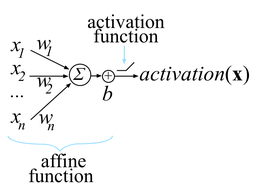
编译器的深度学习
构建编译器很困难。优化编译器是耗资数百万美元的项目 多年来的发展,但仍然无法充分利用可用的性能, 并且很容易被窃听。快速过渡到异构并行和 多样化的体系结构提高了对积极优化编译器的需求 一直居高不下,使得编译器开发人员难以跟上。我们需要的是 简化编译器构造的更好工具。 本文提出了显著降低编译器成本的新技术 构造,同时提高健壮性和性能。实现以下目标的洞察力 这项研究是利用深度学习来模拟 源代码和程序行为,支持以前需要大量 工程工作要实现自动化。这在三个领域进行了演示: 首先,建立了编译器基准测试的产生式模型。该模型需要 没有编程语言的先验知识,但会产生这样的输出 专业软件开发人员无法区分从手写生成的质量 程序。生成器的有效性通过补充 用于编译器优化的预测模型的训练数据。生成器产生一个 启发式性能的自动改进,并暴露了现状中的弱点 ART方法,经过修正后,可进一步提高性能。 其次,开发了一种比现有技术简单得多的编译器模糊器。 通过学习生成性模型,而不是从头开始设计生成器,它是 实现的代码行数比最先进的少100行,但能够 暴露了现有技术不能暴露的缺陷。一场广泛的测试活动揭示了 OpenCL编译器中存在67个新错误,其中许多错误现已修复。 最后,本文提出了特征设计面临的挑战。一种解决问题的方法论 提出了一种学习编译器启发式算法,与现有方法相比,学习编译器启发式算法 直接覆盖程序的原始文本表示。该方法的性能优于 最先进的型号,具有手工设计的功能,具有两个具有挑战性的优化 不需要任何专家指导。此外,该方法使 在一项任务中接受训练的模型将被改编成执行另一项任务,从而允许这部小说 在优化问题域之间传输信息。 在这三个截然不同的领域中开发的技术展示了令人兴奋的 深度学习在简化和改进编译器构造方面的潜力。这个 本论文的成果为编译器开发人员提供了新的研究思路,使其能够 跟上快速发展的异构架构格局。
动态编译系统面临的主要挑战是检测和 将频繁执行的程序区域转换为高效的本机代码 越快越好。要有效地减少动态编译...。
设计编译器以使其生成优化的代码是一项艰巨的任务,因为现代 处理器很复杂。编译器编写者需要花费几个月的时间来微调启发式 任何建筑,但是每当一个新的..。
编译器优化是使编译器产生更好的代码的过程,即, 例如,在目标体系结构上运行得更快。尽管许多程序转换 因为最佳化一直是..。