社会网络中的“多数错觉”
个人的决定,从购买什么产品到是否从事危险行为,往往取决于其他人的选择、行为或状态。然而,人们很少对他人的状况有全球性的了解,而是必须通过对其社会联系的局部观察来估计这些情况。网络结构会严重扭曲个体的局部观察。在某些情况下,在网络中全球罕见的状态在许多个人的本地社区中可能会被显著地过度代表。这种效应,我们称之为“多数错觉”,导致个人系统地高估了这种状态的流行程度,这可能会加速社会传染的传播。我们开发了一个统计模型来量化这种影响,并通过在合成网络和真实网络中的测量来验证它。我们发现,在具有异构度分布和不相配结构的网络中,错觉加剧。
个人的态度和行为取决于他或她对他人的选择、态度和行为的看法[1-6]。这种现象每天都表现在人们决定采用一种新技术[7,8]或想法[5,9],听音乐[3],从事危险行为[10],酗酒[11,12],或加入社会运动[1,2]。因此,各种各样的行为被称为“传染性”,因为它们在人群中传播,因为人们感知到其他人采取了这种行为,然后自己也采用了这种行为。在某些情况下,“社会传染”会从一小部分最初的采用者传播到很大一部分人口,导致流行、热门歌曲、成功的政治运动或盛行的社会规范。研究人员已经将这种全球疫情的爆发与基础网络的拓扑结构[6,13]、高度联系的个人[14,15]和相互联系的人的小群集[4,5]联系起来。
然而,网络结构可能会系统性地偏向社会认知和人们对同龄人的推论。社会关系密切的人往往是相似的[16]。这使人们暴露在一个有偏见的人群样本中,产生了“选择性暴露”[17]效应,导致个人高估了他们的特征在人群中的流行程度[18]。此外,个人可能会有选择地向同龄人透露或隐瞒他们的属性或行为,特别是如果这些行为偏离了普遍的规范。这种“选择性披露”[17,19]将进一步偏向社会认知,导致个人错误地推断这种行为在人群中的流行程度。社会认知偏差可以改变社会传染的动态,稳定不受欢迎的态度和行为[20,21]。
除了上述影响之外,网络结构还可能通过偏向个人的观察来进一步扭曲社会认知。这些网络偏见之一是友谊悖论,它指出,平均而言,大多数人的朋友比他们的朋友少[22]。尽管友谊悖论几乎是无稽之谈,但它已被用来设计有效的策略,用于疫苗接种[23]、社会干预[24]和传染性暴发的早期检测[25,26]。简而言之,友谊悖论建议监控他们随机的网络邻居,因为他们更有可能建立更好的联系,不仅生病更早,而且一旦生病,还会感染更多的人,而不是在疫情早期监控随机的人,而是监控他们随机的网络邻居。最近,友谊悖论被推广到度以外的属性,即网络邻居的数量。例如,你的合著者比你更经常被引用[27],你在Twitter上关注的人比你更频繁[28]。事实上,任何与程度相关的属性都会产生悖论[27,29]。
我们描述了友谊悖论的一种新的变体,这对于理解社会传染是必不可少的。这一悖论适用于个人有属性的网络,在最简单的情况下,一个二元属性,比如“有红头发”和“没有红头发”,“买了iPhone”和“没有买iPhone”,“民主党人”和“共和党人”。我们将具有此属性的个人称为“活动的”,其余的称为“非活动的”。我们表明,在某些条件下,许多人会观察到他们的大多数邻居处于活动状态,即使这种状态在全球范围内是罕见的。例如,虽然红头发的人很少,但许多人可能会注意到,他们的大多数朋友都是红发。因此,我们称这种效应为“多数错觉”。
作为“多数错觉”悖论的一个简单说明,请考虑图1中的两个网络。除了少数几个节点中的哪些是有色的之外,这两个网络是相同的。假设彩色节点处于活动状态,而其余节点处于非活动状态。尽管这显然是很小的差异
我们使用由SNAP库(https://snap.stanford.edu/data/))实现的配置模型[32,33]来创建具有指定程度序列的无标度网络。我们从形式为p(K)∼k−α的幂律中生成了一个度序列。这里,pk是具有k条半边的节点的分数。配置模型通过连接一对随机选择的半边来形成边来进行。重复链接过程,直到所有的半边都用完或者没有更多的方法形成边。
为了创建ERDős-Rényi类型的网络,我们从N=10,000个节点开始,并以一定的固定概率随机链接对。这些概率被选择来产生与无标度网络的平均度相似的平均度。
表1总结了我们研究的真实世界网络的统计数据,包括高能物理学家协作网络(HepTh)、来自Reactome项目的人类蛋白质-蛋白质相互作用网络(http://www.reactome.org/pages/download-data/),Digg Follow Graph)(doi:10.6084/m9.figshare.2062467)、安然电子邮件网络(http://www.cs.cmu.edu/netdata/)、twitter用户投票图[34]和政治博客网络(http://www-personal.umich.edu/∼mejn/netdata/)。
一个网络的结构部分由它的度分布p(K)来指定,它给出了一个无向网络中随机选择的节点有k个邻居的概率(即,度k)。这个量还影响随机选择的边连接到k次节点的概率,也称为邻接度分布Q(K)。由于高度节点具有更多的边,它们在邻接度分布中将被过度表示为与其度成比例的因子;因此,Q(K)=Kp(K)/〈k〉,其中〈k〉是平均结点度。
网络的结构通常超出了它们的度分布所指定的结构:例如,节点可能优先链接到具有相似(或非常不同)度的其他节点。这种度相关性由联合度分布e(k,k‘)捕获,联合度分布e(k,k’)是在无向网络中随机选择的边的任一端找到k和k‘度节点的概率[35]。这个量满足归一化条件∑kk‘e(k,k’)=1和∑k‘e(k,k’)=q(K)。在全局范围内,无向网络中的度相关性通过类似性系数来量化,该系数简单地说就是连通节点的度之间的皮尔逊相关性:(1)这里,。在分类网络(Rkk>;0)中,节点具有到相似节点的倾向链接,例如,高度节点到其他高度节点。另一方面,在不相配网络(rkk<;0)中,它们更喜欢链接到不同的节点。由一个中心集线器和仅链接到该集线器的节点组成的星形网络就是一个不相配的网络的例子。
我们可以使用Newman边重新布线过程[35]来改变网络的度分类,而不改变它的度分布p(K)。重新关联过程随机选择两对连接的节点,如果这样做会改变它们的度数相关性,则交换它们的边。这可以重复进行,直到达到所需的程度分类。
网络中属性的配置由联合概率分布P(x,k)表示,k次节点具有属性x的概率。在本文中,我们只考虑二进制属性,将x=1的节点称为活动节点,而将x=0的节点称为非活动节点。联合分布可以用来计算ρkx、节点度和属性之间的相关性:(2)在上述方程中,σk和σx分别是度分布和属性分布的标准差,〈k〉x=1是活跃节点的平均度。
随机激活节点会创建ρkx接近于零的配置。我们可以通过在节点之间交换属性值来更改它。例如,要增加ρkx,我们随机选择x=1的节点v 1和x=0的节点v 0,如果v 0的次数大于v 1的次数,则交换它们的属性。我们可以继续交换属性,直到达到所需的ρkx(或者不再更改)。
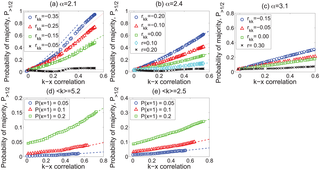
合成网络使我们能够系统地研究网络结构如何影响“多数错觉”悖论的强度。首先,我们考察了具有高度异构度分布的网络,该网络包含几个高度集线器和许多低度节点。这类网络通常用p(K)∼k−α形式的无标度分布建模。要创建异构网络,我们首先从指数为α的分布中采样一个度序列,其中指数α取三个不同的值(2.1、2.4和3.1),然后使用配置模型创建一个N=10,000个节点的无向网络和该度序列。我们使用上面描述的边重新布线过程来创建一系列具有相同的度分布p(K)但不同值的度分类rkk的网络。然后,我们激活一个分数P(x=1)=0.05中的节点,并使用属性交换过程来获得不同的度-属性相关度ρkx的值。
图2示出了这些无标度网络中具有超过一半的活动邻居的节点的比例作为度-属性相关性ρkx的函数。经历“多数错觉”的节点的比例可能相当大。当α=2.1时,60%-80%的节点将观察到超过一半的邻居是活动的,即使实际上只有5%的节点是活动的。三个因素加剧了“多数错觉”:随着程度-属性相关性的增加,这种错觉变得更加强烈;随着网络变得更加不协调(即,rkk减小)和更多的尾巴(即,α变得更小),“多数错觉”变得更加强烈。然而,即使当α=3.1时,在某些条件下,相当一部分节点也会经历这种悖论。图中的线条显示了使用公式(5)对悖论的理论估计,如下一小节所述。
在具有更均匀的例如泊松(Poisson)度分布的网络中也可以观察到“多数错觉”。我们使用ERDős-Rényi模型生成了N=10,000,平均度〈k〉=5.2,〈k〉=2.5的网络。我们随机激活了5%、10%和20%的节点,并使用边重新布线和属性交换来改变这些网络中的rkk和ρkx。图3显示了悖论区域中的节点分数。虽然与无标度网络相比减少了很多,但我们仍然观察到了一些悖论,特别是在活跃节点比例较大的网络中。
我们还检查了“多数错觉”是否可以在现实世界的网络中表现出来。我们观察了六个不同的网络:高能物理学家合作网络(HepTh)[36],蛋白质-蛋白质相互作用网络(Reactome)[37],社交媒体关注者图(Digg[38]和Twitter[34]),安然电子邮件网络[39],以及代表政治博客(博客)之间链接的网络[40]。所有六个网络都是无定向的。为了使Digg和Twitter的关注者图无向,我们只保留了相互关注的链接,并通过提取最大的连通分量进一步缩减了图。对于安然电子邮件网络,我们删除了用户之间重复的电子邮件通信链接。这些网络的程度分类范围很广,从rkk=0.27(HepTh)到rkk=−0.22(政治博客)。
图4示出对于活动节点的不同部分P(x=1)=0.05、0.1、0.2和0.3经历“多数错觉”的节点部分。随着程度-属性相关性ρkx的增加(使用属性交换过程),几乎所有网络中的相当一部分节点都经历了悖论。这种影响在混杂的政治博客、Twitter和安然电子邮件网络中更大,在这些网络中,为了足够高的相关性,多达60%-70%的节点有超过一半的邻居处于活动状态,即使只有20%的节点处于活动状态。这种效应也存在于相互追随者的Digg网络中,在HepTh合著者和Reactome蛋白质相互作用网络中的影响程度较小。虽然正度分类降低了影响的大小,但与合成网络相比,对真实网络中节点的局部感知也会发生很大的偏差。如果该属性代表一种意见,在某些情况下,即使是少数人的意见在当地也会显得非常受欢迎。
在实证地论证了“多数错觉”和网络结构之间的一些关系之后,我们接下来开发了一个模型,该模型在计算悖论强度时考虑了网络特性。与友谊悖论一样,“多数错觉”植根于节点程度与其邻居之间的差异[22,41]。这些差异导致节点观察到,不仅它们的邻居平均连接更好[22],而且它们也比它们自己具有更多的某些属性[28]。后一种悖论被称为广义友谊悖论,被称为“友谊悖论”。
利用方程(5),我们可以计算任一度序列、联合度分布e(k,k‘)和条件属性分布P(x|k)已知的网络的“多数错觉”悖论的强度。图2-4中的实线报告每个网络的这些计算。使用公式(5)计算“多数错觉”强度所需的条件概率P(x=1|k)=P(x‘=1|k’)只能针对具有“良好”度分布的网络解析地指定,例如形式为p(K)∼k−α的α>;3或P。
..



