强化
2022-2-17 14:10
使用磁约束的核聚变,特别是在托卡马克配置中,是实现可持续能源的一条有希望的途径。一个核心挑战是在托卡马克容器内形成并维持高温等离子体。这就需要使用磁性执行器线圈进行高维、高频、闭环控制,由于各种等离子体配置的不同要求,这一点更加复杂。在这项工作中,我们介绍了一种以前未描述的托卡马克磁控制器设计体系结构,该体系结构可以......
2021-7-24 10:56
深度强化学习——机器通过测试其行为的后果来学习——是人工智能最有前途和影响力的领域之一。它将深度神经网络与强化学习相结合,可以一起训练以通过多个步骤实现目标。它是自动驾驶汽车和工业机器人的重要组成部分,它们必须安全、准时地在复杂的环境中航行。大多数机器学习算法擅长感知任务,这些任务需要一个人在一秒钟内完成,例如识别声......

2021-1-19 4:5
下载PDF摘要:我们通过搜索计算图的空间,提出一种元学习强化学习算法的方法,该计算图可计算损失函数,以基于值的无模型RL代理进行优化。 学习算法与领域无关,可以推广到培训期间未看到的新环境。 我们的方法可以从头开始学习,也可以从已知的现有算法(例如DQN)中引导,从而实现可解释的改进,从而提高性能。 我们的方法从零开......
2021-1-1 8:57
Linux不是安全的操作系统。但是,您可以采取一些步骤对其进行改进。本指南旨在说明如何尽可能地加强Linux的安全性和隐私性。本指南试图与发行版无关,并且不限于任何特定的指南。免责声明:如果您不确定自己在做什么,请不要尝试在本文中应用任何内容。本指南仅关注安全性和隐私性,而不关注性能,可用性或其他任何内容。本指南中列......
2020-12-8 12:7
强化学习是关于代理商从世界上获取信息并学习与之互动的策略,以使他们表现更好。因此,您可以想象一个未来,每次您在键盘上打字时,键盘都会学会更好地了解您。或每次您与某个网站进行交互时,它都会更好地了解您的喜好,因此世界在与人交互方面的工作越来越好。
MSR纽约市合伙人研究经理John Langford
从根本上讲,强......
2020-10-18 7:11
最近的壮举,比如AlphaGo战胜了世界上最好的围棋选手,把强化学习(RL)带到了聚光灯下。然而,什么是RL,它是如何取得如此显著的效果的呢?
在第一篇文章中,我们将探讨蒙特卡罗控制方法(不是深度控制方法),尽管该方法非常简单,但它是构建一些最先进的RL的基础。
RL问题包括(至少)两个实体:代理和环境,如下图所示。......
2020-10-16 11:25
车-杆平衡问题是强化学习的一个典型问题。一根杆子系在带有旋转接头的手推车上。代理人必须通过向左或向右移动手推车来平衡杆子。
互联网上的大多数解决方案似乎都采用强化学习结合复杂的Kera模型来解决这一问题。
在这篇文章中,我将向您展示,如果您足够了解您的系统,您不需要任何深度学习方案。在手摇平衡的情况下,你所需要的只是......
2020-9-20 6:40
代码的KDD 2020论文稳健垃圾邮件检测纳什强化学习。窦颖彤,马桂祥,余承东,谢思红。[论文][幻灯片][视频][工具箱][中文博客]。
Nash-Detect是本文提出的一种利用强化学习训练鲁棒垃圾评论检测器的算法。鲁棒检测器由五个基本检测器组成,通过垃圾邮件发送者和防御者之间的极小极大博弈进行训练。垃圾邮件发送......
2020-7-15 5:10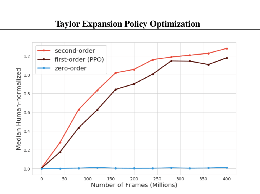
来自哥伦比亚大学和DeepMind的一组研究人员提出了一个泰勒展开策略优化(TayPO)框架,该框架结合了两种领先的算法改进方法。
策略优化是无模型强化学习(RL)中的一个主要框架,它提供了可以显著提高算法性能的见解。其中两个最突出的算法改进是信任区域策略搜索和非策略修正,而这些想法流通常是单独评估的。在“泰勒展开策......
2020-7-15 2:26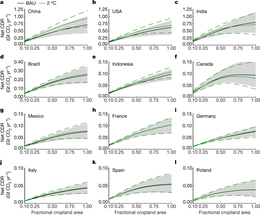
可在农田中部署的增强硅酸盐岩石风化(ERW)可用于大气二氧化碳(CO2)去除(CDR),这现在是减缓人为气候变化所必需的1。增强硅酸盐岩石风化(ERW)在改善粮食和土壤安全以及减少海洋酸化2、3、4方面也可能有协同效益。在这里,我们使用集成性能建模方法对2050年进行初步技术经济评估,量化CDR潜力和成本在各国之间的......
2020-7-12 1:9
今天各种人工智能系统背后的许多神经网络结构与一个世纪前的早期计算机有着有趣的相似之处。就像早期的计算机是专门用于特定目的的电路,如解线性系统或密码分析一样,训练有素的神经网络通常也作为执行特定任务的专门电路发挥作用,所有参数在同一全局范围内耦合在一起。
人们可能自然会想,学习系统可能需要什么才能以与编程系统相同的方式......
2020-6-2 22:34
ACME是一个强化学习(RL)代理和代理构建块的库。Acme努力公开简单、高效和可读的代理,这些代理既可以作为流行算法的参考实现,也可以作为强基线,同时仍然提供足够的灵活性来进行新的研究。Acme的设计还试图在不同的复杂程度上为RR问题提供多个入口点。
在最高级别,Acme公开了许多可以简单使用的代理,如下所示:
i......