比较数据版本控制工具-2020
无论您使用的是逻辑回归还是神经网络,所有模型都需要数据才能进行训练、测试和部署。管理和创建用于这些模型的数据集需要大量的时间和空间,并且可能会由于多个用户更改和更新数据而很快变得混乱。
这可能会导致意想不到的结果,因为数据科学家继续发布新版本的模型,但针对不同的数据集进行测试。许多数据科学家可以在相同的几组训练数据上训练和开发模型。这可能会导致对数据集进行许多细微的更改,一旦部署了模型,可能会导致意想不到的结果。
这篇博客文章讨论了管理数据带来的许多挑战,并提供了机器学习和数据版本控制的顶级工具的概述。
管理数据科学和机器学习模型的数据集和表格需要数据科学家和工程师投入大量时间。从管理存储、数据版本到访问,一切都需要大量的手动干预。
训练数据可能会占用大量的Git存储库空间。这是因为Git是为了跟踪文本文件(而不是大型二进制文件)中的更改而开发的。因此,如果团队的训练数据集涉及大型音频或视频文件,这可能会在下游造成很多问题。对训练数据集的每次更改通常都会导致存储库的历史记录中出现重复的数据集。这不仅会创建一个大型存储库,还会使克隆和重建基址变得非常缓慢。
当试图管理版本时,无论是代码还是UI,都有一种普遍的趋势--甚至在技术人员中也是如此--通过在文件名的末尾添加版本号或单词来“管理版本”。在数据上下文中,这意味着一个项目可能包括data.csv、data_v1.csv、data_v2.csv、data_v3_finalversion.csv等。这个坏习惯已经超出陈词滥调,因为大多数开发人员、数据科学家和UI专家实际上都是从糟糕的版本控制习惯开始的。
在生产环境中工作时,最大的挑战之一是与其他数据科学家打交道。如果您没有在协作环境中使用某种形式的版本控制,文件将被删除、更改和移动;并且您永远不会知道谁做了什么。此外,将您的数据恢复到其原始状态将是困难的。这是管理模型和数据集的最大障碍之一。
数据版本控制是自动化团队机器学习模型开发的关键之一。虽然如果您的团队试图开发自己的系统来管理流程,情况可能会非常复杂,但情况并非如此。
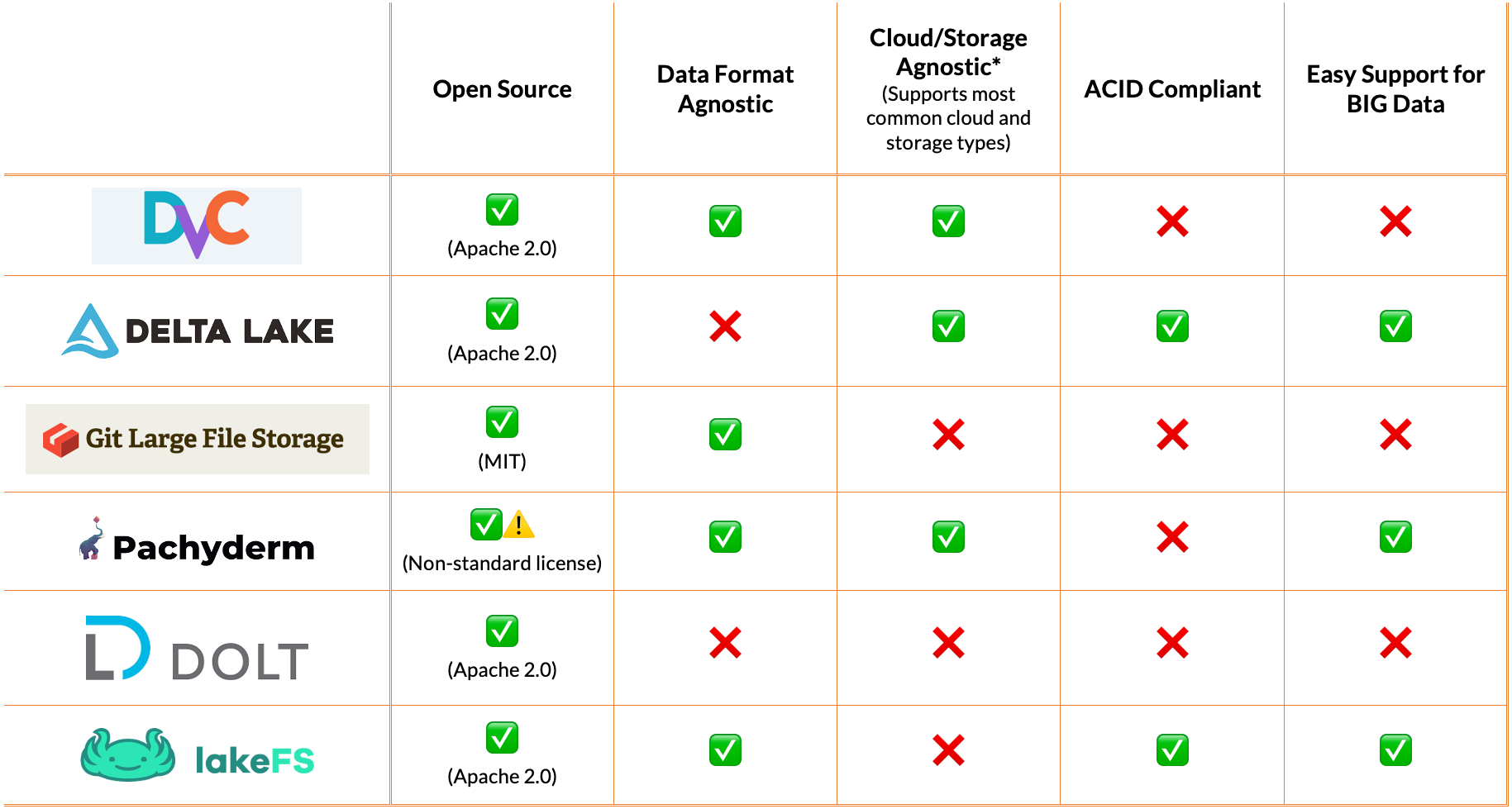
让我们探索您的团队可以用来简化数据管理和版本化的六个伟大的开源工具。
DVC,即数据版本控制,是众多可用开源工具之一,可帮助简化您的数据科学和机器学习项目。该工具采用Git方法,因为它提供了一个简单的命令行,只需几个简单的步骤就可以设置。顾名思义,DVC不仅仅专注于数据版本控制。它还帮助团队管理他们的管道和机器学习模型。最后,DVC将有助于提高您的团队的一致性和模型的重现性。
DVC版本控制与管道管理紧密耦合。这意味着如果您的团队已经在使用另一种数据管道工具,将会存在冗余。
DVC是轻量级的,这意味着您的团队可能需要手动开发额外的功能以使其易于使用。
Delta Lake是帮助改善数据湖的开源存储层。它通过提供ACID事务、数据版本控制、元数据管理和管理数据版本来做到这一点。
该工具更接近于数据湖抽象层,填补了大多数数据湖受限的空白。
提供当前数据存储系统中可能没有的许多功能,例如ACID事务或有效的元数据管理。
减少实际操作的数据版本管理和处理其他数据问题的需要,使开发人员可以专注于在其数据湖之上构建产品。
三角洲湖对大多数项目来说往往是矫枉过正的,因为它的开发是为了在星火和大数据上运行。
需要使用专用的数据格式,这意味着它不太灵活,并且与您当前的格式无关。
工具的主要目的是更像一个数据抽象层,这可能不是您的团队所需要的,并且可以让需要轻量级解决方案的开发人员绕道而行。
Git LFS是由许多开源贡献者开发的Git的扩展。该软件旨在通过使用指针来消除可能添加到存储库中的大文件(例如,照片和数据集)。
指针的权重较轻,并且指向LFS存储。因此,当您将repo推送到主存储库中时,更新不会花费很长时间,也不会占用太多空间。
使用与Git存储库相同的权限,因此不需要额外的权限管理。
Git LFS需要专用服务器来存储您的数据。反过来,这最终会导致您的数据科学团队陷入困境,并增加工程工作。
与DVC不同,Git LFS服务器并不意味着可伸缩,DVC将数据存储到更通用的、易于伸缩的对象存储(如S3)中。
非常具体,可能需要使用许多其他工具来执行数据科学工作流程的其他步骤。
Pachyderm是这份榜单上为数不多的数据科学平台之一。Pachyderm的目标是创建一个平台,通过管理整个数据工作流程,使机器学习模型的结果重现变得容易。在这一点上,Pachyderm是“数据码头”。
Pachyderm利用Docker容器打包您的执行环境。这使得复制相同的输出变得很容易。版本化数据和Docker的结合使得数据科学家和DevOps团队可以轻松部署模型并确保其一致性。
Pachyderm致力于其数据科学权利法案,其中概述了该产品的主要目标:可重复性、数据来源、协作、增量、自治性和基础设施抽象化。
这些支柱驱动了它的许多功能,并允许团队充分利用该工具。
基于容器,使您的数据环境可移植,易于迁移到不同的云提供商。
由于有如此多的移动部件,比如管理Pachyderm的免费版本所需的Kubernetes服务器,所以更多的是学习曲线。
有了所有不同的技术组件,要将Pachyderm集成到公司现有的基础设施中可能很困难。
就数据版本控制而言,DORT是唯一的解决方案。与提供的其他一些简单地将数据版本化的选项不同,Dolt是一个数据库。
DORT是一个SQL数据库,具有Git样式的版本控制。与Git不同,在Git中可以对文件进行版本控制,而对表格进行推拉版本化。这意味着您可以更新和更改数据,而不必担心丢失更改。
虽然这款应用程序还很新,但有计划在不久的将来使其100%兼容Git和MySQL。
Dolt是一个数据库,这意味着您必须将数据迁移到Dolt才能获得好处。
为版本化表构建。这意味着它不会涵盖其他类型的数据(例如图像、自由格式文本)。
LakeFS允许团队构建可重复的、原子的和版本化的数据湖操作。它是这一领域的新人,但很有影响力。它提供了一个类似Git的分支和版本控制模型,旨在处理您的数据湖,可扩展到PB级的数据。
与Delta Lake类似,它为您的数据湖提供了酸法规遵从性。然而,LakeFS同时支持AWS S3和Google Cloud Storage作为后端,这意味着它不需要使用Spark来享受所有好处。
为易于使用的云存储(如S3和GCS)提供ACID事务等高级功能,同时与格式无关。
易于扩展,支持超大型数据湖。能够为开发和生产环境提供版本控制。
LakeFS是一个相对较新的产品,因此与其他解决方案相比,功能和文档的变化可能会更快。
专注于数据版本控制,这意味着您将需要使用许多其他工具来执行数据科学工作流的其他步骤。
对于数据版本化的所有好处,您并不总是需要投入大量精力来管理您的数据。例如,很多数据版本控制都是为了帮助跟踪随时间变化很大的数据集。
一些数据,如Web流量,仅附加到。这意味着添加了数据,但很少更改。这意味着创建可重现结果所需的数据版本化是开始日期和结束日期。注意这一点很重要,因为在这种情况下,您可能能够避免上面提到的所有工具的设置。您仍然需要管理开始日期和结束日期,以确保每次测试的数据以及您正在创建的模型都是相同的。但是,在这些情况下,您不一定需要将所有数据提交到您的版本控制系统。
管理数据版本是数据科学团队避免输出不一致的必要步骤。
无论您使用的是Git-LFS、DVC还是讨论的其他工具之一,都需要某种类型的数据版本化。这些数据版本控制工具可以帮助减少管理数据集所需的存储空间,同时还可以帮助跟踪不同团队成员所做的更改。如果没有数据版本控制工具,您的随叫随到的数据科学家可能会发现自己凌晨3点就起床了。调试模型输出不一致导致的模型问题。
然而,通过确保您的数据科学团队实施数据版本化管理流程,所有这些都可以避免。



