斯坦福大学的一项研究表明,运动跟踪的VR数据可以识别
虚拟现实(VR)是一项正在消费者市场获得吸引力的技术。随之而来的是一种前所未有的跟踪身体运动的能力。这些身体动作是对个人身份、医疗条件和精神状态的诊断。以前的工作集中在理想化情况下身体运动的可识别性,在这种情况下,研究设计者选择了一些动作。相比之下,我们的工作是在典型的VR观看环境下测试用户的可识别性,没有专门设计识别任务。在511名参与者中,当对每人不到5分钟的跟踪数据进行培训时,系统正确识别了95%的用户。我们认为,这些结果表明,非语言数据应该被公众和研究人员理解为个人识别数据。
虚拟现实(Virtual Reality)是一种利用计算技术来创建模拟环境的技术,近年来使用激增1。为了从用户的角度呈现虚拟世界,必须计算和跟踪用户的位置。所有的VR系统都测量头部方向,大多数测量头部位置,还有很多测量手部方向和位置2。虽然不太常见,但一些系统可以跟踪脚、胸部,甚至手肘和膝盖,以增加沉浸感3。对于关心隐私的用户来说,这些数据是一个问题。VR提供的跟踪数据可以是可识别的。
与以前专注于设计VR任务来识别或验证用户4、5、6的工作不同,我们从一个不是为识别而设计的任务开始。事实上,我们使用的跟踪数据来自一项研究7,其目的是检查运动、自我报告情感数据和视频内容之间的关联。
此外,目前的工作是独特的,因为它使用了一个非常大的(超过500个)和多样化的样本,主要来自大学以外的地方。样本的这两个特征在理论上是相关的。首先,在小样本中的识别可能高估了某些特征的诊断能力,因为身体大小和其他方差来源没有重叠。其次,不同的人可能有不同类型的身体运动。例如,这项研究有60多名55岁以上的参与者,这一群体的运动很可能与典型的大学生不同。
如果跟踪数据本质上是可识别的,那么随着VR变得越来越流行,这对隐私有重要的影响。最紧迫的一类问题属于去识别数据的过程。发布研究数据集或共享VR数据以删除任何可以识别参与者或用户的信息是标准做法。在Oculus和HTC的隐私政策中,这两家公司都被允许分享任何未识别的数据。Oculus和HTC是2020年最受欢迎的两款VR头盔的制造商。如果跟踪数据是根据未识别数据的规则共享的,那么无论原则上承诺什么,从数据集中删除一个人的名字实际上收效甚微。
第二类威胁广泛涉及将VR会话链接在一起的改进能力。以前分散和分离的信息现在可以通过“运动签名”连接在一起。例如,在将一些跟踪数据连接到名称时,现在许多其他地方的跟踪数据都附加到相同的名称。这提高了基于从跟踪数据推断受保护的健康信息的威胁的有效性(例如,请参阅相关工作)。
第三类威胁来自私人浏览。原则上,有一种方法可以在网络浏览器中进入私人浏览模式。虽然这可能很困难,并且需要许多工具来隐藏多层信息,但这是可能的。有了准确的虚拟现实跟踪数据,私人浏览模式原则上是不可能的。
仅使用位置跟踪数据,我们发现,即使有500多个参与者可供选择,一个简单的机器学习模型也可以从不到5分钟的跟踪数据中识别参与者,准确率在95%以上。因此,我们提供的数据表明,典型的虚拟现实体验产生了识别数据。此外,通过检查不同类型的模型和不同的特征集,我们阐明了识别背后的可能机制,这也提出了防止滥用的策略。
本文首先回顾了相关工作的两条主线:通过跟踪数据识别用户的方法,以及对VR隐私的关注。其次,介绍了实验装置和数据采集过程。最后,报告了各个识别任务的结果,并对结果进行了讨论。
以前的工作使用跟踪数据来识别用户,但识别是正面的,通常是作为身份验证的工具。VR的持续采用引发了人们对VR跟踪数据的担忧,认为这是一个隐私问题。
VR跟踪数据作为身体姿势和运动的衡量标准,是一个令人惊讶的强大信息来源。各种身体运动和创造力8、学习9和其他行为结果10之间存在联系。
此外,在跟踪数据中捕获的行为可以与诸如ADHD 11、自闭症12和创伤后应激障碍13等医疗状况相关联。也有越来越多的文献使用跟踪数据来诊断痴呆症14、15、16。
从这些例子中,出现了一种模式。这些测试中的每一个都是一个日常场景,实验者在其中测量一些已知的表明某种医学状况的行为(例如,分心、对脸的注意力、运动规划中的持续时间)。仅仅通过跟踪数据就能找到这些关联的能力已经引起了研究人员对虚拟现实17中隐私的关注。
18岁的霍斯费尔特讨论了身临其境的媒体伦理,并指出了收集非自愿非语言互动的力量。我们期望的私有响应可能会在我们不知道的情况下被算法快速检测到。Vitak等人。19在网络隐私的更大背景下讨论VR隐私。与许多隐私问题一样,问题在于用户获得的收益是否超过了担忧。
先前关于识别头盔显示器用户的工作已经使用了不同类型的生物测定测量。最常见的是通过设备4、6、20、21中的惯性测量单元的头部旋转和加速。随着VR头戴式耳机的普及,头戴式耳机和手控制器的位置和方位数据成为更常见的数据源5、22。
确定用户身份的目的可以是为了认证或识别。我们遵循罗杰斯等人的区别。6在认证和识别之间做出选择。身份验证需要强有力的确凿证据,将单个用户与系统的任何其他用户区分开来,并且通常会导致权限提升(例如,访问敏感数据或运行更强大的命令)。另一方面,标识是任意(但有限)数量的用户的预定义集合内的用户的匹配。例如,标识可用于自动应用用户首选项或创建个性化广告。
以前的工作主要集中在寻找可以识别用户的任务。例如,用户可以响应音频剪辑点头,创建“动作密码”20。人们一直感兴趣的是减少这些验证任务的侵扰性。例如,Kupin等人。22名用户在做投掷动作时进行跟踪,穆斯塔法等人。4当参与者在房间中走动时跟踪。然而,在从毫无识别意图的体验中收集的数据中确定身份方面所做的工作很少。
参与者观看了360度的视频,并在VR中回答了问卷。对跟踪数据进行总结和处理,作为三种机器学习算法的输入。这项研究是由斯坦福大学IRB根据43879号协议批准的,所有的方法都是根据这些指南进行的。
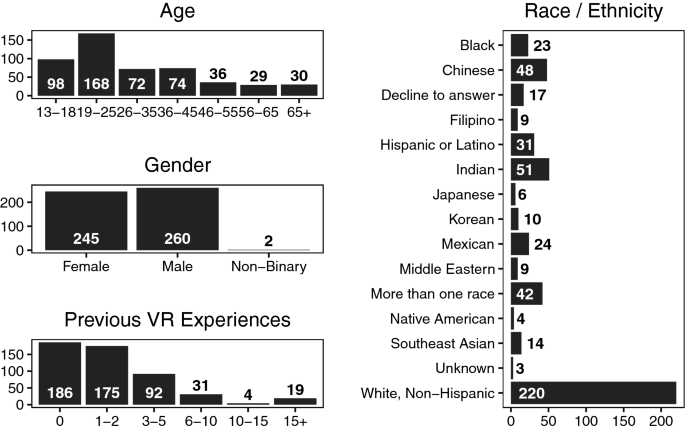
总共招募了548名参与者参与这项研究。在这些人中,10人不允许将他们的跟踪数据作为分析的一部分,27人出于各种原因之一没有完成这5个视频:7人为节省时间提前结束,通常是因为他们预订了另一项博物馆活动,6人在被问及时没有说明原因,5人无法阅读调查文本,4人因模拟器疾病或眼睛疲劳而结束,3人因内容结束(2人不喜欢人群,1人不喜欢动物),2人因不舒服的耳机安装而结束。总共有511名参与者完成了实验。博物馆里有378个,校园里有133个。人口统计信息如图1所示。年龄是以范围给出的,而不是原始值,因为选定的参与者不能输入他们的年龄,而是从七个选项中选择一个。种族和民族是使用改编自2010年美国人口普查的类别给出的。可以在研究的在线储存库23中找到每个问题的全文及其答案选项。
研究参与者的人口统计信息(年龄、性别、以前虚拟现实经历的数量,以及种族和民族)的直方图。
所有成年参与者都阅读并签署了IRB批准的同意书。对于18岁以下的参赛者,需要得到孩子的同意和父母的同意。如果博物馆的参与者选择不参与研究,他们仍然可以选择观看360个视频,而不收集他们的数据。
使用HTC Vive虚拟现实耳机和控制器24显示虚拟现实内容。校园内的实验空间如图2所示。
实验装置。左上角:其中一个360度视频的截图。右上角:VR问卷的截图。左下角和右下角:合著者在实验过程中演示观看视频和回答调查过程的照片。
正在讨论的虚拟现实内容由5个360度视频组成,每个视频20分钟长,从80个视频中随机选择。这些视频被收集到价位(积极与消极)和唤醒(平静与兴奋)的范围内。对于每个视频,从原始摄像人员处获得了显示视频并允许研究人员重复使用的许可,并且所有视频都可以通过研究储存库23获得。
所有视频都本地存储在连接到VR耳机的计算机上。这些视频的帧率从23.97到120不等,低于29.97fps的视频有8个,帧率在29.97到30fps之间的视频有66个,超过30fps的视频有6个。这些视频的分辨率从1920×960像素到4096×2048像素不等,其中39个视频位于这个范围的最高端。
鉴于360度视频可提供任何方向的观看,考虑内容本身对运动的影响也很重要。如果内容导致许多人以相似的方式移动,通过运动进行识别可能会更加困难。可能导致这种情况的两个特征是口述和视频焦点的强度。没有外部解说员告诉观众往哪里看的视频,但有16个视频可以听到人的声音,其中9个可以辨认出特定的单词和特定的说话者。在摄像机周围走动的单一动物(如大象、狒狒、长颈鹿)的视频中,视频的焦点最强,而在树木四面八方可见的自然场景的视频中,焦点最弱。具有场景更改、摄像机旋转或抖动摄像机运动的视频事先被排除。只有一段视频涉及摄像机的运动,而且摄像机是以缓慢的恒速移动的。
研究人员在两个地点招募了参与者:一个位于大城市的技术博物馆,另一个是来自一所大学的学生。研究人员使用同意书获得了所有18岁以上参与者的知情同意。对于18岁以下的参与者,父母或法定监护人通过父母同意表给予知情同意,参与者通过同意表给予同意。在征得同意后,研究人员为参与者设置了VR耳机和手控器,确认了耳机的适合性和舒适性,并开始了虚拟现实应用。
在虚拟现实应用程序中,参与者回答了一份人口统计调查问卷。当这些问题完成后,程序随机选择了五个视频。对于每一个视频,程序向参与者展示视频,然后提示参与者关于价格、唤醒25、存在、模拟器疾病和分享内容的愿望的问题。问卷的全文可在研究储存库23中获得。与这些问卷内容有关的实质性结果已经在单独的出版物7中进行了调查,重点是虚拟现实的内容和使用。一旦参与者回答了这些问题,程序就会加载另一个视频,显示该视频,并提示另一轮问题。博物馆的378名参与者重复了5次,校园的133名参与者重复了8次。在当前论文中报告的分析中,忽略了该大学在5号之后进行的任何试验,以确保数据集的一致性。
当最后的视频被显示后,研究人员帮助参与者走出VR耳机,回答任何问题,并听取参与者关于实验的简报。
以90 Hz的频率收集原始跟踪数据。数据采集率稳定,只有0.05%的帧出现在前一帧之后超过30ms。在每一帧中,记录时间戳和按钮按下,以及耳机、左手控制器和右手控制器的6自由度(即位置和旋转)。
三个位置维度表示为X、Y和Z。在Unity约定中,开发虚拟现实体验的游戏引擎是在其中开发的,Y轴是垂直的,Z轴是向前-向后的,X轴是从左向右的。这三个旋转维度是偏航(围绕垂直轴旋转)、俯仰(围绕左右或X轴向上或向下倾斜的旋转)和侧滚(围绕前后或Z轴旋转)。其中一些测量具有直接的空间意义,例如y轴捕捉被跟踪对象(耳机或手控器)离地面的高度,以及耳机偏航指示参与者正在观看的水平方向。
为了将数据总结成适合于机器学习算法的样本、多维向量,跟踪数据被分成1-s块。为汇总统计数据(最大、最小、中值、平均值和标准差)、身体部位(头部、左手、右手)和尺寸(x、y、z、偏航、俯仰和侧滚)的每个组合计算一个值。这导致每个视频会话的每秒都有一个90维向量。将可变长度数据分成块并汇总块的过程是在先前的身体运动和识别方法5中执行的过程。总共有61,121个样本在视频任务中,115,093个样本在调查任务中。细分每人的样本数量,平均有345个样本,一个阶段
这些样本是在每个参与者的十个会话中收集的,通过每个视频(其中有五个)的开头和正在执行的任务(观看视频或回答相应视频之后的调查)来描述。按照每届会议的样本数量划分,平均有34.5个样本,标准偏差为16个样本,范围从13个样本到178个样本。
准确性是根据每个会话而不是每个样本给出的预测来评估的(即,观看一个视频的每个会话时间的单个预测,或者回答一个视频的调查,而不是每秒的预测)。这是通过收集任务中每一秒的预测作为选票,并将该会话的预测指定为得票最多的预测来实现的。
遵循Pfeuffer等人的观点。5、分类准确率(即正确预测占总预测的百分比)是选择的性能度量。虽然相关论文使用相同的错误率4、20或平衡准确率6,但它们是风险不对称的认证任务。假阴性是用户的烦恼,但假阳性会损害系统的安全性。在像我们的工作这样的识别任务中,我们假设错误的代价与真实的和预测的类别无关。此外,每个类中都有相同数量的示例,因为预测是按会话而不是按秒进行评估的,因此天真的最常见条目分类器的性能不可能比机会好(1/511,约0.2%)。因此,分类准确性提供了一种公正、易于理解的性能度量。
除非另有说明,本文报告的准确值来自20次蒙特卡罗交叉验证的平均值,按参与者和任务分层。对于每个参与者和任务,随机选择一个会话的数据,并将其从培训过程中删除。一旦对模型进行了训练,就会根据遗漏的数据对其进行测试。然后,丢弃旧模型,进行新的训练和测试拆分,并对新模型进行评估。
试验了三种机器学习模型:K近邻(KNN)26、随机森林27和梯度助推机28(GBM)。所有的方法都运行在R版本3.5.3中,其中“class”版本7.3-15,“随机森林”版本4.6-14,以及“GBM”版本2.1.5。
虽然以前的工作使用支持向量机(SVM)来识别用户,但支持向量机并不直接支持多类分类。常用的支持向量机R库‘e1071’通过训练O(N2)个一对一分类器(每对类一个分类器)来解决这个问题。不幸的是,这意味着需要训练超过100,000个SVM分类器,这在现有机器上计算起来很困难。
KNN、随机森林和GBM的选择有不同的动机。最近邻近似是一种健壮的算法,它很容易理解,只需很少的统计背景26。随机森林方法在之前的身体运动识别任务5、6中取得了成功。GBM类似于随机森林,因为两者都使用决策树,但不是创建许多树来对称为集合模型的预测进行投票,而是对每棵树进行训练,以减少在称为增强的过程中的后续错误。GBM可以创造比随机森林更准确的预测,但通常需要更多的树木才能做到这一点。
每个算法接受90个元素的运动汇总矢量作为输入,并且它输出表示511个参与者之一的分类预测。对于kNN,在计算点之间的欧几里得距离之前,每个变量被归一化为均值0和方差1。RandomForest参数设置为R默认值,但训练了100棵树。GBM用20棵树运行,交互深度为10,每个节点至少有10个观测。由于在511类之间进行分类的计算强度较大,GBM模型中的树木数量较少。这可能会降低算法的性能。
一旦对算法进行了比较,我们将选择其中最成功的算法进行进一步的分析。
使用VR跟踪数据,评估模型以确定如何以及何时可以进行识别。
首先必须问的问题是,VR是否能产生识别信息。分类准确性报告如下。所有算法的性能都比Chance好得多,但随机森林和KNN的性能最好(图3)。
.



