机器人游戏:65C02语言比较:ASM、OPT ASM、C和FORTH
机器人游戏-GitHub上的传统组装65(C)02是一个8位架构,有三个主要的8位寄存器。A寄存器或累加器用于大多数计算和移动数据。另一方面,X和Y寄存器用于索引到内存中或向上或向下计数1。它们不能用于通用计算,如A。X和Y寄存器的一种用途是遍历内存。例如,您可以通过将索引加载到X中,然后使用以下指令来访问数组的元素:
这会将数组中超出开头X个字节的字节复制到A寄存器中。要遍历整个数组,只需将X递增1并将数据加载到A寄存器(请记住,X不能进行任意计算,只能递增和递减1)。
65(C)02上的前256字节内存是特殊的。这个区域被称为零页。因为零页的地址可以放入8位,而不是所有其他地址的16位,所以处理器可以更快地加载地址和访问该存储器一个周期。由于指令只占用2-7个周期,因此将指令缩短一个周期会带来有意义的加速。因此,稀缺但速度更快的零页内存总是非常宝贵。
许多程序员使用X寄存器作为专用的数据堆栈指针,并将该堆栈保持在零页,因为堆栈内存用于函数中的局部变量,应该尽可能快。在这种情况下,您可以将提供给指令的地址视为堆栈的偏移量。例如,此指令会将第二个项目加载到数据堆栈上(偏移量0将是第一个项目):
65(C)02还具有用于硬件堆栈的称为SP的专用堆栈指针,但与许多架构不同的是,没有允许在偏移量处访问该堆栈的寻址模式。例如,此类型的寻址无效:
为此,X寄存器通常用作数据堆栈指针,而硬件堆栈SP主要用于返回地址。为了将X寄存器用于数据堆栈,每个函数都应该减少X,为局部变量腾出一些临时空间,然后在函数完成局部变量并返回时恢复X。下面是一个例子:
FOO:DEX;减少X以腾出堆栈DEX LDA#5上的两个字节的空间;将数字5加载到A寄存器STA0,X中;将5存储到堆栈INC上的第一字节;将A寄存器中的值从5增加到6 STA1,X;将6存储到堆栈INX上的第二字节;释放堆栈INX RTS上保留的两个字节;从函数返回。
这会在数据堆栈上腾出两个字节的空间,在第一个字节中存储5,在第二个字节中存储6。最后,它恢复X并从函数返回。这种方法很灵活,因为只要还有堆栈空间,函数就可以根据需要使用任意多的局部变量,并且它支持递归。
一个小的改进(突出显示)是添加一个PHX以将X的值保存在硬件堆栈上。这允许我们将函数末尾的两条INX指令替换为PLX,以将X从硬件堆栈中拉出,并将其恢复到函数开始之前的状态。在此设置下,DEX可用于在函数中保留所需数量的字节,而不必在末尾将其与等效数量的INX指令相平衡:
FOO:PHX;将当前数据堆栈指针保存到硬件堆栈DEX;减少X以腾出堆栈DEX LDA#5上的两个字节的空间;将数字5加载到A寄存器STA0,X中;将5存储到堆栈INC上的第一字节;将A寄存器中的值从5增加到6 STA1,X;将6存储到堆栈PLX上的第二字节;从硬件堆栈RTS恢复数据堆栈指针;从函数返回。
一旦分配局部变量的系统就位,就可以用宏缩短代码。不同的汇编器可以具有非常不同的宏功能。宏汇编器AS是一个功能强大的程序,在这个项目中工作得很好。在汇编时将函数和其他结构的状态存储在字符串变量中允许您创建一些功能极其强大的宏,如下所示。我们可以使用更易于阅读的宏来生成上面的代码:
函数foo;声明函数foo vars byte bar,BAZ;在堆栈上为两个字节长度的局部变量END LDA#5腾出空间;将数字5加载到A寄存器STA BAR,X中;将5存储到局部变量BAR INC中;将A寄存器中的值从5增加到6STA BAZ,X;将6存储到局部变量BAZ END中;恢复堆栈指针并返回。
这有几个优点。不需要计算需要多少条DEX指令,因为vars和end宏会处理这些指令。此外,它还允许使用命名变量,这使得函数更易于阅读。下一步是添加对16位变量的支持,其中除了byte之外,我们还可以使用关键字word。下面是另一个示例:
函数FORIES;声明函数FORIES VARS字节葡萄;声明一个字节长的局部变量BANANA,PEAR;声明两个字长的局部变量END LDA PEAR,X;将PEAR的第一个字节复制到香蕉STA BANANA的第一个字节,X LDA PEAR+1,X;将PEAR的第二个字节复制到香蕉STA BANANA的第二个字节+1,X END;恢复堆栈指针并返回。
此代码将16位值PEAR复制到16位值BANANA。这有点单调乏味,因为它需要四个步骤才能完成大多数其他语言中类似于“banana=pear”的操作。使用宏可以将这四行缩短为一行:
这将使16位值的使用变得容易得多。当8位和16位值混合在一起时会发生什么情况:
这会将GRAPE的低字节复制到香蕉的低字节,这是正确的,但然后将GRAPE之后的字节复制到香蕉的高字节,这是错误的,因为GRAPE没有高字节。我们可以通过让字节宏记录GRAPE是一个字节,让WORD宏在声明香蕉时记录它们是一个单词来解决这个问题,这样MOV就可以明智地选择不复制没有高字节的变量。另一方面,在将字节复制到字时,宏会将零复制到目标的高位字节。这使得MOV可以与字节和字的任意组合一起正常工作。
如果只需要将一个字的低位字节复制到另一个字中,会发生什么情况?为此,有一个单独的MOV.B宏,即使类型是WORD,它也只复制一个字节;还有一个MOV.W宏,它复制整个字,而不考虑目标类型。
下一个改进是增加了两个类型的关键字:ZPBYTE和ZPWORD。这些将用于将变量分配给快速的零页内存,但不是通过使用X寄存器来跟踪堆栈上的变量。相反,它们将存储在零页中的固定位置,函数启动时该位置的任何数据都将复制到硬件堆栈,然后在函数结束时恢复。换句话说,这些变量在使用它们的函数的开始和结束时将有几个周期的开销,但是它们的访问速度要快一个周期,因为它们在被访问时没有相对于X寄存器的开销。那么如何知道何时使用每种类型的变量呢?创建ZPBYTE变量的开销约为20个周期,而创建ZPWORD的开销约为33个周期。只要变量被访问的次数足以证明创建时20或33个周期的开销是合理的,用ZPBYTE和ZPWORD声明的变量就会比用byte和word声明的变量快。正如我在下面认识到的那样,我至少选择了一次错误的类型。
下一个难题是将参数传递给函数。为此,有一个与vars宏工作方式类似的args宏:
函数测试;声明函数测试参数byte Foo,bar;函数接受两个字节长度的参数vars ZPBYTE BAZ;在零页末声明一个字节长度的局部变量.结束;还原堆栈指针并返回。
这将为函数分配两个字节的输入。值与CALL宏一起传递:
这会将#5复制到foo,将value复制到bar,然后跳到标签test。这样做的方便之处在于,因为Call在内部依赖于MOV.B和MOV.W,所以它可以正确地将数据复制到函数的传入参数中,而不考虑类型。它还知道在用byte和word声明的变量名的末尾添加“,X”,并在复制时对用ZPBYTE和ZPWORD声明的变量不加“,X”。函数可以返回名为ret_val的专用全局变量中的值。如果需要,调用者可以将值从那里复制到自己的内存中。
最后一个数据类型是字符串,通常功能类似于字,因为字符串的地址是一个16位数字。唯一的区别是可以将文字字符串传递给CALL宏,在这种情况下,该字符串将嵌入到程序中,并将其地址填充到字符串变量中。这两个示例等效:
STRING_ADDRESS:DB";Hello,World!";,0;文字字符串数据.调用DrawText,string_address;调用DrawText传递STRING_ADDRESS调用DrawText,";Hello,World!";;调用直接传递字符串的DrawText。
宏观难题的最后一块是添加结构关键字,如if和switch。不幸的是,那些已经被汇编程序占用了,所以我使用了if_eq,而不是使用它。我为IF语句添加了几个别名,比如IF_EQ的IF_0和IF_FALSE,以使源代码更具可读性。宏会跟踪所有结构的嵌套情况,因此它们可以自由嵌套和混合。这里有一个例子:
函数测试参数字节值,辅助变量字结果结束.哪个值;开关(值)如#0;值==0 MOV#1234,RESULT;将16位立即数复制到变量RESULT,如#1,#2,#3;VALUE==1,2或3 MOV#5678,RESULT;将16位立即数复制到变量RESULT,如#4;VALUE==4 LDA SUBCENT,X IF_0;如果变量SUBJENT==0 MOV#ABC,RESULT_IF;如果变量SUBCED!=0 MOV#DEF,结果END_IF DEFAULT;上述情况与MOV#0不匹配的默认情况,结果结束.端部。
这看起来比纯组装要干净得多。让这些宏工作是向移植游戏迈出的一大步,并使使用汇编语言变得更加愉快。还有一些其他的宏可以让事情变得更简单,比如INC.W和ROR.W。
有几个减速带创造了这个版本的游戏。实现随机数生成器让我困惑了一段时间。这是我在一个复古编程网站上找到的算法:
汇编中的生成器的输出在许多循环中都是正确的,然后在某一点上与C版本背道而驰。这会导致随机生成的贴图看起来很接近,但与其他版本不同。(在Python中测试输出时,我意识到了一个有趣的特性,即该算法在重复之前只生成一次每个16位的值。)。此算法在8位体系结构上非常方便,因为将16位值左移7等同于仅将低位字节右移一次,然后将其移至高位字节。在下一行向右移位9也非常有效,因为这相当于将高位字节切换到低位字节,然后向右移位一次。65(C)02一次只能移位一位,因此将这些参数减少到一位移位会使它们的效率大大提高。我遇到的问题是,右移一次以完成7的左移需要在一次右移期间移入一位来填充16位值的最高有效位。因为我错过了这一点,所以在发散之前,随机值碰巧有一段时间是正确的。
这是一个重要的教训。汇编语言比其他语言需要更长的编写时间,特别是当你考虑到在其他语言中不会犯的错误时。这个算法太简单了,用C语言不会搞砸,但是在我意识到我在汇编中的错误之前,我花了很长时间在这上面。
另一个挑战是组装需要多长时间。如上所述,很多代码严重依赖宏。宏汇编器AS在每次调用时都会将整个宏体复制到源代码中,其中包括所有未采用的代码路径。例如,MOV.w宏长超过200行,因此汇编程序生成的汇编列表对于源代码中的每个MOV.W都会增长该长度。这会导致清单在每次组装时膨胀到26MB以上,这可能需要长达10秒的时间。Python脚本会过滤掉清单中的所有多余行,以便在加载到模拟器中时看起来是正确的。对于我要构建的计算器,当程序大小增加10倍或更多时,长的汇编时间将是不切实际的。
最后一个问题是试图在汇编中创建等效的结构数组。这就是我如何存储与放置在地图上的怪物和水晶相关的信息。在C语言中,编译器将计算出结构的大小,并将数组索引乘以该值以访问结构的正确成员。在汇编中,我硬编码了一系列移位和加法,以完成基于结构大小的乘法,因为它是常量。不幸的是,我计算错了大小,浪费了很多时间试图找出为什么数据是错误的。这种类型的错误在C中不会发生,因为编译器会为您进行计算。
GitHub 65C02上的机器人游戏优化程序集GitHub上的程序集优化器此版本基于上面的传统程序集版本,因此移植它不需要太多工作。主要任务是重写上面的所有宏,以便与我的汇编优化器程序配合使用。为此,我从使用宏汇编器改为使用NASM,它实际上是一个x86汇编器。NASM允许您在不检查文件是否包含有效指令的情况下定义和展开文件中的宏,因此在65C02程序集上运行它是没有问题的。它还有一个更好的动态定义符号和标签的系统,使我可以将有用的信息从宏传递到优化程序。这是编译过程:在65C02源代码上运行NASM。宏被扩展,支持If和Which这样的结构。局部变量被标识,但没有分配地址。将处理过的汇编指令输出到文件。
将处理后的程序集文件从NASM传递到程序集优化器Python脚本。优化器为局部变量分配最佳零页地址,并将处理后的程序集输出到文件。
将处理后的程序集文件从优化器传递到宏汇编器,后者输出一个二进制文件。
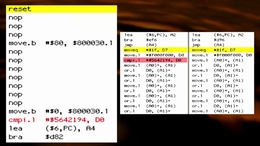
优化器从跟踪每个函数调用哪些函数开始,从第一个函数开始。它还记录每个函数需要多少字节的本地内存,由NASM展开的宏已经标识。根据此信息,它构建了一个调用图:
优化器通过使用调用图信息为每个变量在快速零页内存中查找没有被该函数调用的任何函数重用的地址,从而将内存地址分配给本地内存。例如,在上图中,函数main和clrscr必须为其局部变量分配不同的地址。如果不是,main存储在其指定地址的数据将被clrscr使用的局部变量覆盖。另一方面,函数clrscr和putc可以被分配相同的存储器地址。从上图可以清楚地看出,putc和clrscr从不互相调用,也不会调用调用它们中任何一个的函数,因此它们重用相同的内存是安全的。下面是优化器输出的内存分配表:
每行代表一个字节的快速零页内存,每个框代表一个使用该字节内存的变量。如表所示,在这个小示例中,字节2由六个不同的函数使用。如上所述,putc和clrscr的内存重叠,main使用与clrscr不同的内存部分。
在编译时将固定的零页地址分配给局部变量意味着它们不再需要索引到X寄存器。这有几个优点:
访问零页中的固定地址要快一个周期。例如,地址在零页的LDA地址是3个周期,而LDA地址X是4个周期。
X寄存器现在可以免费用于其他用途。在不被独占为数据堆栈指针的情况下,X可以用于所有其他类型的东西,如循环计数器。例如,每次用INX通过循环递增X是2个周期,而将计数器存储在数据堆栈上并用INC计数器递增时,X是6个周期。
没有函数开销。每次调用函数时,必须调整X寄存器以在数据堆栈上腾出空间。在函数开始时将X寄存器保存到硬件堆栈并在结束时恢复它需要7个周期。用于调整数据堆栈指针的局部变量的每个字节的DEX多花费2个周期。
一种类型的本地存储器。使用传统的汇编宏,我必须选择是使用byte和word在X索引的数据堆栈上保留本地变量空间,还是使用ZPBYTE和ZPWORD临时释放零页中的本地变量空间。在将游戏移植到传统组装时,我至少有一次做错了这个权衡。使用优化器,所有变量都具有ZPBYTE和ZPWORD的速度,没有任何开销。
;传统汇编函数mult5;将一个数字乘以5个参数字节数变量字节计数器End LDA#5;循环计数器STA计数器,X LDA#0;product=0。loop:CLC ADC Num,X;Add Number DEC Counter,X;COUNTER--BNE。循环MOV.B A,ret_val end。
;优化汇编FUNC mult5;将一个数字乘以5个参数字节数;计数器存储在X中,而不是结束LDX#5;循环计数器LDA#0;product=0。loop:CLC ADC num;ADD NUMBER DEX;COUNTER--BNE.LOOP MOV.B A,ret_val end。
;传统组件mult5:PHX DEX LDA#5 STA 1,X LDA#0.loop:CLC ADC 0,X DEC 1,X BNE.loop STA ret_val STZ ret_val+1 PLX RTS END。
;优化的汇编mult5:;无堆栈调整开销LDX#5 LDA#0.loop:CLC ADC 2;1周期更快的DEX;4周期更快的BNE.loop STA ret_val STZ ret_val+1;无堆栈恢复开销RTS end
优化后的版本体积更小,周期更短。这在循环中尤其重要,在循环中,节省的周期比减少的函数开销重要得多。
在运行优化器和新的基于NASM的宏之后,将传统汇编版本转换为此版本相当简单。有趣的是,传统版本只将X寄存器用于数据堆栈,因此我不需要更改任何使用X的游戏代码就可以使优化版本工作。这是因为优化版本使用的宏都不会触及X,因此它在所有函数中都保持不变,并且提供给访问局部变量的所有指令的偏移量现在都是优化器分配的地址。在优化版本中查找并删除所有对X的引用节省了大量周期。返回并用新的空闲X替换一些计数器变量,将优化程序的速度提高了1%。
机器人游戏-GitHub上的传统汇编将游戏移植到C语言的第一步是启动并运行CC65编译器。在一切正常之前,最初的四个小时是与链接器脚本和无意义的“范围错误”消息进行斗争的。从…。
.