运动事件的冷酷现实
这个假期,给您的非技术朋友和家人一个礼物,让他们最终了解您的生活。朗读云适用于所有年龄段,并且现在在Amazon享有20%的折扣!
我的宠物爱好之一是收集复杂系统的示例,人们花费大量时间来使自己对独立错误产生抵抗力,但这些错误却被没有人看到的系统错误所压倒。
与随机的,孤立的故障相反,系统性错误是会感染并歪曲系统各个方面的错误。在实验室中,这可能是设备本身的校准错误,使所有观察都无用。
在实验室之外,系统错误可能意味着生与死之间的差异,有时甚至是字面上的差异。泰坦尼克号的船体包括16个“水密”舱室,这些舱室应能封堵漏洞,防止个别故障扩散。这就是造船厂吹嘘泰坦尼克号不沉的原因。相反,系统设计错误使水从一个隔间溢出到另一个隔间。冰山一撞到船体的一部分时,整个船就注定了。
或进行选举预测。 2016年,几乎每项民意调查都预示了希拉里·克林顿(Hillary Clinton)的压倒性胜利。但是事实证明,民意测验员系统地低估了关键州对唐纳德·特朗普的热情-也许是由于特朗普选民的害羞或行业偏见,没人真正知道。如果他们知道,那么也许每个民意调查都不会犯同样的错误。但是他们做到了。四年后,没有人再信任选举建模行业了。
那把我们带到星期三。 us-east-1中的几项AWS服务因一天的感恩节休息而来,原因是此后在我家附近被称为Kinesis事件-如果Clive Cussler写了关于ulimit的惊悚片,这听起来像是一本机场书店的小说。
请阅读AWS全面的死后详尽解释,但请快速总结:在周三下午,AWS向Kinesis Data Streams控制平面推出了一些新功能,这违反了操作系统线程限制;由于KDS的这一部分架构不足以实现高可用性,因此它崩溃了很长时间并且需要很长时间才能恢复。同时,其他几项依赖于Kinesis的AWS服务也进行了不同温度和持续时间的沐浴。
在整个漫长的周末中,AWS Twitter上不断涌动着许多热门话题,就像在2017年S3发生严重故障之后一样。根据您听的对象,Kinesis事件是…
关于操作系统配置的道德故事! (我是说,当然,但这不是有趣的部分。)
多云的另一个论点! (不是的,在工作负载级别的多云仍然是昂贵的废话;请参阅先前的Cloud Unregular,以获取何时在组织级别使用多云的解释。)
建立多区域应用程序的争论! (从表面上看,这听起来更合理,但可能并非如此。多区域架构-我已经建造了一些!-价格昂贵,有很多活动部件,并且几乎限制了多云的服务选择。区域是多云的令人毛骨悚然的小弟弟。除非必须,否则请不要照看。
* AWS内部服务架构*是多区域的论点! (我不知道这将如何在合规性方面发挥作用。我认为这只会使一切变得更糟,更古怪,并使每个人更加困惑。)
忘了热门。这是一个冷酷的现实:Kinesis事件不是一个独立的,随机错误的故事。这不是一次性的事件,我们可以通过配置更新或架构选择来抛弃我们。
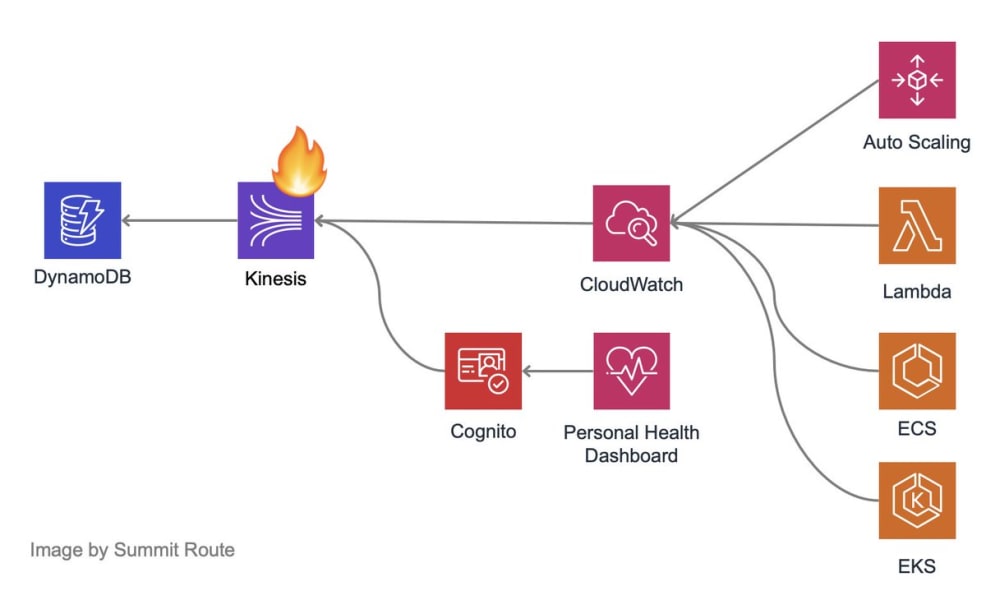
在读过AWS验尸报告后,Scott Piper试图绘制出上周受影响服务的内部依赖关系树:
Scott的推文中的图形实际上低估了该问题-例如,没有Kinesis也就意味着没有AWS IoT,这反过来对Ben Kehoe和他的无服务器Roombas军来说是一个糟糕的夜晚,更不用说门铃和烤箱故障了,谁知道呢? 。
现在,物联网团队已经了解到,他们的工作负载与Kinesis流紧密地交织在一起。但是谁能想到Kinesis故障会消灭AWS Cognito(一项关键但看似无关的服务)呢? Cognito-Kinesis集成发生在后台。 Cognito团队显然使用KDS分析API使用模式。客户没有理由永远不需要知道……直到有人必须解释为什么Kinesis拒绝了Cognito。
但情况变得更糟。根据验尸报告,Cognito团队实际上有一些缓存可以防止Kinesis的消失。在实践中只是效果不佳。因此,这些单独的服务团队正在滚动他们自己的容错系统,以减轻他们可能无法完全理解的上游依赖性带来的意外行为。您想打赌什么?Cognito并不是唯一一个故障保护功能不够完善的服务吗?
(这不是一个随机错误的故事,这是一个系统故障的故事。)
随着新的更高级别服务的出现,AWS内部服务图中的边缘正以几何级数增长,通常直接使用Kinesis,DynamoDB等的核心服务。客户可以清楚地看到这座叠叠塔中的一些砖块,例如物联网的Kinesis白标;其他人将使用内部连接器和中间件,直到下一次中断,这些人和人才看到。
Cognito取决于Kinesis。 AppSync与Cognito集成。毫无疑问,将来的高级服务将在后台使用AppSync。修复一个配置文件,强化一种故障模式并不能支撑整个塔。
唯一的结论是,我们应该期待未来的Kinesis事件,并且我们希望它们的范围逐渐扩大,并且难以解决。
这是什么系统性故障?两人披萨队。 “二比零好。” “越糟越好”的产品策略优先于交付新功能而不是跨功能协作。这些是帮助AWS吃云的原理。它们创建对独立故障具有高度弹性的服务。但是尚不清楚它们是否构成了整个AWS的系统弹性的秘诀。随着时间的流逝,虽然核心服务中的错误发生的可能性越来越小,但建立核心服务中的单个错误将产生滚雪球般的,叠叠式崩溃的可能性。
确实,令人惊讶的是,这些级联中断每周不会发生两次,这证明了AWS整体上杰出的工程学科。
但是,随着新的,更高级别的AWS服务的爆炸式增长(该季节到来了–我们将在re:Invent上再见到几十个),并且依赖图变得更加复杂,更加脆弱,我们应该只期望级联故障会增加。它是系统固有的。
AWS自己的验尸计划不承诺对OS线程的卫生状况保持更高的警惕,但它暗示了正在进行的努力,即“蜂窝化”关键服务以限制爆炸半径。我不完全了解如何避免依赖服务造成的错误假设,并且我敢打赌大量的AWS PM也不这样做。但是是时候与客户建立对确切期望的信任。
我已经要求AWS对他们对自己的服务的内部依赖性进行全面的公开审核,并制定将客户与未使用的服务失败隔离开来的计划。也许一切都很好。也许Kinesis事件只是装甲中的一个漏洞,而且AWS多年来不会再遭受这种程度的中断。但是,现在我还没有理由相信这一点,而且我确定我并不孤单。
关于这一点,re:Invent从星期一开始!已经三个星期了!它是免费的,它是虚拟的,它只是。所以。许多。我将尝试在A Cloud Guru通过电子邮件发送每天的简短执行摘要。确保您关注那里的博客,以获取我,其他AWS Heroes甚至某些特殊的AWS服务团队来宾的大量分析和新功能的深入介绍。我可能还会在其他几个地方弹出。
爱尔兰科技新闻对The Read Aloud Cloud进行了很好的评论。他们承认:“在大多数情况下,押韵是有效的”。我要买它!