使用NLP在7小时内对20万篇文章进行分类
本文由Sculpt AI撰写,由Stanford ML专家Abraham Starosta和Tanner Gilligan与Reza[文章作者]合作构建。
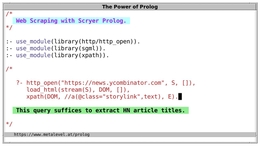
咨询公司时不时会面临不正常的挑战,并创造新的解决方案。去年,我们面临着用非常有限的预算对超过25万篇文章进行分类的问题。我们的目标是,如果我们能以90%的准确率自动对其中的80%以上进行分类,那么我们就可以在预算内手动完成其余的工作;而这正是我们通过使用人工智能所做的。
为什么选择人工智能?因为如果没有它,我们就无法在有限的时间内处理生成的数据量。人工智能不是新事物,自然语言处理也不是新事物。
自然语言处理(NLP)是人工智能的一个分支,与语言学有关。它的重点是教机器如何理解和使用人类语言进行交流。因为语言对我们的生活是如此重要,自然语言编程肯定会为人类创造巨大的价值。事实上,如果我们仔细观察当今一些最有价值的科技公司的内幕,我们会发现NLP为许多关键产品提供动力,如在线搜索引擎、翻译、语音助手、聊天机器人,以及不同行业的更多产品。
如今,谷歌10%的搜索是由深度学习NLP模型Bert提供支持的。这都要归功于深度学习、图形处理器和一种叫做迁移学习的技术。迁移学习的思想是教一个模型如何执行一项任务,这样当我们为一项新的相关任务训练它时,它会有更好的表现。
迁移学习最初在计算机视觉领域非常成功。早在2014年,研究人员就开始了对ImageNet数据集的预培训模型,然后将这些知识“转移”到各种其他任务中,比如物体检测。
直到2018年,NLP才出现了“ImageNet时刻”,当时研究人员开始使用语言建模任务对大量新闻和维基百科文章的文本模型进行预训练。这种方法的一个早期例子是2018年5月的ULMFiT,只有100个标记的例子,它可以用100倍以上的数据与从头开始训练模型(无需预训练)的性能相匹配。
随着一年的过去,我们开始对越来越多的数据进行NLP模型的预培训。这就把我们带到了今天,最新的型号Bert和XLNet接管了这一领域。这些模型的前期培训是由大型科技公司牵头的,然后在某个时候,他们将模型发布给公众。谷歌和其他大公司仅在计算机上就花费了高达6万美元来预先培训XLNet模型。
显然,这是一个复杂的领域,需要数年时间才能掌握。但是,简单地说,NLP的工作原理是检测文本中的不同模式,并尝试将这些模式用于一些有用的应用程序。例如,“单词嵌入”是与我们词汇表中的每个单词相关联的数字向量,根据哪些单词出现在另一个单词附近进行计算。换句话说,它将“告诉我谁是你的朋友,我就告诉你是谁”这句老话套用到文字上。使用这些向量,计算机可以开始求解诸如“男人对于女人就像国王对于_”这样的类比。女王!“。
NLP学术专注于解决许多核心任务,随着它们的进步,这项技术进入了行业,并开启了新的面向人的产品。
摘要:写出一篇文章的简短版本,同时保留其大部分意思。
问答:能够在给定的课文中找到问题的答案。
共指解析:确定像“他”或“她”这样的实体词指的是什么。
文本分类是根据文档或句子的内容将其分配到特定类别的任务。
二进制:当模型的工作是将一段文本分类为两个类别之一时。例如,当人们阅读一封电子邮件并决定它是否紧急时,他们将其分类为“紧急”或“非紧急”。
多类别:当模型的工作是将一段文本分类到三个或更多类别中的一个类别时。例如,当一个人阅读一篇新闻文章,并从许多话题(体育、政治、商业或科技)中决定它在谈论什么话题时。
为了教机器如何自动分类文本,无论是二进制还是多类,我们首先手动标记示例,并将它们提供给文本分类器模型。然后,该模型将在数据中找到模式,并估计每个模式对预测给定标签的信息量有多大。然后,您可以向模型提供全新的示例,以自动预测类别。
文本无处不在:新闻、网站、社交媒体、PDF、电子邮件等等。IBM估计,世界上80%的数据是非结构化的,企业只能看到这些信息的一小部分。这主要是因为阅读文本和提取洞察力对人类来说非常耗时。但是,文本分类可以阅读文档并对其进行分类,或者理解文档中的关键洞察力。这就是为什么想要增加决策和优化流程的组织转向文本分类。
例如,文本分类器可以读取文档,并根据文档类型用不同的颜色突出显示关键见解:
我们的最终目标是自动将一百万个新闻文档分类到4个类别中的一个。要做到这一点,我们需要构建一个多类分类模型,然后使用它来预测我们的百万个文档的标签。
为了构建我们的多类分类器,我们独立地训练了四个单独的二元分类器,每个类别一个。当给出一个例子进行分类时,我们从每个分类器中获得一个标签和置信度得分,然后将它们集成到最终的答案中。
我们已经看到这种模块化设计模式在整个技术行业中被使用,在考虑了所有利弊之后,我们认为在大多数情况下,这是构建和维护多类模型的最佳实践。
标注更简单、更快,因为人工注释员只需要在两个选项之间进行选择,而不是在多个选项之间进行选择。
将来添加新类很容易,因为我们只需要添加另一个二进制模型。
除了手头的多类任务外,我们还可以将二进制模型用于其他应用。
只要我们为我们的每个二进制模型都有足够的示例,我们就不需要太担心类的不平衡。
集中精力构建和评估一个模型更容易,一次一个。
我们可以使用最终用户反馈来持续培训系统。例如,当用户指示来自二进制模型的预测是错误的时,用户实际上是将该示例标记为相反的类别。
可能会导致额外的标记,因为对于不同的二进制模型,可以多次标记相同的记录。
从我们过去的NLP行业经验中,我们了解到,新闻标题往往具有帮助AI做出正确决策的关键信息。因此,给定一个新闻文档,该模型为新闻标题和正文生成单独的向量表示,然后将它们组合起来进行二进制预测。这基本上允许模型为标题中的模式分配与正文中的模式不同的权重,并大大提高了性能。
Sculpt AI由斯坦福大学ML专家Abraham Starosta和Tanner Gilligan与Salt.Agency的ML Experts合作打造,是一个无码的AI平台,通过UI可以快速直观地训练最先进的分类模型。一旦对模型进行了训练,就可以很容易地部署和使用该模型来对新数据进行预测。
雕刻AI使您可以获得更高的精确度,速度最高可提高10倍。为了实现这一点,Sculpt使用了一系列技术,包括弱监督、不确定性抽样和多样性抽样。
弱监督:人工注释员通过突出显示示例中帮助他们做出决定的关键短语,向AI模型解释他们选择的标签。然后,这些突出显示被用于自动生成细微差别的规则,这些规则被组合并用于增加训练数据集并提高模型的质量。
不确定性抽样:它找出模型最不确定的例子,并建议人们对它们进行审查。
多样性抽样:它有助于确保数据集覆盖尽可能多样化的数据集。这确保了模型学会处理所有现实世界的案例。
引导式学习:它允许您在您的数据集中搜索关键示例。当原始数据集非常不平衡时(它包含您所关心的类别的极少数示例),这特别有用。
雕刻AI还通过在您注释时显示有关模型执行情况的实时反馈,使该过程具有交互性和透明性。这样,当您达到期望的性能时,就可以不再给示例贴标签了。您还可以可视化模型用于决策的主要标准,这有助于确保模型的行为符合您的预期。
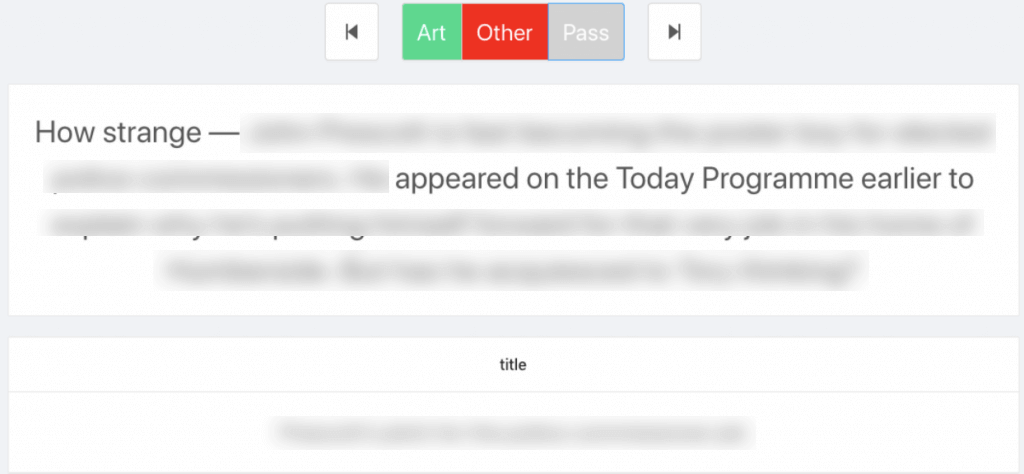
我们首先将文档上传到Sculpt AI,我们的SEO专家花了几个小时通过UI标记示例。在我们贴标签的时候,我们还突出显示了关键短语,作为向人工智能解释我们决定的一种方式。在后台,Sculpt正在实时训练一个模型:第一个是将标记时间减少到原来的1/10(基于使用标准数据集的测试)。
为了实现这一点,Sculpt使用了主动学习、多样性采样、弱监督和使用高亮显示的短语进行自动特征生成的组合。第二个目标是给出实时性能统计数据,这样我们就不必标记任何额外的示例。
例如,我们可以跟踪标记时的精确召回曲线,并决定在对性能满意时进入下一步。
对于定性分析,Sculpt帮助我们将模型对新数据的预测可视化。Sculpt还突出显示了在模型的决策中具有较大权重的主要短语,这有助于他们确保模型使用正确的标准做出决策。最后,我们可以看到每个示例的模型置信度(从0到1的小数)。
为了进行定量分析,Sculpt提供了每个二进制分类器的精度-召回率曲线,以及其各自的曲线下面积(AUC)。Y轴显示模型的精度,X轴显示其回调。
精度:模型做出正面预测时正确的次数百分比。例如,当模型说一篇文章谈论“艺术”时,它多久正确一次?
回想:模型检测到的正面示例的百分比。换句话说,这让我们对该模型的覆盖范围有了一个了解。该模型是否缺少太多示例?
曲线下面积(AUC):它是一个从0到1的小数,表示图形下的面积。如果我们有一个,那它就是一个完美的模型。这让我们对模型的性能有了一个总体的了解。
在机器学习中,总是在精确度和召回率之间进行权衡,因为一个模型可能有非常好的覆盖率,但会犯太多错误。相反,一个模型在一小部分数据上可能是正确的,但却遗漏了许多重要的例子。
最后一步是将四个二进制模型组合成一个多类模型,如上一节所述,并使用它自动对1M个新文档进行分类。为此,我们只需打开UI并上传一个新的文档列表。
Sculpt做了一些计算,并输出了结果,这是一个CSV文件,其中包含我们关心的每个类别的置信度分数,以及新闻文档URL,这样我们就可以很容易地验证它们。这就是我们如何在不到7小时的时间内对20万篇文章进行快速分类的方法。