想导入额外的模块,您可以使用 --import module 来实现——这里有一个使用 Python 标准库中的 textwrap 模块包装文本的示例:您可以认为这类似于在 JavaScript 中使用 Array.map(),或应用Python 中 Python 列表推导式的转换。在幕后,该工具利用了强大的 SQLite 功能:能够注册用 Python(或其他语言)编写的自定义函数并从 SQL 调用它们。
convert_value(value) 是一个自定义 SQL 函数,编译为 Python 代码,然后可用于数据库连接。 import sqlite3 import textwrap def convert_value(value): 返回“\n”。 join( textwrap.wrap(value, 100)) conn = sqlite3.连接(“content.db”)连接。 create_function("convert_value", 1, convert_value) conn. execute( "update articles set content = convert_value(content)") sqlite-utils convert 的工作原理是将代码参数编译为 Python 函数,将其注册到连接并执行上述 SQL 查询。有时,当我处理表格时,我发现自己想要将一列拆分为多个其他列。一个典型的例子是位置——如果一个位置列包含纬度、经度值,我通常希望将其拆分为单独的纬度和经度列,以便我可以使用 datasette-cluster-map 可视化数据。 sqlite-utils 转换 data.db 位置 'latitude, longitude = value.split(",")return { "latitude": float(latitude), "longitude": float(longitude),}' --multi --multi告诉命令期望 Python 代码返回字典。然后它将在数据库中创建与这些字典中的键对应的新列,并使用转换结果填充它们。
如果places 表只以一个location 列开始,在运行上述命令后,新的表模式将如下所示: sqlite-utils 中的这个新特性实际上是作为一个独立的工具开始的,称为sqlite-transform。将它添加到 sqlite-utils 的部分原因是为了避免混淆该工具的功能和 sqlite-utils 转换工具,后者执行完全不同的操作(应用使用 SQLite 的默认 ALTER TABLE 语句无法实现的表转换)。沿着这条线的某个地方,我搞砸了这两个工具的命名!除了允许任意 Python 代码外,sqlite-transform 还捆绑了许多有用的默认转换方法。我最终通过将它们公开为可以从命令行代码参数调用的函数来使它们在 sqlite-utils convert 中可用,如下所示:以这种方式将它们实现为 Python 函数意味着我不需要发明一个新的命令-用于将附加选项传递给各个配方的行机制——而是像这样传递参数:sqlite-utils 命令行工具公开的几乎每个功能在 sqlite_utils Python 库中都有一个匹配的 API。转换也不例外。任何 Python 可调用项都可以传递给 convert,它将应用于指定列中的每个值——同样,就像使用 map() 将转换应用于数组中的每个项目一样。
您还可以使用 Python API 执行更复杂的操作,例如以下两个示例: # 仅将 id > 20 table 的行的标题转换为大写。 convert( "title", lambda v: v.upper(), where = "id > :id", where_args ={ "id": 20}) # 创建两个新列,“upper”和“lower”,# 和从转换后的标题表中填充它们。 convert( "title", lambda v: { "upper": v.upper(), "lower": v.lower() }, multi = True) 今天早些时候我使用了新的 sqlite-utils convert 命令来调试一个我的博客的性能问题。我的大部分博客流量都是通过 Cloudflare 提供的,缓存超时为 15 分钟——但偶尔我会访问一个未缓存的页面,他们开始感觉不像我预期的那么快。不知何故,我的第 50 个百分位数接近 10 秒,而我的最大页面响应时间是 23 秒!显然有些事情是非常错误的。我使用 NGINX 作为 Heroku 设置的一部分来缓冲响应(请参阅在 Heroku 上在 nginx 后面运行 gunicorn 以进行缓冲和日志记录),并且我有自定义的 NGINX 配置来写入 Heroku 日志——主要是为了解决 Heroku 的默认日志记录中的限制它无法记录完整的用户代理或引用标头。我扩展了该配置以记录 NGINX request_time、upstream_response_time、upstream_connect_time 和 upstream_header_time 变量,我希望它们能帮助我弄清楚发生了什么。
2021-08-05T17:58:28.880469+00:00 app[web.1]: measure#nginx.service=4.212 request="GET /search/?type=blogmark&page=2&tag=highavailability HTTP/1.1" status_code=404 request_id =25eb296e-e970-4072-b75a-606e11e1db5b remote_addr="10.1.92.174" forwarded_for="114.119.136.88, 172.70.142.28" forwarded_proto="http" user_agent="10.1.92.174" forwarded_proto="http" user_agent="10.1.92.174" Mozilla/5.0 (Linux; Android 7.0;) AppleWebKit/537.36 (KHTML, like Gecko) Mobile Safari/537.36 (compatible; PetalBot;+https://webmaster.petalsearch.com/site/petalbot)" request_time="4.212" upstream_response_time ="4.212" upstream_connect_time="0.000" upstream_header_time="4.212"; sqlite-utils insert 命令喜欢使用 JSON,但我只有原始日志行。我使用 jq 将每一行转换为 {"line": "raw log line"} JSON 对象,然后将其作为换行符分隔的 JSON 通过管道传输到 sqlite-utils insert: cat /tmp/log.txt | \ jq --raw-input '{line: .}' --compact-output | \ sqlite-utils insert /tmp/logs.db log - --nl jq --raw-input 接受只是原始文本行的输入,还不是有效的 JSON。 '{line: .}' 是一个构建 {"line": "raw input"} 对象的小型 jq 程序。 --compact-output 导致 jq 输出换行符分隔的 JSON。然后 sqlite-utils insert /tmp/logs.db log - --nl 将该换行符分隔的 JSON 读取到 logs.db 数据库文件(此处为完整文档)中的新 SQLite 日志表中。现在我有一个带有单列的 SQLite 表,行。下一步:解析讨厌的日志格式。令我惊讶的是,我找不到用于解析 key=value key2="quoted value" 日志行的现有 Python 库。相反,我必须找出一个正则表达式:
我使用该正则表达式作为传递给 sqlite-utils 转换工具的自定义函数的一部分: sqlite-utils convert /tmp/logs.db log line --import re --multi "$(cat <<EOD r = re .compile(r'([^\s=]+)=(?:"(.*?)"|(\S+))') 对 = {} for key, value1, value2 in r.findall(value) :pairs[key] = value1 or value2 return pairsEOD)”(这使用了 cat <<EOD 技巧来避免在 Python 代码中找出如何转义单引号和双引号以便在 zsh shell 命令中使用。)使用--multi 此处为该日志文件中看到的每个键/值对创建了新列。最后一步:转换类型。新列都是文本类型,但我想对它们进行排序和算术,因此我需要将它们转换为整数和浮点数。我为此使用了 sqlite-utils 转换: sqlite-utils transform /tmp/logs.db log \ --type 'measure#nginx.service' float \ --type 'status_code' integer \ --type 'body_bytes_sent' integer \ - -type 'request_time' float \ --type 'upstream_response_time' float \ --type 'upstream_connect_time' float \ --type 'upstream_header_time' float 一旦日志在 Datasette 中,当我按 request_time 排序时,问题很快就变得明显:一支军队的搜索引擎爬虫在我的分面搜索引擎中访问深层链接过滤器,例如 /search/?tag=geolocation&tag=offlineresources&tag=canvas&tag=javascript&tag=performance&tag=dragndrop&tag=crossdomain&tag=mozilla&tag=video&tag=tracemonkey&year=2009&type=blogmark。这些是生成昂贵的页面!它们也不太可能出现在我的 Cloudflare 缓存中。
我发布了更改并等待了几个小时,看看会产生什么影响:爬虫花了一段时间才注意到我的 robots.txt 已更改,但 8 小时后我的网站性能得到了显着改善 - 我现在看到大约 450 毫秒的第 99 个百分位数,而在我发送 robots.txt 更改之前的 25 秒!有了这个最新的补充,sqlite-utils 已经发展成为一个强大的工具,用于导入、清理和重塑数据——尤其是当与 Datasette 结合使用时,以探索、分析和发布结果。 sqlite-transform:1.2.1—(共 10 个版本)—2021-08-02 在 SQLite 数据库中的列上运行转换的工具 sqlite-utils:3.14—(总共 82 个版本)—2021-08-02 Python CLI 实用程序和用于操作 SQLite 数据库的库 datasette-json-html:1.0.1—(共 6 个版本)—2021-07-31 用于基于 JSON 值渲染 HTML 的 Datasette 插件