#图像
OpenAI introduces two new GPT-3 models: CLIP, which classifies images into categories from arbitrary text, and DALL·E, which can generate images from text(www.technologyreview.com)
2021-1-6 21:20
借助GPT-3,OpenAI表明可以将单个深度学习模型训练为以多种方式使用语言,只需将其投入大量文本即可。然后表明,通过将文本交换为像素,可以使用相同的方法来训练AI以完成半成品图像。 GPT-3模仿人类使用单词的方式;图片GPT-3预测了我们所看到的。
现在,OpenAI将这些想法整合在一起,并建立了两个新模型......
Accelerating JPEG Coding with Multiple Threads(optidash.ai)
2021-1-4 20:18
JPEG标准于1992年发布后,JPEG图像成为数字摄影的代名词,几乎在所有处理照片质量图像的应用程序中都使用JPEG图像。采用该标准之所以快速且几乎通用是因为它同时利用多种技术来减小压缩文件的大小。其中之一是对人类视觉系统的局限性的理解,哪些是重要的信息,哪些是不重要的信息,可以删除。
使用JPEG方法压缩图像......
America’s first commercial space SAR (Synthetic-Aperture Radar) imagery(www.capellaspace.com)
2020-12-28 13:21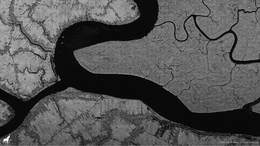
当我在2016年创立Capella Space时,有许多欧洲提供商在运营和构建商业SAR,但美国在商业SAR竞赛中一马当先。 Capella决定改变这种局面,并通过将完全由美国设计,建造和运营的能力推向市场来挑战国际竞争。今天,我们实现了这一目标,我们可以自豪地说我们是第一家美国SAR运营商。
在我们的红杉卫星发射......
Executable PNGs(djharper.dev)
2020-12-26 21:27几周前,我在阅读有关PICO-8的信息,PICO-8是一款受限限制的幻想游戏机。真正引起我兴趣的是新颖的游戏发行方式,您将其编码为PNG图像。这包括游戏代码,资产以及所有内容。图像可以是您想要的任何图像,游戏的屏幕截图,精美的艺术品或仅仅是文字。要加载它们,您将图像作为输入传递到PICO-8程序并开始播放。
这让我......
A 12.48 Inch (1304x984) Three-Color E-Paper Display by Waveshare(louwrentius.com)
2020-12-24 21:32我正在运行一个太阳能博客,我想添加一个低功率显示器以显示每日的太阳能收获1,也许还有一些其他信息。
因此,我决定使用电子纸显示器。我想要一个可以从远处读取的显示器,所以越大越好。因此,我选择了Waveshare 12.48英寸电子纸显示屏2。
在撰写本文时,这种特殊的显示器售价179美元(不含税和运费)。
......
Geometrize: Turn Images into Geometric Primitives(www.geometrize.co.uk)
2020-12-20 23:39Geometrize是一个桌面应用程序和开源工具包,用于将图像几何化为形状。该软件仅使用矩形,三角形和椭圆形等几何图元,即可将图像重新创建为形状的抽象排列。
Sam在大学学习计算机科学时,他读到一种遗传算法,该遗传算法以简单的形状重新创建了Mona Lisa。 Geometrize最初是使用此概念创建视频游戏......
2020-12-13 6:31
imgdiff的速度不如这样的工具快,我也不为它感到骄傲,但是它比世界上最快的逐像素图像差异工具快3倍,所以也许您 39;会发现它很有用。 用法:imgdiff [--threshold THRESHOLD] [--diff-image] [--fail-on-layout] BASE COMPARE OUTPUT......
2020-12-4 21:4
我们提出pixelNeRF,这是一种学习框架,可预测以以下条件为前提的连续神经场景表示:
一或几个输入图像。
现有方法
构建神经辐射场[Mildenhall等。 2020]
涉及独立优化每个场景的表示,需要许多校准的视图和大量的计算时间。
我们朝着解决这些缺点迈出了一步
通过引入一种以完全卷积的方式在图像......
2020-11-30 12:28
USENIX的人断言黑人的生命至关重要:请阅读USENIX关于种族主义和黑人,非裔美国人和非洲散居者融合的声明。
我们报告了Lepton的设计,实现和部署,该系统是一个容错系统,可以将JPEG图像平均无损压缩到其原始大小的77%。 Lepton用并行算术代码替换了基线JPEG压缩的最低层(霍夫曼代码),以便可以快......
AI Anonymizer – use virtual faces to secure your identity(generated.photos)
2020-11-28 10:1是!您有权免费使用匿名器供个人使用。您无权创建图像库存或将生成的图像用于商业目的。对于商业用途,可购买许可证。
不,我们不会保存您的个人数据。该项目是展示合成媒体实用性的有用方法。
为了使Anonymizer正常工作,您应该上传一张清晰的脸部照片,直截了当。不需要裁剪背景。避免使用可见多个面孔的图像。
随处在线......
Bringing Old Photos Back to Life(raywzy.com)
2020-11-22 8:58我们建议通过深度学习方法还原遭受严重退化的旧照片。与可以通过监督学习解决的常规还原任务不同,真实照片的降级很复杂,并且合成图像和真实旧照片之间的域间隙使网络无法推广。因此,我们通过利用真实照片和大量合成图像对来提出一种新颖的三重态域翻译网络。具体来说,我们训练两个变体自动编码器(VAE)将旧照片和干净照片分别转换为两......
An Interactive Introduction to Fourier Transforms(www.jezzamon.com)
2020-11-15 6:41
傅立叶变换是一种用于各种不同事物的工具。这是对傅里叶变换功能的解释,以及它可能有用的一些不同方式。以及你如何用它做漂亮的东西,比如这个东西:
我将解释动画是如何工作的,并在此过程中解释傅里叶变换!
我们暂时不讲数学和方程式。它背后有一堆有趣的数学知识,但最好从它的实际用途开始,以及为什么你想首先使用它。如果你想知道更......
I wrote JavaScript to avoid JavaScript(markentier.tech)
2020-11-8 23:51
Web技术已经取得了长足的进步,您会意识到:如今并不是所有的事情都需要用JavaScript来完成。
但这已经是一张大嘴巴了,而且还会透露太多信息,你可能就不会点击我那略显诱人的标题了,对吧?
首先,我根本不反对JavaScript(JS)。如果你正在构建一个Web应用程序,那么这不仅完全可以,而且很可能是一个核心需......
Frequency Domain Image Compression and Filtering(blog.demofox.org)
2020-11-7 11:23
4年多前,我写了一篇关于频域图像的简短博客文章:https://blog.demofox.org/2016/07/28/fourier-transform-and-inverse-of-images/。
现在是时候再回顾一下这个话题,并补充一些东西了。
如果你想知道傅里叶变换是如何工作的,它可以将图像或其他数据转换到......
Simple Image Vectorization(wordsandbuttons.online)
2020-11-1 14:7矢量化是指当你拍摄一些“我的世界”风格的光栅图像,并从中制作一张清晰的矢量图片的时候。
当你想把卫星照片变成地图时,它特别有用。或者,如果您想扫描一些蓝图并将其转换为CAD模型。或者,如果您想重新发布一个旧游戏,但您不想从头开始重新绘制所有的艺术作品。
我要告诉你的算法与所有这些事情没有任何关系。它是一种基本的矢量化......
Image Scaling Attacks(embracethered.com)
2020-10-29 14:27这篇文章是关于机器学习和人工智能的系列文章的一部分。点击博客标签“Huskyai”查看相关帖子。
几周前,在为我的GrayHat 2020-Red Team Village演示文稿准备演示时,我在Erwin Quiring等人的“对抗性预处理:理解和防止机器学习中的图像缩放攻击”一书中遇到了“图像缩放攻击”。
其基本......
Porsche Classifier – Identify Porsche models with 95% accuracy(www.rkpblog.tech)
2020-10-29 10:30使用Fastai-v3、pytorch和Gradient进行培训。使用resnet50,在NVIDIA Quadro P5000上进行培训。构建在坞站上,并托管在Microsoft Azure Web服务上。在包含30000款不同质量的保时捷车型的公开来源图像数据集上进行培训。保时捷汽车,特别是最新一代的Paname......
Next.js 10(nextjs.org)
2020-10-28 0:31
内置映像组件和自动映像优化:使用新的Next/Image组件自动优化映像。
MDX的快速刷新:使用@Next/MDX时,现在可以利用快速刷新来应用更改,而无需重新加载整个页面。
从第三方Reaction组件导入CSS:现在支持从NPM导入组件所需的CSS。
阻塞getStaticPath的回退:在生成新的静态页面时等......
A Slow Website(slowww.ml)
2020-10-26 8:15您现在正以每秒175比特的速度体验网络。无论您的Internet连接有多快,此页面加载速度都会很慢。请稍候,…。回到互联网的早期,人们争辩说不需要运行速度比这更快的调制解调器。大约每秒20个字符是普通人所能读到的最快速度。为什么传递信息的速度会更快呢?如今,我们想要的一切都是即时的。但是有时候有delaye......
2020-10-24 18:13
在一个耗时5年、500小时编辑、42小时处理的项目中,天体摄影师马特·哈比森完成了一个始于2013年的梦想:捕捉、处理并提供猎户座25亿像素极其详细的照片。
哈比森写道,捕捉这张照片的想法始于2013年,开始于2015年。在五年的时间里,他拍摄了数千张照片,这些照片被编目成200张照片,最终他将把这些照片处理成一张猎......
File Corruption Is Attractive(venam.nixers.net)
2020-10-7 8:14
我们生活在一个逐渐不断地被过度理性和秩序所吸引的世界。在这篇文章中,我们将打破迷人的泡沫,拥抱腐败和混乱-我们将讨论图像故障艺术的主题。
W̸h̸a̷t̴‘̶s̴̶a̴̷g̷l̸i̷t̴c̵h̵。
欢迎来到创造性破坏之地:图像故障艺术。我们的故事从一个简单的想法开始:在墙纸上出现故障,制作一张损坏图片的幻灯片。我们罪......
2020-9-30 4:19
Https://cppcon.org/https://github.com/CppCon/CppCon2020-Halide是一种开源的,特定于领域的语言,用于优化图像处理,机器学习...
The first-ever image of a black hole is now a movie(www.nature.com)
2020-9-24 11:8
去年公布的历史性的第一张黑洞图像现在已经被拍成了电影。这一短小的图像序列显示了黑洞周围环境的外观是如何随着其引力将周围的物质搅动成一个恒定的漩涡而随着时间的推移而变化的。
这些图像显示了一个不平衡的光斑在M87星系中心的超大质量黑洞周围旋转。为了创建它们,事件视界望远镜(EHT)合作-利用全球范围的天文台网络-挖掘出......
Open Source Meets Super Resolution(www.collabora.com)
2020-9-22 5:15
尽管深度学习支持的超分辨率方法具有很高的性能,但由于它们对计算的要求很高,很难应用到现实世界的应用中。在Collabora,我们已经解决了这个问题,我们为视频超分辨率引入了精确且轻量级的深度网络,该网络运行在使用PanFrost(马里GPU的免费开源图形驱动程序)的完全开源软件堆栈上。下面是超分辨率的概述,它用于图像......
Toonify Yourself(toonify.justinpinkney.com)
2020-9-17 3:45
这个重音系统是使用深度学习制作的。它是基于将混合的StyleGAN模型蒸馏成一个Pix2PixHD图像到图像转换网络。
如果所有这些都没有任何意义,看看这篇关于自我代位化的博客文章,它解释了一些细节。
该算法对没有太多噪声的高分辨率图像效果最好。直视镜头似乎也是最有效的。像公司头像这样的东西往往效果很好。
我们不存储......
Differentiable Dithering(www.peterstefek.me)
2020-9-16 22:51发布于2020年9月9日的问题让我们假设我们想要减少图像中的颜色数量。例如,考虑下面的水果图像:如果我们计算上面的图像中有多少种颜色,我们会得到惊人的157376(对于900x450像素的图像)。所有这些颜色真的有必要吗?上图有16种颜色,下图只有8种颜色。调色板减少的问题已经过广泛研究,典型的方法大致如下:
通过将......
A Tour of the Tiny and Obfuscated Image Decoder(eastfarthing.com)
2020-9-15 6:46当我第一次在2018年IOCCC比赛中看到“最具通货膨胀率”的获奖作品时,我感到很困惑。这个小程序由非常多产的FabriceBellard编写,只有4KB的源代码,发出了著名的Lena测试图像的128×128分辨率版本。巫毒!IOCCC的评委写道:“我们能理解一些算术,但一点魔力都看不懂。”我决心找出它的魔力,并受到......
AVIF Has Landed(jakearchibald.com)
2020-9-9 4:26
早在古代的7月,我就发布了一段视频,深入探讨了有损和无损图像压缩的工作原理,以及如何应用这些知识为网络压缩一组不同的图像。嗯,那已经过时了,因为AVIF已经到了。非常出色。
AVIF是从AV1视频的关键帧中衍生出来的一种新的图像格式。它是一种免版税的格式,而且桌面版Chrome85已经支持它。虽然Safari花了10......
Score matching with Langevin Sampling: a new contender to GANs(ajolicoeur.wordpress.com)
2020-9-4 6:59
它的工作方式是采样一个干净的数据,用高斯噪声破坏它,然后让计分网络学习模拟被破坏数据的得分函数(请参阅损失函数的正确术语),条件是噪声水平()。对于高斯噪声,归结为试图恢复原始的未损坏样本减去损坏样本除以噪声的方差。可以看出,如果Noise()的方差变为0,则得分网络精确地恢复得分函数。因此,当为非零时,我们恢复得分......
PNG and Hidden Pixels(www.hackerfactor.com)
2020-9-1 16:3几年前,我给FotoForensics添加了一个隐藏像素分析器。此分析器执行两项操作:如果图片具有Alpha通道(例如,具有透明层的PNG),则它允许您查看没有Alpha通道的图像或单独查看Alpha通道。它还提供了聚焦于Alpha通道的覆盖,但也允许您查看其余内容。
如果图片有过多的边框填充,例如使用JPEG(不是......