SQLite与文件系统
出于好奇,我对SQLite和文件系统(btrfs)进行了一个小测试。结论是什么?SQLite在现实世界中的加载速度可能更快。
接下来,我提高了并发性,有100个并发作者,每个人写1K条记录。
这并不奇怪,因为SQLite不处理并发写入。老实说,这里的绩效差距比我小';我猜到了。
真实世界的应用程序I';我要写的东西会有更多的结构和索引。所以,我认为下一个测试将是从头到尾运行N个任务:插入、更新状态、更新进度、删除。
为此,我们';我想按身份编制索引,而在现实世界中,我';d可能还通过调度的_进行索引,以便我们能够有效地处理作业调度。如果我用文件系统来做这个,我';d将队列和计划保存在内存中,并在应用程序启动时重新生成。我';我已经测试了记忆中的方法,它';它的速度惊人(每秒数百万次,如果得到适当的护理)。
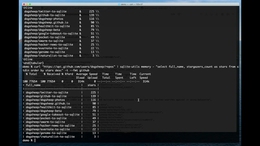
并发性:100,每个运行100个任务的模拟(创建、更改状态、更新和#34;输出和#34;10次,删除):
在这个测试中,文件系统比SQLite快3.3倍。这让我惊讶,因为我们';每次都重新编写整个文件,而SQLite可能能够进行更优化的就地更新(尽管各种各样的事情可能意味着';实际上并没有发生)。
需要注意的是,SQLite的结果有相当多的变化,而且似乎随着时间的推移变得更快。
让';让我们再试一次。这一次,我们';我将进行正确的文件写入(写入tmp文件,重命名以覆盖当前文件)。这应该有点抗崩溃,不过对于我的用例来说,它可能没有';如果一年中有一两次任务因为崩溃而失败,这一点都不重要。
有趣的这一次,我修改了我的文件模拟,先写入tmp文件,然后重命名它以覆盖现有文件。此调整导致文件模拟比SQLite稍慢:
这让我觉得我最初的文件测试可能不是';t等待fsync,但重命名会强制应用程序等待。我';我不确定。
SQLite运行10k任务10.83936393Sqlite运行10k任务10.27817409Sqlite运行10k任务8.891015857Sqlite运行10k任务6.528546715Sqlite运行10k任务6.738008705Sqlite运行10k任务6.917476809s
它似乎有一个热身阶段什么的。我的猜测是,它会随着时间的推移优化查询,并且/或者在重复一段时间后缓存执行计划。
真臭。我想我';我将在这里为SQLite提供优势,因为它将被托管在一个长期运行的进程中,并且可能最终在这些范围的更快端执行。
在我的真实世界场景中,SQLite——一旦预热——的速度大约是文件系统的两倍。
我';我不确定我是哪个';我的玩具项目最终会和你一起去,但我认为它';我是SQLite。我的devops部分稍微偏爱使用文件系统,因为我可以使用基本工具(grep、ls等)来检查东西。我的开发部分绝对支持SQLite,因为我可以让它为我处理大量的事情,我';否则我必须自己做,我可以轻松地查询统计数据等。
在另一个项目中,我对Postgres进行了测试,发现其性能与SQLite'大致相同;当Postgres托管在同一台计算机上时,它的性能最差。